This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
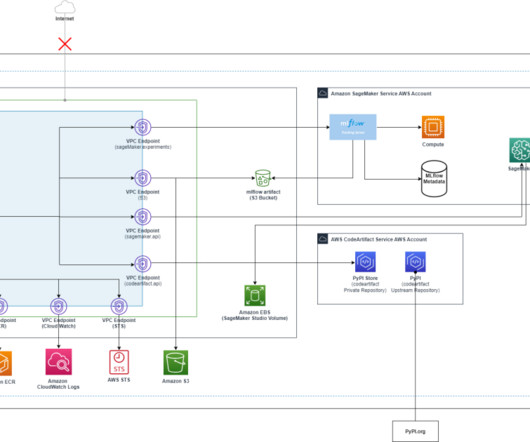
MLflow , a popular open-source tool, helps data scientists organize, track, and analyze ML and generative AI experiments, making it easier to reproduce and compare results. SageMaker is a comprehensive, fully managed ML service designed to provide data scientists and MLengineers with the tools they need to handle the entire ML workflow.
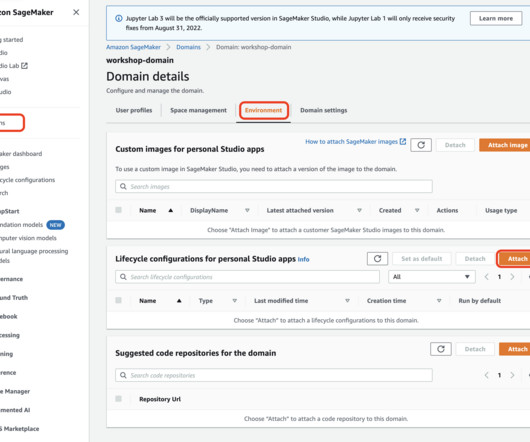
This post presents and compares options and recommended practices on how to manage Python packages and virtual environments in Amazon SageMaker Studio notebooks. Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning (ML) that lets you build, train, debug, deploy, and monitor your ML models.
How to save a trained model in Python? In this section, you will see different ways of saving machine learning (ML) as well as deep learning (DL) models. The first way to save an ML model is by using the pickle file. Saving trained model with pickle The pickle module can be used to serialize and deserialize the Python objects.
Envision yourself as an MLEngineer at one of the world’s largest companies. You make a Machine Learning (ML) pipeline that does everything, from gathering and preparing data to making predictions. This is suitable for making a variety of Python applications with other dependencies being added to it at the user’s convenience.
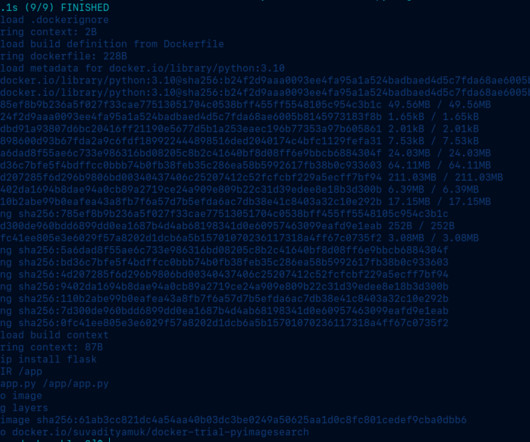
Getting Used to Docker for Machine Learning Introduction Docker is a powerful addition to any development environment, and this especially rings true for MLEngineers or enthusiasts who want to get started with experimentation without having to go through the hassle of setting up several drivers, packages, and more. the image).
Second, open source Metaflow provides the necessary software infrastructure to build production-grade ML/AI systems in a developer-friendly manner. It provides an approachable, robust Python API for the full infrastructure stack of ML/AI, from data and compute to workflows and observability. Choose Create new stack.
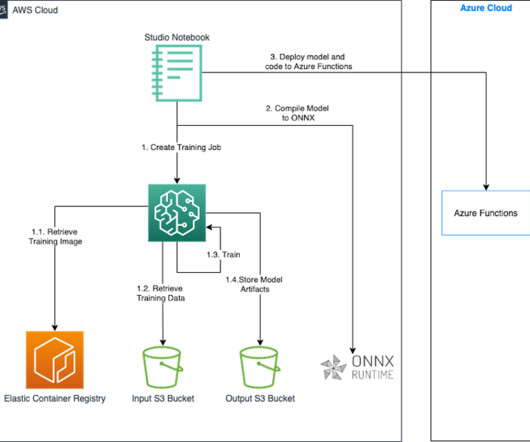
This approach is beneficial if you use AWS services for ML for its most comprehensive set of features, yet you need to run your model in another cloud provider in one of the situations we’ve discussed. Finally, we deploy the ONNX model along with a custom inference code written in Python to Azure Functions using the Azure CLI.
in SageMaker JumpStart SageMaker JumpStart provides FMs through two primary interfaces: SageMaker Studio and the SageMaker Python SDK. SageMaker Studio is a comprehensive IDE that offers a unified, web-based interface for performing all aspects of the machine learning (ML) development lifecycle. Discover Meta SAM 2.1
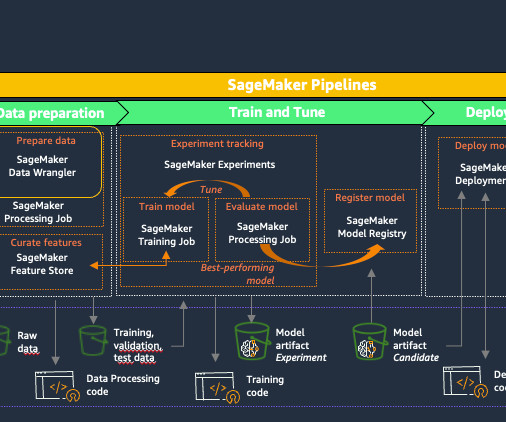
Amazon SageMaker provides purpose-built tools for ML teams to automate and standardize processes across the ML lifecycle. You can use SageMaker Data Wrangler to simplify and streamline dataset preprocessing and feature engineering by either using built-in, no-code transformations or customizing with your own Python scripts.
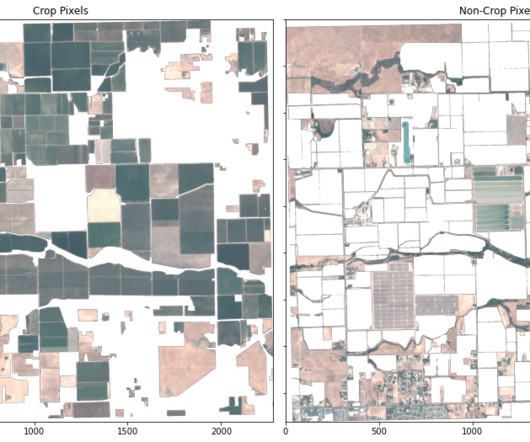
Planet and AWS’s partnership on geospatial ML SageMaker geospatial capabilities empower data scientists and MLengineers to build, train, and deploy models using geospatial data. This example uses the Python client to identify and download imagery needed for the analysis.
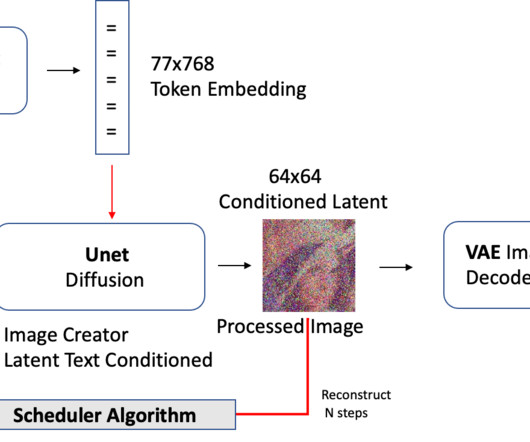
Discover Llama 4 models in SageMaker JumpStart SageMaker JumpStart provides FMs through two primary interfaces: SageMaker Studio and the Amazon SageMaker Python SDK. Alternatively, you can use the SageMaker Python SDK to programmatically access and use SageMaker JumpStart models. b64encode(img).decode('utf-8')
In this post, we show you how to convert Python code that fine-tunes a generative AI model in Amazon Bedrock from local files to a reusable workflow using Amazon SageMaker Pipelines decorators. You can use Amazon SageMaker Model Building Pipelines to collaborate between multiple AI/ML teams. We use Python to do this.
Fine-tuning an LLM can be a complex workflow for data scientists and machine learning (ML) engineers to operationalize. You can create workflows with SageMaker Pipelines that enable you to prepare data, fine-tune models, and evaluate model performance with simple Python code for each step.
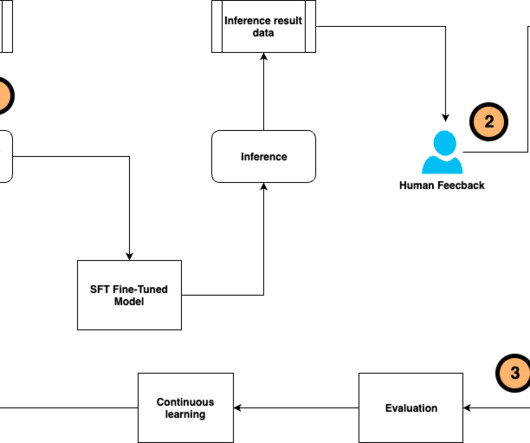
We use DSPy (Declarative Self-improving Python) to demonstrate the workflow of Retrieval Augmented Generation (RAG) optimization, LLM fine-tuning and evaluation, and human preference alignment for performance improvement. Examples are similar to Python dictionaries but with added utilities such as the dspy.Prediction as a return value.
FastAPI is a modern, high-performance web framework for building APIs with Python. It stands out when it comes to developing serverless applications with RESTful microservices and use cases requiring ML inference at scale across multiple industries. The download time can take around 3–5 minutes.
Developing web interfaces to interact with a machine learning (ML) model is a tedious task. With Streamlit , developing demo applications for your ML solution is easy. Streamlit is an open-source Python library that makes it easy to create and share web apps for ML and data science. It also stores the source files (.tar.gz
We’ll see how this architecture applies to different classes of ML systems, discuss MLOps and testing aspects, and look at some example implementations. Understanding machine learning pipelines Machine learning (ML) pipelines are a key component of ML systems. But what is an ML pipeline?
In this post, we walk you through deploying a Falcon large language model (LLM) using Amazon SageMaker JumpStart and using the model to summarize long documents with LangChain and Python. SageMaker is a HIPAA-eligible managed service that provides tools that enable data scientists, MLengineers, and business analysts to innovate with ML.
models in SageMaker JumpStart SageMaker JumpStart provides FMs through two primary interfaces: SageMaker Studio and the SageMaker Python SDK. SageMaker Studio is a comprehensive IDE that offers a unified, web-based interface for performing all aspects of the ML development lifecycle. Discover Llama 3.2 Deploy Llama 3.2
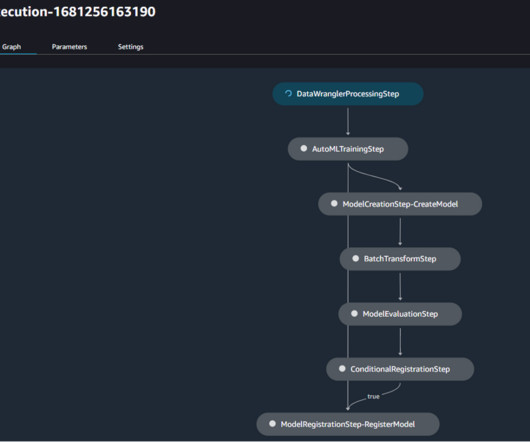
Data scientists and machine learning (ML) engineers use pipelines for tasks such as continuous fine-tuning of large language models (LLMs) and scheduled notebook job workflows. Download the pipeline definition as a JSON file to your local environment by choosing Export at the bottom of the visual editor.
Set up the SDK for Python (Boto3). medium instance with the Python 3 (Data Science) kernel. You can download the datasets and store them in Amazon Simple Storage Service (Amazon S3). About the Authors Sanjeeb Panda is a Data and MLengineer at Amazon. Install the AWS Command Line Interface (AWS CLI).
medium instance with a Python 3 (ipykernel) kernel. SageMaker AI starts and manages all the necessary Amazon Elastic Compute Cloud (Amazon EC2) instances for us, supplies the appropriate containers, downloads data from our S3 bucket to the container and uploads and runs the specified training script, in our case fine_tune_llm.py.
TL;DR This series explain how to implement intermediate MLOps with simple python code, without introducing MLOps frameworks (MLflow, DVC …). As an MLengineer you’re in charge of some code/model. Python has different flavors, and some freedom about the location of scripts and components. Replace MLOps with program .Source
. 🛠 ML Work Your most recent project is Sematic, which focuses on enabling Python-based orchestration of ML pipelines. At Cruise, we noticed a wide gap between the complexity of cloud infrastructure, and the needs of the ML workforce. Could you please tell us about the vision and inspiration behind this project?
Because we used only the radiology report text data, we downloaded just one compressed report file (mimic-cxr-reports.zip) from the MIMIC-CXR website. He has two graduate degrees in physics and a doctorate in engineering. Srushti Kotak is an Associate Data and MLEngineer at AWS Professional Services.
You can download the generated images directly from the UI or check the image in your S3 bucket. About the Authors Akarsha Sehwag is a Data Scientist and MLEngineer in AWS Professional Services with over 5 years of experience building ML based solutions.
ML operations, known as MLOps, focus on streamlining, automating, and monitoring ML models throughout their lifecycle. Data scientists, MLengineers, IT staff, and DevOps teams must work together to operationalize models from research to deployment and maintenance. Download the template.yml file to your computer.
By demonstrating the process of deploying fine-tuned models, we aim to empower data scientists, MLengineers, and application developers to harness the full potential of FMs while addressing unique application requirements. You can apply tags to models and import jobs to keep track of different projects and versions.
There’s a misconception in the world of machine learning (ML). Developers have been led to believe that, to build and train an ML model, they are restricted to using a select few programming languages. Python and Java often top the list. But times are changing — as are the dynamics of MLengineering. And in Node.js
Throughout this exercise, you use Amazon Q Developer in SageMaker Studio for various stages of the development lifecycle and experience firsthand how this natural language assistant can help even the most experienced data scientists or MLengineers streamline the development process and accelerate time-to-value.
We also have plenty of slides from the virtual side of ODSC West that you can see and download here. You can check out the top session recordings here if you have a subscription to the Ai+ Training platform.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc.,
Prerequisites To follow along with this tutorial, make sure you: Use a Google Colab Notebook to follow along Install these Python packages using pip: CometML , PyTorch, TorchVision, Torchmetrics and Numpy, Kaggle %pip install - upgrade comet_ml>=3.10.0 !pip To download it, you will use the Kaggle package.
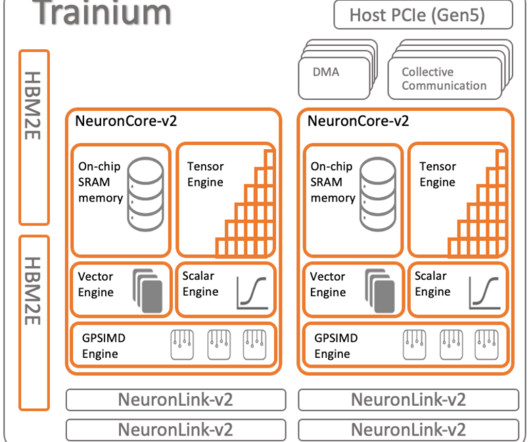
Note all necessary software, drivers, and tools have already been installed on the DLAMIs, and only the activation of the Python environment is needed to start working with the tutorial. Download the sample code from the GitHub repository. We reference the CustomOps functionality available in Neuron as “Neuron CustomOps.”
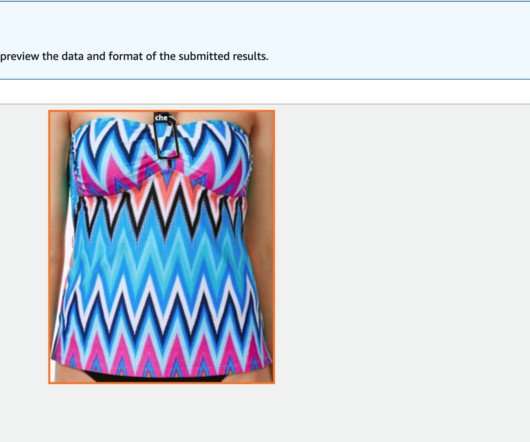
Solution overview Ground Truth is a fully self-served and managed data labeling service that empowers data scientists, machine learning (ML) engineers, and researchers to build high-quality datasets. For our example use case, we work with the Fashion200K dataset , released at ICCV 2017.
Download and save the publicly available UCI Mammography Mass dataset to the S3 bucket you created earlier in the dev account. She is passionate about developing, deploying, and explaining AI/ ML solutions across various domains. Set up an S3 bucket to maintain the Terraform state in the prod account.
By directly integrating with Amazon Managed Service for Prometheus and Amazon Managed Grafana and abstracting the management of hardware failures and job resumption, SageMaker HyperPod allows data scientists and MLengineers to focus on model development rather than infrastructure management. test_cases/10.FSDP create_conda_env.sh
We will be writing code in Python, but DataRobot Notebooks also supports R if that’s your preferred language. For this experiment, we are going to ingest the hospital readmissions data from a CSV file downloaded to the notebook’s working directory using a shell command. Seamless DataRobot API Integration for Hassle-free Workflows.
Machine learning (ML) engineers can fine-tune and deploy text-to-semantic-segmentation and in-painting models based on pre-trained CLIPSeq and Stable Diffusion with Amazon SageMaker. We began by having the user upload a fashion image, followed by downloading and extracting the pre-trained model from CLIPSeq.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and MLEngineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
AWS Glue consists of a metadata repository known as Glue catalog, an engine to generate the Scala or Python code for the ETL Job, and also does job monitoring, scheduling, and so on. For an experienced Data Scientist/MLengineer, that shouldn’t come as so much of a problem. Redshift, S3, and so on.
You can integrate a Data Wrangler data preparation flow into your ML workflows to simplify and streamline data preprocessing and feature engineering using little to no coding. You can also add your own Python scripts and transformations to customize workflows. Python code file. Choose the file browser icon view the path.
Container Caching addresses this scaling challenge by pre-caching the container image, eliminating the need to download it when scaling up. We discuss how this innovation significantly reduces container download and load times during scaling events, a major bottleneck in LLM and generative AI inference.
Download the notebook file to use in this post. data # Assing local directory path to a python variable local_data_path = "./data/" data/" # Assign S3 bucket name to a python variable. Ginni Malik is a Senior Data & MLEngineer with AWS Professional Services. Run the SageMaker Studio application.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content