This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
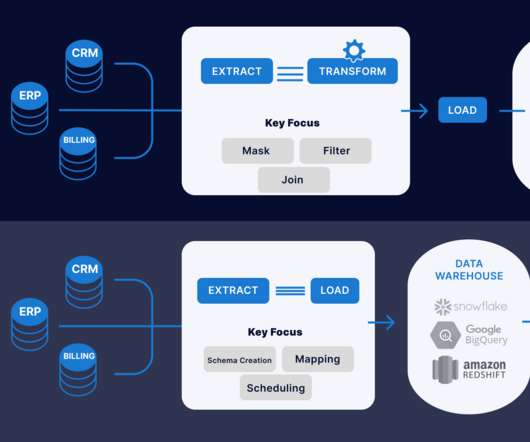
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
30% Off ODSC East, Fan-Favorite Speakers, Foundation Models for Times Series, and ETL Pipeline Orchestration The ODSC East 2025 Schedule isLIVE! Explore the must-attend sessions and cutting-edge tracks designed to equip AI practitioners, data scientists, and engineers with the latest advancements in AI and machine learning.
“Upon release, DBRX outperformed all other leading open models on standard benchmarks and has up to 2x faster inference than models like Llama2-70B,” Everts explains. “It ” Genie: Everts explains this as “a conversational interface for addressing ad-hoc and follow-up questions through natural language.”
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Introduction The ETL process is crucial in modern data management. What is ETL? ETL stands for Extract, Transform, Load.
Operationalisation needs good orchestration to make it work, as Basil Faruqui, director of solutions marketing at BMC , explains. “If CRMs and ERPs had been going the SaaS route for a while, but we started seeing more demands from the operations world for SaaS consumption models,” explains Faruqui.
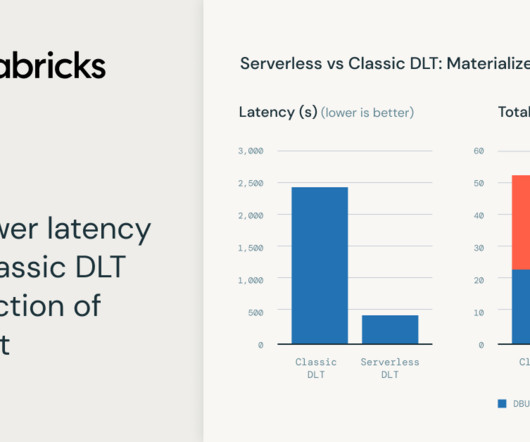
Today, we'd like to explain. We recently announced the general availability of serverless compute for Notebooks, Workflows, and Delta Live Tables (DLT) pipelines.
Additionally, by displaying the potential transformations between several tables, DATALORE’s LLM-based data transformation generation can substantially enhance the return results’ explainability, particularly useful for users interested in any connected table. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup.
In the following sections, we explain how to take an incremental and measured approach to improve Anthropics Claude 3.5 The LLMs performance will depend on how precisely you can explain what you want. The same ETL workflows were running fine before the upgrade. The same ETL workflows were running fine before the upgrade.
An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
“Every company’s business data is their gold mine,” Huang said, explaining that every company has enormous amounts of data, but extracting insights and distilling intelligence from it has been challenging. “Creating these endpoints is complicated,” Huang explained. “We
20222024: As AI models required larger and cleaner datasets, interest in data pipelines, ETL frameworks, and real-time data processing surged. Today, data engineering is a major focal point, with organizations investing in robust ETL (Extract, Transform, Load) pipelines, real-time streaming solutions, and cloud-based data platforms.
We calculate the following information based on the clustering output shown in the following figure: The number of dimensions in PCA that explain 95% of the variance The location of each cluster center, or centroid Additionally, we look at the proportion (higher or lower) of samples in each cluster, as shown in the following figure.
ETL Design Pattern The ETL (Extract, Transform, Load) design pattern is a commonly used pattern in data engineering. ETL Design Pattern Here is an example of how the ETL design pattern can be used in a real-world scenario: A healthcare organization wants to analyze patient data to improve patient outcomes and operational efficiency.
While I don’t focus on data analytics as much as I used to, I still really enjoy math—I think math is beautiful, and will jump at an opportunity to explain the math behind an algorithm. To address this, teams should implement robust ETL (extract, transform, load) pipelines to preprocess, clean, and align time series data.
The concepts will be explained. While traditional data warehouses made use of an Extract-Transform-Load (ETL) process to ingest data, data lakes instead rely on an Extract-Load-Transform (ELT) process. This adds an additional ETL step, making the data even more stale. The concepts and values are overlapping.
Explainability Provides explanations for its predictions through generated text, offering insights into its decision-making process. It can automate extract, transform, and load (ETL) processes, so multiple long-running ETL jobs run in order and complete successfully without manual orchestration.
Can you explain how these components work together to enhance knowledge management? Essentially, it performs ETL (Extract, Transform, Load) on the left side, powering experiences via APIs on the right side. That was the birth of Pryon, the world’s first AI-enhanced knowledge cloud.
Big Data has the ETL (pipelining), Data engineering , Hadoop , Data Warehousing , and Data Mining whereas Data Science has Mathematics, Machine learning, Deep Learning, Computer Vision, NLP, RL, AIOps, Data Reporting, Dashboarding , and all.
We also explained the end-to-end user experience of the SageMaker Unified Studio for two different use cases of notebook and query. She is passionate about helping customers build data lakes using ETL workloads. Delete the domain you created. Delete the VPC named SageMakerUnifiedStudioVPC. Zach Mitchell is a Sr. Big Data Architect.
Explainability – Providing transparency into why certain stories are recommended builds user trust. AWS Glue performs extract, transform, and load (ETL) operations to align the data with the Amazon Personalize datasets schema. Changing interests – Readers’ interests can evolve over time.
To use this feature, you can write rules or analyzers and then turn on anomaly detection in AWS Glue ETL. AWS Glue Data Quality collects statistics for columns specified in rules and analyzers, applies ML algorithms to detect anomalies, and generates visual observations explaining the detected issues.
Used for 🔀 ETL Systems, ⚙️ Data Microservices, and 🌐 Data Collection Key features: 💡Intuitive API: Easy to learn, easy to think about. Chunking Explained Chunking is the process of breaking down a text into smaller, more manageable pieces, that can be used for RAG applications. No time to waste.
As software expert Tim Mangan explains, a purpose-built real-time OS is more suitable for apps that involve tons of data processing. When it comes to data integration, RTOS can work with systems that employ data warehousing, API management, and ETL technologies. Moreover, RTOS is built to be scalable and flexible.
ML model explainability: Make sure the ML model is interpretable and understandable by the developers as well as other stakeholders and that the value addition provided can be easily quantified. .” If you aren’t aware already, let’s introduce the concept of ETL. We primarily used ETL services offered by AWS.
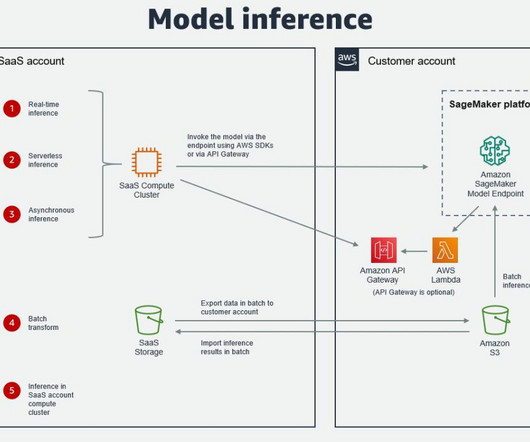
Most of the options explained are also applicable if SageMaker is running in the SaaS AWS account. Alternatively, a service such as AWS Glue or a third-party extract, transform, and load (ETL) tool can be used for data transfer. In some cases, an ISV may deploy their software in the customer AWS account.
Summary : Data Analytics trends like generative AI, edge computing, and Explainable AI redefine insights and decision-making. Explainable AI builds trust by making AI decisions transparent and interpretable for stakeholders. Explainable AI (XAI) is reshaping this narrative by making AI decisions more transparent and interpretable.
Explain the difference between SQL’s SELECT and SELECT DISTINCT statements. Explain the difference between a bar chart and a histogram. Explain the concept of correlation. Explain the difference between supervised and unsupervised learning. Explain the concept of feature selection in machine learning.
Solution overview The following diagram shows the architecture reflecting the workflow operations into AI/ML and ETL (extract, transform, and load) services. Here, a non-deep learning model was trained and run on SageMaker, the details of which will be explained in the following section.
In this post, we explain how TR used Amazon Personalize to build a scalable, multi-tenanted recommender system that provides the best product subscription plans and associated pricing to their customers. The following sections explain the components involved in the solution.
Consider these common scenarios: A perfect validation script cant fix inconsistent data entry practices The most robust ETL pipeline cant resolve disagreements about business rules Real-time quality monitoring cant replace clear data ownership.
Summary: This blog explains how to build efficient data pipelines, detailing each step from data collection to final delivery. This blog explains how to build data pipelines and provides clear steps and best practices. This step often involves: ETL Processes: Extracting, transforming, and loading data into a target system.
Using causal graphs, LIME, Shapley, and the decision tree surrogate approach, the organization also provides various features to make it easier to develop explainability into predictive analytics models. When necessary, the platform also enables numerous governance and explainability elements.
Figure 11 – Model monitor dashboard with selection prompts Figure 12 – Model monitor drift analysis Conclusion The implementation explained in this post enabled Wipro to effectively migrate their on-premises models to AWS and build a scalable, automated model development framework.
You have to make sure that your ETLs are locked down. Then there’s data quality, and then explainability. And last is explainability: the technique to understand the relative importance of features on the prediction. So on the left, you can see, in order to productionize a model, maybe you have to rewrite the model.
You have to make sure that your ETLs are locked down. Then there’s data quality, and then explainability. And last is explainability: the technique to understand the relative importance of features on the prediction. So on the left, you can see, in order to productionize a model, maybe you have to rewrite the model.
You have to make sure that your ETLs are locked down. Then there’s data quality, and then explainability. And last is explainability: the technique to understand the relative importance of features on the prediction. So on the left, you can see, in order to productionize a model, maybe you have to rewrite the model.
In industrial applications of Data Science, model complexity, model explainability, efficiency, and ease of deployment play a large role, even if that means you’re settling for a slightly less accurate model. Model explainability is an important skill for a Data Scientist’s job. This is even more common for first-time baseline models.
They build production-ready systems using best-practice containerisation technologies, ETL tools and APIs. Explainable ML When modelling business process, the why is often more important than the what. Data engineers are the glue that binds the products of data scientists into a coherent and robust data pipeline.
You also learned how to build an Extract Transform Load (ETL) pipeline and discovered the automation capabilities of Apache Airflow for ETL pipelines. Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of data pipelines, including the two major types of existing data pipelines.
There, you can use infographics, custom visualizations, and broader ways to explain your ideas. How to structure Jupyter notebook’s content In this section, I will explain the notebook layout I typically use. Data on its own is not sufficient for a cohesive story. Imports: Library imports and settings.
It explains various architectures such as hierarchical, network, and relational models, highlighting their functionalities and importance in efficient data storage, retrieval, and management. Their expertise is crucial in projects involving data extraction, transformation, and loading (ETL) processes.
It contains native storage for specified schemas, which explains why. IBM Infosphere The good ETL tool IBM Infosphere carries out data integration tasks using graphical notations. Pre-ETL mapping was first used by Analytics pioneer Mike Boggs. Once you’ve loaded data, its built-in search engine makes querying easier.
Ensemble explained: In this context, an ensemble is a group of 2 or more AI models that work together to produce 1 overall prediction. Questions driving the research Can Amazon SageMaker be used to host complex ensembles of AI models that work together to provide one overall prediction?
How does AI Squareds reverse ETL improve AI-driven decision-making? Reverse ETL is a game-changer for AI adoption because it ensures that AI-generated insights do not remain trapped in data warehouses or dashboards but are actively pushed into operational systems where they can drive real-time decision-making.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content