This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
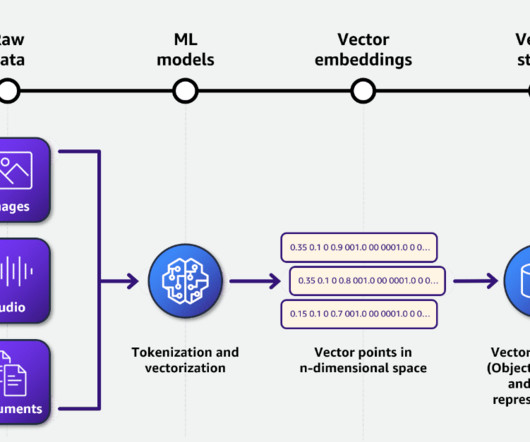
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. Generate metadata for the page. Generate metadata for the full document. Upload the content and metadata to Amazon S3.
To refine the search results, you can filter based on document metadata to improve retrieval accuracy, which in turn leads to more relevant FM generations aligned with your interests. With this feature, you can now supply a custom metadata file (each up to 10 KB) for each document in the knowledge base. Virginia) and US West (Oregon).
Database metadata can be expressed in various formats, including schema.org and DCAT. ML data has unique requirements, like combining and extracting data from structured and unstructured sources, having metadata allowing for responsible data use, or describing ML usage characteristics like training, test, and validation sets.
Alibaba Cloud’s open-source AI models gain traction Since its debut in April 2023, the Qwen model series has garnered significant traction, surpassing 40 million downloads across platforms such as Hugging Face and ModelScope. DMS: OneMeta+OneOps, a platform for unified management of metadata across multiple cloud environments.
You can download this data as a PDF from Wikipedia using the Tools menu. Metadata boosting To improve the accuracy of responses from Amazon Q Business application with CSV files, you can add metadata to documents in an S3 bucket by using a metadata file. About the author Jiten Dedhia is a Sr.
A JSON metadata file for each document containing additional information to customize chat results for end-users and apply boosting techniques to enhance user experience (which we discuss more in the next section). For the metadata file used in this example, we focus on boosting two key metadata attributes: _document_title and services.
To upload the dataset Download the dataset : Go to the Shoe Dataset page on Kaggle.com and download the dataset file (350.79MB) that contains the images. To tag each embedding with the image file name, you must also add a mapping field under Metadata management. client('s3') bedrock_client = boto3.client( Engine : Select nmslib.
This archive includes over 24 million image-text pairs from 6 million articles enriched with metadata and expert annotations. Articles and media files are downloaded from the NCBI server, extracting metadata, captions, and figure references from nXML files and the Entrez API.
Jump Right To The Downloads Section What Is Gradio and Why Is It Ideal for Chatbots? Model Management: Easily download, run, and manage various models, including Llama 3.2 Default Model Storage Location By default, Ollama stores all downloaded models in the ~/.ollama/models and the Ollama API, just keep reading.
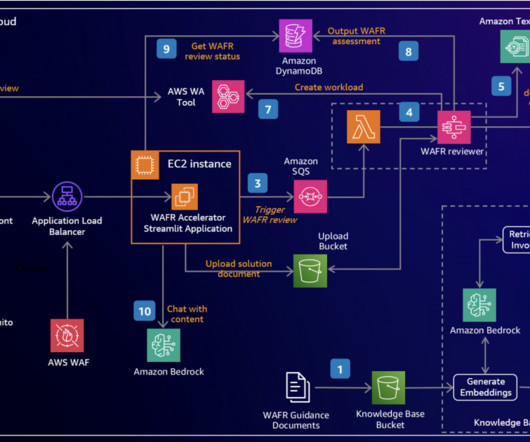
Metadata filtering is used to improve retrieval accuracy. This allows users to download initial version of the AWS Well-Architected report from the AWS Well-Architected Tool console on completion of the assessment. A workload is created in the AWS Well-Architected Tool with answers populated with the assessment results.
source env_vars After setting your environment variables, download the lifecycle scripts required for bootstrapping the compute nodes on your SageMaker HyperPod cluster and define its configuration settings before uploading the scripts to your S3 bucket. script to download the model and tokenizer. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
The connector supports the crawling of the following entities in Gmail: Email – Each email is considered a single document Attachment – Each email attachment is considered a single document Additionally, supported custom metadata and custom objects are also crawled during the sync process. On the Keys tab, choose Add key and Create new key.
Additionally, the metadata of SeamlessAlign – the largest multimodal translation dataset ever compiled, consisting of 270,000 hours of mined speech and text alignments – has been released. The code, model, and data can be downloaded on GitHub. license, embodying an ethos of open science. A demo of SeamlessM4T can be found here.
Download the Gartner® Market Guide for Active Metadata Management 1. We bring intelligence to metadata management by providing an automated solution that helps you drive productivity, gain trust in your data, and accelerate digital transformation. The answer is data lineage.
On the other hand, a Node is a snippet or “chunk” from a Document, enriched with metadata and relationships to other nodes, ensuring a robust foundation for precise data retrieval later on. Behind the scenes, it dissects raw documents into intermediate representations, computes vector embeddings, and deduces metadata.
Its toolkit automates risk management, monitors models for bias and drift, captures model metadata and facilitates collaborative, organization-wide compliance. IBM watsonx.governance ™, a component of the watsonx™ platform that will be available on December 5 th , helps organizations monitor and govern the entire AI lifecycle.
structured: | Process the pdf invoice and list all metadata and values in json format for the variables with descriptions in tags. Returns: Tuple[S3Client, BedrockRuntimeClient] """ return ( boto3.client('s3', client('s3', region_name=CONFIG['aws']['region_name']), boto3.client(service_name='bedrock-agent-runtime', Defaults to "". endswith('.pdf'):
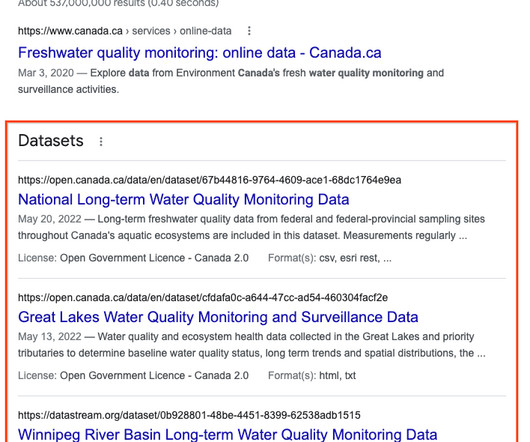
Dataset Search shows users essential metadata about datasets and previews of the data where available. The schema.org metadata allows Web page authors to describe the semantics of the page: the entities on the pages and their properties. Specifically, ensure that the Web page that describes the dataset has machine-readable metadata.
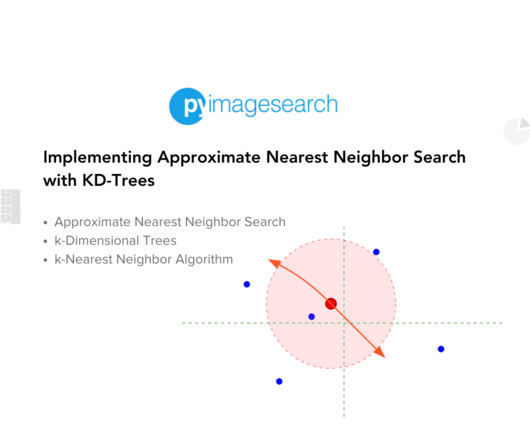
Jump Right To The Downloads Section Introduction to Approximate Nearest Neighbor Search In high-dimensional data, finding the nearest neighbors efficiently is a crucial task for various applications, including recommendation systems, image retrieval, and machine learning. product specifications, movie metadata, documents, etc.)
This robust metadata collection enriches the dataset’s potential, making it ideal for various applications, from pre-training large models to fine-tuning specialized video-processing tasks. FineVideo’s rich metadata facilitates the development of AI models that can answer such questions with context-aware precision.
Download the model and its components WhisperX is a system that includes multiple models for transcription, forced alignment, and diarization. For smooth SageMaker operation without the need to fetch model artifacts during inference, it’s essential to pre-download all model artifacts. in a code subdirectory. in a code subdirectory.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. When the user provides the input through the chat prompt, we use similarity search to find the relevant table metadata from the vector database for the users query. streamlit run app.py
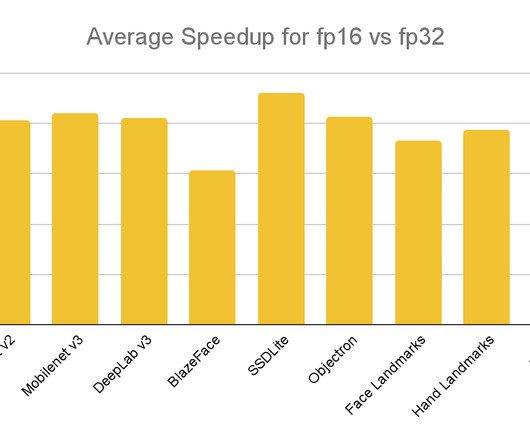
To benefit from the half-precision inference in XNNPack, the user must provide a floating-point (FP32) model with FP16 weights and special "reduced_precision_support" metadata to indicate model compatibility with FP16 inference. Additionally, the XNNPack delegate provides an option to force FP16 inference regardless of the model metadata.
With CLIP support in ChatRTX, users can interact with photos and images on their local devices through words, terms and phrases, without the need for complex metadata labeling. Download ChatRTX today. The new ChatRTX release also lets people chat with their data using their voice.
To install and use DeepSpeech you can use these commands (see documentation ): # Install DeepSpeech pip install deepspeech # Download pre-trained English model files curl -LO [link] curl -LO [link] # Download example audio files curl -LO [link] tar xvf audio-0.9.3.tar.gz models.pbmm --scorer deepspeech-0.9.3-models.scorer
Solution overview The LMA sample solution captures speaker audio and metadata from your browser-based meeting app (as of this writing, Zoom and Chime are supported), or audio only from any other browser-based meeting app, softphone, or audio source. Inventory list of meetings – LMA keeps track of all your meetings in a searchable list.
We start with a simple scenario: you have an audio file stored in Amazon S3, along with some metadata like a call ID and its transcription. Complete the following steps for manual deployment: Download these assets directly from the GitHub repository. The assets (JavaScript and CSS files) are available in our GitHub repository.
Each referenced string can have extra metadata that describes the original document. Researchers fabricated some metadata to use in the tutorial. Each collection includes documents, which are just lists of strings, IDs, which serve as unique identifiers for the documents, and metadata (which is not required).
By downloading individual video datasets, merging them, and reshaping them into more manageable shapes with new features and significantly more samples, researchers have utilized video2dataset to build upon existing video datasets. The dataset can be downloaded in several formats, all consisting of shards with N samples each.
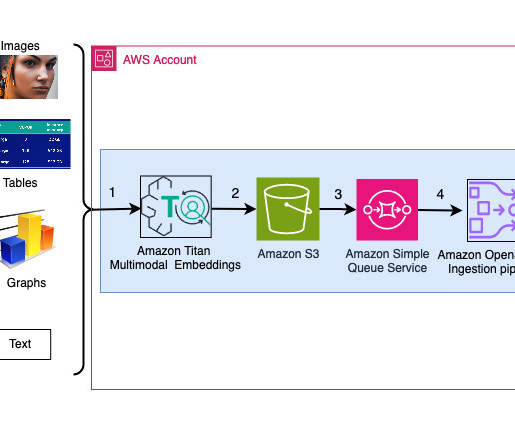
In the previous post, you used Amazon Rekognition to extract metadata from an image. You then used a text embedding model to generate a word embedding of the metadata that could be used later to help find the best images. You use Titan Multimodal Embeddings model to generate an embedding of the image which is also searchable metadata.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Third, despite the larger adoption of centralized analytics solutions like data lakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources.
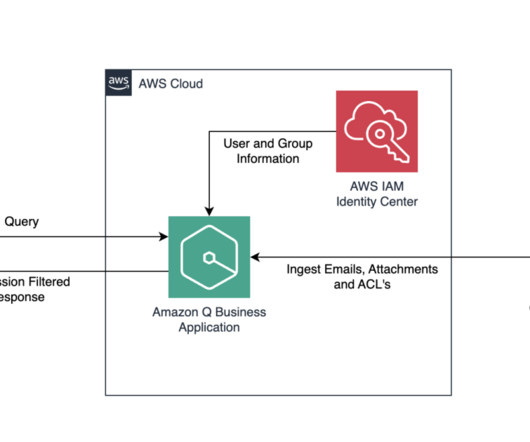
A document is a collection of information that consists of a title, the content (or the body), metadata (data about the document), and access control list (ACL) information to make sure answers are provided from documents that the user has access to. Amazon Q supports the crawling and indexing of these custom objects and custom metadata.
Let's get started! " # download the pdf download_pdf(file_url, file_name) print("nuser_idn",user_id) # function use to make chunks of pdf and added into chromadb. Before chunking the pdf we need to download the pdf for that we have used ‘ download_pdf(file_url, file_name)’ function to add this function to download the pdf file.
We add additional metadata fields to perform rich search queries using OpenSearch’s powerful search capabilities. The metadata of the response from OpenSearch Serverless contains a path to the image and description corresponding to the most relevant slide. The embeddings are ingested into an OSI pipeline using an API call.
It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. Use Python to preprocess, train, and test an LLM in Amazon Bedrock To begin, we need to download data and prepare an LLM in Amazon Bedrock. We use Python to do this.
We add additional metadata fields to these generated vector embeddings and create a JSON file. These additional metadata fields can be used to perform rich search queries using OpenSearch’s powerful search capabilities. In this notebook, we download the LLaVA-v1.5-7B Choose 0_deploy_llava.ipynb to open it in JupyterLab.
OpenUSD allows us to add any attribute or any piece of metadata we want to our applications,” he said. Get started with NVIDIA Omniverse by downloading the standard license free , access OpenUSD resources and learn how Omniverse Enterprise can connect team s. Check out a new video series about how OpenUSD can improve 3D workflows.
Sonnet in the same AWS Region where youll deploy this solution The accompanying AWS CloudFormation template downloaded from the aws-samples GitHub repo. Complete the following steps: Download the front-end code AWS-Amplify-Frontend.zip from GitHub. Use the.zip file to manually deploy the application in Amplify.
Alternatively, update an existing MediaSearch indexer stack to replace the previously indexed files with files from the new location or update the YouTube playlist URL or the number of videos to download from the playlist: Select the stack on the AWS CloudFormation console, choose Update , then Use current template , then Next.
Download the Amazon SageMaker FAQs When performing the search, look for Answers only, so you can drop the Question column. Since we top_k = 1 , index.query returned the top result along side the metadata which reads Managed Spot Training can be used with all instances supported in Amazon.
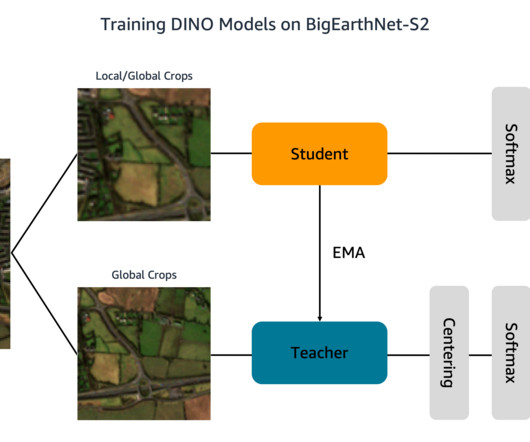
We start by downloading the dataset from the terminal of our SageMaker notebook instance: wget [link] tar -xvf BigEarthNet-S2-v1.0.tar.gz Additionally, each folder contains a JSON file with the image metadata. We store the BigEarthNet-S2 images and metadata file in an S3 bucket. The dataset has a size of about 109 GB.
The coefficients for correcting to at-sensor reflectance are provided in the scene metadata, which further improves the consistency between images taken at different times. This example uses the Python client to identify and download imagery needed for the analysis.
To enhance user experience, the researchers implemented seamless Hugging Face Transformers library integration, enabling automatic model decompression, metadata updates, and local cache management with optional manual compression controls. The compression strategy operates at two granularity levels: chunk level and byte-group level.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content