This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
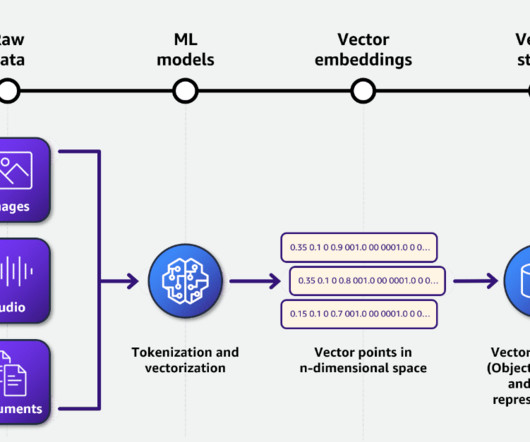
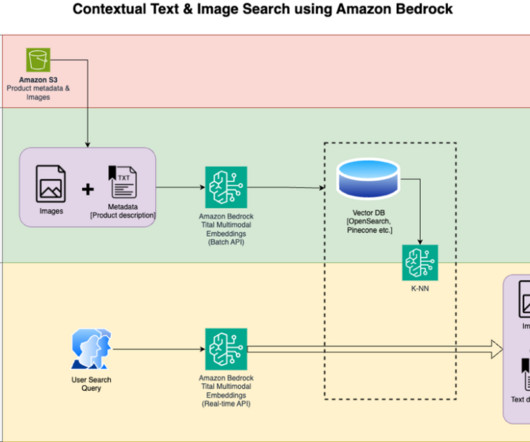
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
If you're looking to implement Automatic Speech Recognition (ASR) in Python, you may have noticed that there is a wide array of available options. Broadly, Python speech recognition and Speech-to-Text solutions can be categorized into two main types: open-source libraries and cloud-based services. What is Speech Recognition?
Jump Right To The Downloads Section What Is Gradio and Why Is It Ideal for Chatbots? Gradio is an open-source Python library that enables developers to create user-friendly and interactive web applications effortlessly. Model Management: Easily download, run, and manage various models, including Llama 3.2
Database metadata can be expressed in various formats, including schema.org and DCAT. ML data has unique requirements, like combining and extracting data from structured and unstructured sources, having metadata allowing for responsible data use, or describing ML usage characteristics like training, test, and validation sets.
source env_vars After setting your environment variables, download the lifecycle scripts required for bootstrapping the compute nodes on your SageMaker HyperPod cluster and define its configuration settings before uploading the scripts to your S3 bucket. The following is the bash script for the Python environment setup. get_model.sh.
Streamlit is an open source framework for data scientists to efficiently create interactive web-based data applications in pure Python. Install Python 3.7 structured: | Process the pdf invoice and list all metadata and values in json format for the variables with descriptions in tags. or later on your local machine.
On the other hand, a Node is a snippet or “chunk” from a Document, enriched with metadata and relationships to other nodes, ensuring a robust foundation for precise data retrieval later on. Behind the scenes, it dissects raw documents into intermediate representations, computes vector embeddings, and deduces metadata.
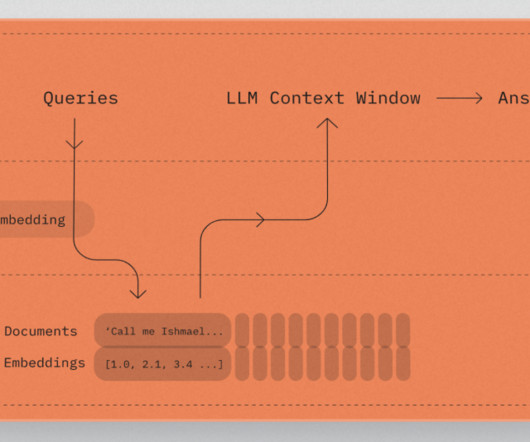
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. Streamlit This open source Python library makes it straightforward to create and share beautiful, custom web apps for ML and data science. The following diagram illustrates the RAG framework.
How to save a trained model in Python? Saving trained model with pickle The pickle module can be used to serialize and deserialize the Python objects. For saving the ML models used as a pickle file, you need to use the Pickle module that already comes with the default Python installation. Now let’s see how we can save our model.
Chroma can be used to create word embeddings using Python or JavaScript programming. Each referenced string can have extra metadata that describes the original document. Researchers fabricated some metadata to use in the tutorial. Metadata (or IDs) can also be queried in the Chroma database.
In this post, we show you how to convert Python code that fine-tunes a generative AI model in Amazon Bedrock from local files to a reusable workflow using Amazon SageMaker Pipelines decorators. It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions.
Download the model and its components WhisperX is a system that includes multiple models for transcription, forced alignment, and diarization. For smooth SageMaker operation without the need to fetch model artifacts during inference, it’s essential to pre-download all model artifacts. __dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir":
So, get that out of the way, then start installing some packages: conda create -n p_rag python==3.10 Once that’s done, activate your environment: conda activate p_rag Install Dependencies To interact with Qdrant using the Python sdk, you’ll need to install the Qdrant client library. pip install python-dotenv==1.0.1 openai==1.23.6
Step 1: Create a Slack Bot The first step is to set up a bot in Slack for that please follow steps 1 to 23 in our blog post Slack Bot with Python. Let's get started! " # download the pdf download_pdf(file_url, file_name) print("nuser_idn",user_id) # function use to make chunks of pdf and added into chromadb.
The Amazon SageMaker Studio notebook with geospatial image comes pre-installed with commonly used geospatial libraries such as GDAL, Fiona, GeoPandas, Shapely, and Rasterio, which allow the visualization and processing of geospatial data directly within a Python notebook environment.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Third, despite the larger adoption of centralized analytics solutions like data lakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources.
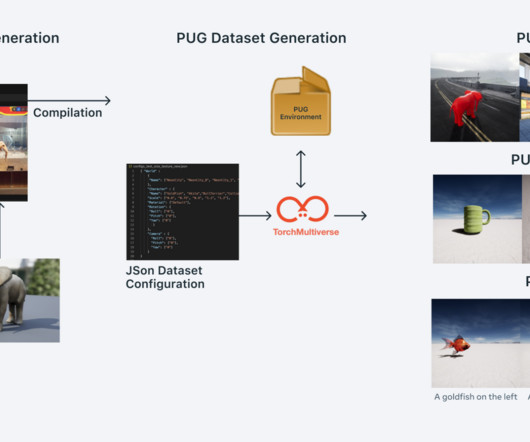
Most publicly available image databases are difficult to edit beyond crude image augmentations and lack fine-grained metadata. However, it is difficult to get such information due to concerns over privacy, bias, and copyright infringement.
The implementation is primarily written in C (2000 lines) with Python wrappers (4000 lines), utilizing the Zstd v1.5.6 The method has the potential to save an ExaByte of network traffic monthly from large model distribution platforms like Hugging Face. library and its Huffman implementation.
Prerequisite libraries: SageMaker Python SDK, Pinecone Client Solution Walkthrough Using SageMaker Studio notebook, we first need install prerequisite libraries: !pip Download the Amazon SageMaker FAQs When performing the search, look for Answers only, so you can drop the Question column. Onboard to an Amazon SageMaker Domain.
LangChain is a Python library designed to build applications with LLMs. Python 3.10 GPU Optimized image, Python 3 kernel, and ml.t3.medium To set up the development environment, you need to install the necessary Python libraries, as demonstrated in the following code. medium as the instance type.
A purpose-built time series database, on the other hand, can easily maintain this type of metadata in the form of tags or labels associated with each time series. Most importantly, you can get started with TDengine in only 60 seconds, and its open-source edition is free to download and use.
Data and AI governance Publish your data products to the catalog with glossaries and metadata forms. With SageMaker Unified Studio notebooks, you can use Python or Spark to interactively explore and visualize data, prepare data for analytics and ML, and train ML models. Choose the plus sign and for Notebook , choose Python 3.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you render audio/video?
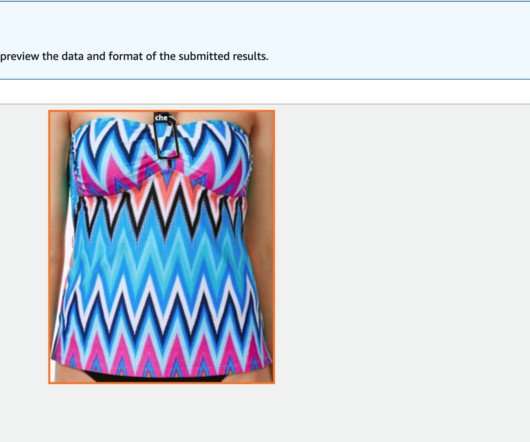
Data overview and preparation You can use a SageMaker Studio notebook with a Python 3 (Data Science) kernel to run the sample code. The dataset is a collection of 147,702 product listings with multilingual metadata and 398,212 unique catalogue images. We use the first metadata file in this demo. images/metadata/images.csv.gz
Discover Llama 4 models in SageMaker JumpStart SageMaker JumpStart provides FMs through two primary interfaces: SageMaker Studio and the Amazon SageMaker Python SDK. Alternatively, you can use the SageMaker Python SDK to programmatically access and use SageMaker JumpStart models. b64encode(img).decode('utf-8')
A feature store typically comprises a feature repository, a feature serving layer, and a metadata store. The metadata store manages the metadata associated with each feature, such as its origin and transformations. The feature repository is essentially a database storing pre-computed and versioned features.
TL;DR Structuring Python projects is very important for proper internal working, as well as for distribution to other users in the form of packages. There are two main general structures: the flat layout vs the src layout as clearly explained in the official Python packaging guide here. Package your project source code folder.
You can create workflows with SageMaker Pipelines that enable you to prepare data, fine-tune models, and evaluate model performance with simple Python code for each step. You also need to add the mlflow and sagemaker-mlflow Python packages as dependencies in the pipeline setup.
We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. In this post, we illustrate how to handle OOC by utilizing the power of the IMDb dataset (the premier source of global entertainment metadata) and knowledge graphs. Creates an OpenSearch Service domain for the search application.
Jump Right To The Downloads Section People Counter on OAK Introduction People counting is a cutting-edge application within computer vision, focusing on accurately determining the number of individuals in a particular area or moving in specific directions, such as “entering” or “exiting.” Looking for the source code to this post?
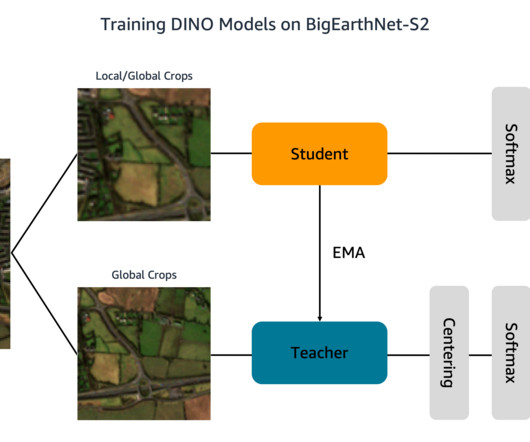
We start by downloading the dataset from the terminal of our SageMaker notebook instance: wget [link] tar -xvf BigEarthNet-S2-v1.0.tar.gz Additionally, each folder contains a JSON file with the image metadata. We store the BigEarthNet-S2 images and metadata file in an S3 bucket. The dataset has a size of about 109 GB.
Each dataset group can have up to three datasets, one of each dataset type: target time series (TTS), related time series (RTS), and item metadata. You can implement this workflow in Forecast either from the AWS Management Console , the AWS Command Line Interface (AWS CLI), via API calls using Python notebooks , or via automation solutions.
Hey guys in this video we will see the best Python Interview Questions. Python has become one of the most popular programming languages in the world, thanks to its simplicity, versatility, and vast array of applications. As a result, Python proficiency has become a valuable skill sought after by employers across various industries.
In this post, we’re going to show you how to transcribe your Zoom recordings by connecting Zoom’s API with AssemblyAI’s automatic speech recognition API in Python. lives, and then add this code to your zoom.py authorized_url = download_url + "?access_token="
Bonus Hugging Face has multiple Python libraries under its umbrella: datasets , transformers , evaluate , and accelerate , just to name a few! Note: Downloading the dataset takes 1.2 Now, let’s download the dataset from the ? Calling this function will download the dataset and return an iterable DatasetDict object.
x, there is no need to download it separately. You do not need to download the JupyterLab celltags extension separately because it is officially included with JupyterLab 3.x. JupyterLab Matplotlib If you’re a data scientist, Matplotlib is a Python library you absolutely must master.
In the following sections, we discuss how to satisfy the prerequisites, download the code, and use the Jupyter notebook in the GitHub repository to deploy the automated solution using an Amazon SageMaker Studio environment. Download the code to your SageMaker Studio environment Run the following commands from the terminal.
Jupyter notebooks can differentiate between SQL and Python code using the %%sm_sql magic command, which must be placed at the top of any cell that contains SQL code. This command signals to JupyterLab that the following instructions are SQL commands rather than Python code.
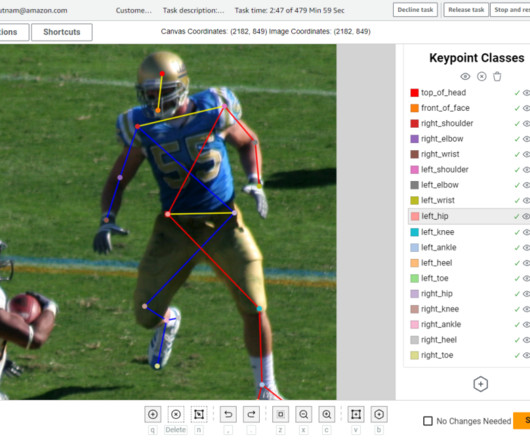
This input manifest file contains metadata for a labeling job, acts as a reference to the data that needs to be labeled, and helps configure how the data should be presented to the annotators. Set up your resources Complete the following steps to set up your resources: Download the example stack from the GitHub repo. for more details).
The following are the solution workflow steps: Download the product description text and images from the public Amazon Simple Storage Service (Amazon S3) bucket. Run the solution Open the file titan_mm_embed_search_blog.ipynb and use the Data Science Python 3 kernel. You then display the top similar results.
The model registry maintains records of model versions, their associated artifacts, lineage, and metadata. Model registry – This monitors the various versions of the model and the corresponding artifacts, which includes lineage and metadata. Download the template.yml file to your computer. Upload the template you downloaded.
Download the data locally First, download the women.tar zip file and the labels folder (with all of its subfolders) following the instructions provided in the Fashion200K dataset GitHub repository. Your goal is to turn this existing dataset into a robust training dataset for your clothing classification models.
You also need a NAT gateway internet access, such that Trn1 compute nodes can download AWS Neuron packages. After the training data and scripts are downloaded to the cluster, we use the Slurm controller to manage and orchestrate our workload. We submit the training job with the sbatch command.
. 🛠 ML Work Your most recent project is Sematic, which focuses on enabling Python-based orchestration of ML pipelines. ML Engineers want to focus on writing Python logic, and visualizing the impact of their changes quickly. Could you please tell us about the vision and inspiration behind this project?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content