This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. Generate metadata for the page. Generate metadata for the full document. Upload the content and metadata to Amazon S3.
Database metadata can be expressed in various formats, including schema.org and DCAT. ML data has unique requirements, like combining and extracting data from structured and unstructured sources, having metadata allowing for responsible data use, or describing ML usage characteristics like training, test, and validation sets.
Jump Right To The Downloads Section What Is Gradio and Why Is It Ideal for Chatbots? Model Management: Easily download, run, and manage various models, including Llama 3.2 Default Model Storage Location By default, Ollama stores all downloaded models in the ~/.ollama/models and the Ollama API, just keep reading.
It helps accelerate responsible, transparent and explainable AI workflows. Its toolkit automates risk management, monitors models for bias and drift, captures model metadata and facilitates collaborative, organization-wide compliance.
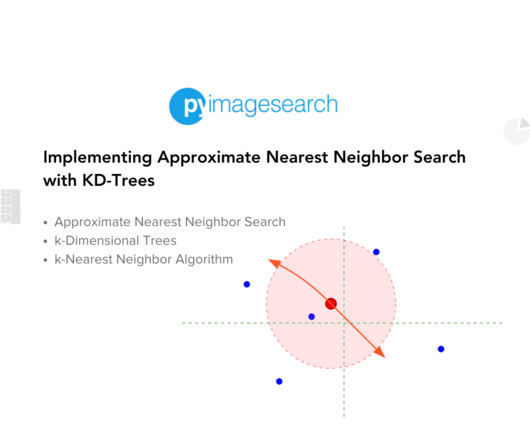
Jump Right To The Downloads Section Introduction to Approximate Nearest Neighbor Search In high-dimensional data, finding the nearest neighbors efficiently is a crucial task for various applications, including recommendation systems, image retrieval, and machine learning. product specifications, movie metadata, documents, etc.)
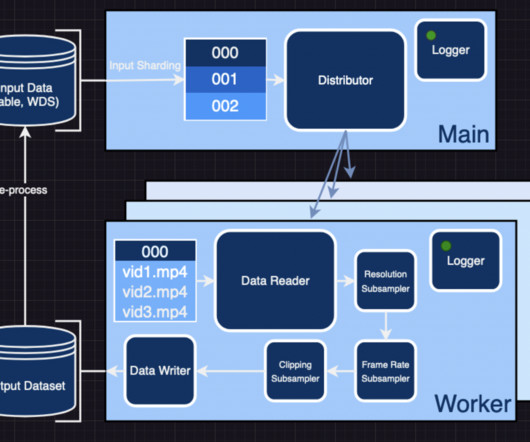
By downloading individual video datasets, merging them, and reshaping them into more manageable shapes with new features and significantly more samples, researchers have utilized video2dataset to build upon existing video datasets. I’ll explain. How does video2dataset work?
Since devices store information every time their user downloads something, visits a website or creates a post, a sort of electronic paper trail exits. Experts can check hard drives, metadata, data packets, network access logs or email exchanges to find, collect, and process information.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Third, despite the larger adoption of centralized analytics solutions like data lakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources.
The Annotated type is used to provide additional metadata about the return value, specifically that it should be included in the response body. The automation workflow will run all the checks. The description parameter provides a brief explanation of what the return value represents.
This includes features for model explainability, fairness assessment, privacy preservation, and compliance tracking. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Is it fast and reliable enough for your workflow?
Download the Amazon SageMaker FAQs When performing the search, look for Answers only, so you can drop the Question column. Since we top_k = 1 , index.query returned the top result along side the metadata which reads Managed Spot Training can be used with all instances supported in Amazon.
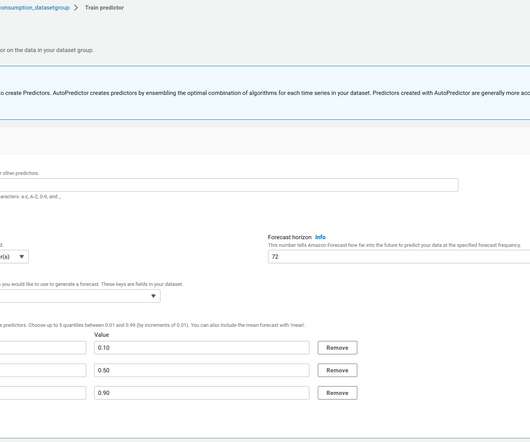
Each dataset group can have up to three datasets, one of each dataset type: target time series (TTS), related time series (RTS), and item metadata. CreateDatasetGroup DatasetIncludeItem Specify if you want to provide item metadata for this use case. These determine if explainability is enabled for your predictor.
It can also be done at scale, as explained in Operationalize LLM Evaluation at Scale using Amazon SageMaker Clarify and MLOps services. By logging your datasets with MLflow, you can store metadata, such as dataset descriptions, version numbers, and data statistics, alongside your MLflow runs.
Note: The focus of this article is not to show you how you can create the best ML model but to explain how effectively you can save trained models. To save the model using ONNX, you need to have onnx and onnxruntime packages downloaded in your system. You can download this library with the help of the Python package installer. $
Data and AI governance Publish your data products to the catalog with glossaries and metadata forms. The generated images can also be downloaded as PNG or JPEG files. We also explained the end-to-end user experience of the SageMaker Unified Studio for two different use cases of notebook and query. Delete the domain you created.
Note: Downloading the dataset takes 1.2 If you don’t want to download the whole dataset, you can simply pass in the streaming=True argument to create an iterable dataset where samples are downloaded as you iterate over them. Now, let’s download the dataset from the ? GB of disk space. labels in the dataset).
The randomization process was adequately explained to patients, and they understood the rationale behind blinding, which is to prevent bias in the results (Transcript 2). You can download a sample file and review the contents. They should be available in Amazon S3 under the prefix hcls-framework/input-text/.
In this post, we use a Hugging Face BERT-Large model pre-training workload as a simple example to explain how to useTrn1 UltraClusters. You also need a NAT gateway internet access, such that Trn1 compute nodes can download AWS Neuron packages. We submit the training job with the sbatch command.
You can use a managed service, such as Amazon Rekognition , to predict product attributes as explained in Automating product description generation with Amazon Bedrock. jpg and the complete metadata from styles/38642.json. Each product is identified by an ID such as 38642, and there is a map to all the products in styles.csv.
Building a tool for managing experiments can help your data scientists; 1 Keep track of experiments across different projects, 2 Save experiment-related metadata, 3 Reproduce and compare results over time, 4 Share results with teammates, 5 Or push experiment outputs to downstream systems.
Once downloaded in your .cache Image from Author Through the get_schema() , as shown in the above image, we can get information about how is set the data and metadata of our DataGrid and also the data types of each of them. cache/ Image from Author I know you may be wondering why the DataGrid is stored in a .arrow
Jump Right To The Downloads Section People Counter on OAK Introduction People counting is a cutting-edge application within computer vision, focusing on accurately determining the number of individuals in a particular area or moving in specific directions, such as “entering” or “exiting.” Looking for the source code to this post?
In this lesson, we will answer this question by explaining the machine learning behind YouTube video recommendations. Noise: The metadata associated with the content doesn’t have a well-defined ontology. All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms.
This architecture is comprised of several key components, each of which we explain in more detail in the following sections. This input manifest file contains metadata for a labeling job, acts as a reference to the data that needs to be labeled, and helps configure how the data should be presented to the annotators. for more details).
The meaning of this term is explained below. In the most generic terms, every project starts with raw data, which comes from observations and measurements i.e. it is directly downloaded from instruments. Register metadata in standardised catalogue (e.g. Not all data is the same. S3 and Zenodo.org). GeoNetwork , STAC).
A what-if analysis helps you investigate and explain how different scenarios might affect the baseline forecast created by Forecast. Download data files from the GitHub repo and upload to the newly created S3 bucket. With Forecast, there are no servers to provision or ML models to build manually.
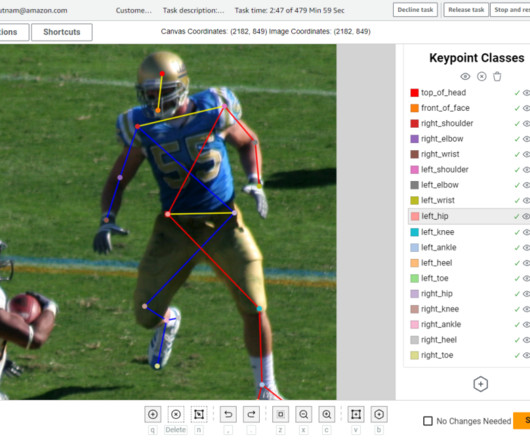
You can download the endzone and sideline videos , and also the ground truth labels. For more information regarding NFL Player Health and Safety, visit the NFL website and NFL Explained: Innovation in Player Health & Safety. def get_video_and_metadata(vid_path): vid = cv2.VideoCapture(vid_path)
Jump Right To The Downloads Section A Deep Dive into Variational Autoencoder with PyTorch Introduction Deep learning has achieved remarkable success in supervised tasks, especially in image recognition. Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images. The config.py
There are two main general structures: the flat layout vs the src layout as clearly explained in the official Python packaging guide here. done Preparing editable metadata (pyproject.toml). This is explained in PEP 517 and PEP 518 , and a solution was recommended with the introduction of setup.cfg and pyproject.toml files.
By clicking the Download button, I got a folder with 5 files in html and json formats. Complete Conversation History There is another file containing the conversation history, and also including some metadata. The metadata provides information about the main data. Self-made screenshot from ChatGPT’s settings window.
Jump Right To The Downloads Section Configuring Your Development Environment To follow this guide, you need to have torch , torchvision , tqdm , and matplotlib libraries installed on your system. Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images. The config.py
Steps followed 1) Data Collection Creating the Google credentials and generating the YouTube Data API Key Scraping Youtube links using Python code and a generated API Key Downloading the videos of the links saved 2) Setup and Installations Setting up the virtual Python 3.9 importlib-metadata==6.1.0 mp4 │ │ │ ├── video2.mp4 aioice==0.9.0
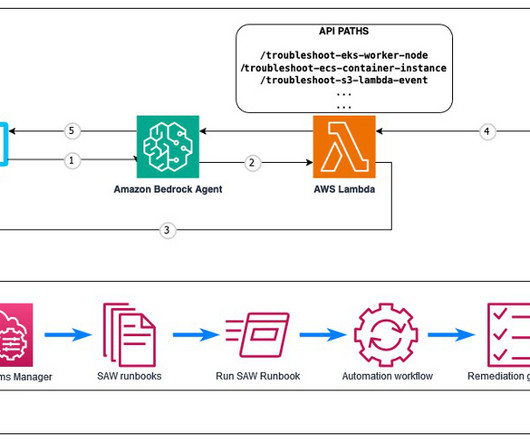
Solution overview In this section, we present the overall workflow and explain the approach. The following diagram provides an overview of the workflow explained in this post. Then we construct a request metadata and record the start time to be used for load testing. First, we import the necessary Locust and Boto3 libraries.
NET, Java and shell script. As said, a nuclio would be wrapped into a contaier, there is a yaml to define how to setup the container, as well as some supporting code that run the inference. and supporting functions in model_handler.py
Jump Right To The Downloads Section OAK-D: Understanding and Running Neural Network Inference with DepthAI API Introduction In our previous tutorial, Introduction to OpenCV AI Kit (OAK) , we gave a primer on OAK by discussing the Luxonis flagship products: OAK-1 and OAK-D, becoming the most popular edge AI devices with depth capabilities.
Just as with TensorFlow datasets, this facilitates easy downloading, caching, and on-demand loading of the datasets from the original dataset server. Instead, it stores the owner’s details, the preparation script, the dataset’s description, and the link to download the dataset. The central hub does not store or pass out the data sets.
Windows and Mac have docker and docker-compose packaged into one application, so if you download docker on Windows or Mac, you have both docker and docker-compose. To download it, type this in your terminal curl -LFO '[link] and press enter. The docker-compose.yaml file that will be used is the official file from Apache Airflow.
There are a number of theories that try to explain this effect: When tensor updates are big in size, traffic between workers and the parameter server can get congested. The method returns a dictionary containing tuning job metadata and results. So, why did distributing the training process affect model accuracy?
LangChain loads training data in the form of ‘Documents’, and these contain text from various sources and their respective metadata. So, let’s download the dataset from the data world. The rest are optional like prompt template, metadata, tags, etc. We pay our contributors, and we don’t sell ads.
skills and industry) and course metadata (e.g., All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. ✓ Access to centralized code repos for all 512+ tutorials on PyImageSearch ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
You will see an Amazon Simple Storage Service (Amazon S3) link to a metadata file. Let’s look at the file without downloading it. To discover the schema to be used while invoking the API from Einstein Studio, choose Information in the navigation pane of the Model Registry. Copy and paste the link into a new browser tab URL.
Each item has rich metadata (e.g., And it goes on to personalize title images, trailers, metadata, synopsis, etc. These features can be simple metadata or model-based features (extracted from a deep learning model), representing how good that video is for a member. genre, actors, director, year, popularity). That’s not the case.
Jump Right To The Downloads Section Configuring Your Development Environment To follow this guide, you need to have numpy , Pillow , torch , torchvision , matplotlib , pandas , scipy , and imageio libraries installed on your system. Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content