This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Automated document fraud detection powered by AI offers a proactive solution, letting businesses to verify documents in real-time, detect anomalies, and prevent fraud before it occurs. Here is where AI-powered intelligent documentprocessing (IDP) is changing the game. What is intelligent documentprocessing?
This article was published as a part of the Data Science Blogathon Overview Sentence classification is one of the simplest NLP tasks that have a wide range of applications including document classification, spam filtering, and sentiment analysis. A sentence is classified into a class in sentence classification.
Rapid Automatic Keyword Extraction(RAKE) is a Domain-Independent keyword extraction algorithm in NaturalLanguageProcessing. It is an Individual document-oriented dynamic Information retrieval method. The post Rapid Keyword Extraction (RAKE) Algorithm in NaturalLanguageProcessing appeared first on Analytics Vidhya.
NaturalLanguageProcessing (NLP) and Artificial Intelligence (AI) emerge as a powerful tools to revolutionize capital infrastructure planning, foster inclusivity, and drive an equitable future by engaging communities in decision-making. NLP is a great leveler.
The post Latent Semantic Analysis and its Uses in NaturalLanguageProcessing appeared first on Analytics Vidhya. Textual data, even though very important, vary considerably in lexical and morphological standpoints. Different people express themselves quite differently when it comes to […].
This is where the term frequency-inverse document frequency (TF-IDF) technique in NaturalLanguageProcessing (NLP) comes into play. Introduction Understanding the significance of a word in a text is crucial for analyzing and interpreting large volumes of data. appeared first on Analytics Vidhya.
Introduction In the field of NaturalLanguageProcessing i.e., NLP, Lemmatization and Stemming are Text Normalization techniques. These techniques are used to prepare words, text, and documents for further processing.
Introduction NLP (NaturalLanguageProcessing) can help us to understand huge amounts of text data. Instead of going through a huge amount of documents by hand and reading them manually, we can make use of these techniques to speed up our understanding and get to the main messages quickly.
NaturalLanguageProcessing (NLP) is a rapidly growing field that deals with the interaction between computers and human language. To help you on your journey to mastering NLP, we’ve curated a list of 20 GitHub repositories that offer valuable resources, code examples, and pre-trained models.
Knowledge Base Integration: Connects to structured knowledge sources (websites, documents, etc.) NaturalLanguageProcessing (NLP): Built-in NLP capabilities for understanding user intents and extracting key information. for accurate and contextually relevant answers.
AI in healthcare is causing a revolution in how clinicians document, analyze, and make decisions. AI Scribes: Redefining Clinical Documentation AI has a big influence on clinical documentation, which is one of the main areas it's changing. They also help make documentation more accurate and complete.
The team has presented the BABILong framework, which is a generative benchmark for testing NaturalLanguageProcessing (NLP) models on processing arbitrarily lengthy documents containing scattered facts in order to assess models with very long inputs.
NaturalLanguageProcessing (NLP) is integral to artificial intelligence, enabling seamless communication between humans and computers. Researchers from East China University of Science and Technology and Peking University have surveyed the integrated retrieval-augmented approaches to language models.
Its modular design allows developers to combine multiple ML solutions into efficient processing pipelines, while WebGL acceleration ensures smooth performance even on mobile devices. The framework's cross-platform support and extensive documentation make it an excellent choice for developers building sophisticated real-time AI applications.
AI practice management solutions are improving healthcare operations through automation and intelligent processing. These platforms handle essential tasks like clinical documentation, medical imaging analysis, patient communications, and administrative workflows, letting providers focus on patient care.
Knowledge-intensive NaturalLanguageProcessing (NLP) involves tasks requiring deep understanding and manipulation of extensive factual information. The primary challenge in knowledge-intensive NLP tasks is that large pre-trained language models need help accessing and manipulating knowledge precisely.
Voice intelligence combines speech recognition, naturallanguageprocessing, and machine learning to turn voice data into actionable insights. NaturalLanguageProcessing (NLP) Once speech becomes text, naturallanguageprocessing, or NLP, models analyze the actual meaning.
In NaturalLanguageProcessing (NLP), Text Summarization models automatically shorten documents, papers, podcasts, videos, and more into their most important soundbites. What is Text Summarization for NLP? The models are powered by advanced Deep Learning and Machine Learning research.
Unlocking efficient legal document classification with NLP fine-tuning Image Created by Author Introduction In today’s fast-paced legal industry, professionals are inundated with an ever-growing volume of complex documents — from intricate contract provisions and merger agreements to regulatory compliance records and court filings.
OpenAI, known for its general-purpose models like GPT-4 and Codex, excels in naturallanguageprocessing and problem-solving across many applications. OpenAIs o1 model, based on its GPT architecture, is highly adaptable and performs exceptionally well in naturallanguageprocessing and text generation.
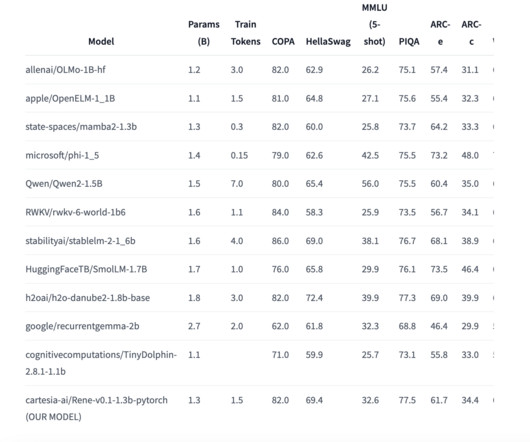
This open-source model, built upon a hybrid architecture combining Mamba-2’s feedforward and sliding window attention layers, is a milestone development in naturallanguageprocessing (NLP). Performance and Benchmarking Rene has been evaluated against several common NLP benchmarks.
The company aims to acquire agencies with under $5 million in revenue a segment often overlooked by traditional private equity and infuse them with machine learning tools that handle repetitive tasks like documentprocessing, client onboarding, and claims management.
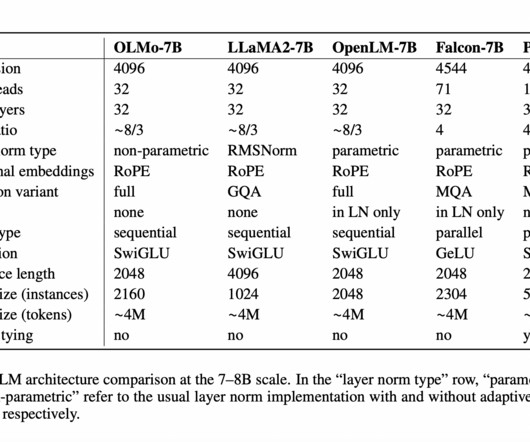
To address these challenges, researchers from the Allen Institute for AI (AI2) have released OLMo (Open Language Model), a framework aimed at promoting an atmosphere of transparency in the field of NaturalLanguageProcessing. The key features of OLMo are as follows.
Large language models ( LLMs ) like GPT-4, PaLM, Bard, and Copilot have made a huge impact in naturallanguageprocessing (NLP). Their design makes them accessible and cost-effective, offering organizations an opportunity to harness NLP without the heavy demands of LLMs. SLMs also excel in cybersecurity.
This capability enhances responses from generative AI applications by automatically creating embeddings for semantic search and generating a graph of the entities and relationships extracted from ingested documents. This new capability integrates the power of graph data modeling with advanced naturallanguageprocessing (NLP).
Large language models (LLMs) have revolutionized the field of naturallanguageprocessing, enabling machines to understand and generate human-like text with remarkable accuracy. However, despite their impressive language capabilities, LLMs are inherently limited by the data they were trained on.
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. The Process Data Lambda function redacts sensitive data through Amazon Comprehend.
I have written short summaries of 68 different research papers published in the areas of Machine Learning and NaturalLanguageProcessing. Dwell in the Beginning: How Language Models Embed Long Documents for Dense Retrieval João Coelho, Bruno Martins, João Magalhães, Jamie Callan, Chenyan Xiong. ArXiv 2024.
John Snow Labs is the developer behind Spark NLP, Healthcare NLP, and Medical LLMs. John Snow Labs’ Medical Language Models is by far the most widely used naturallanguageprocessing (NLP) library by practitioners in the healthcare space (Gradient Flow, The NLP Industry Survey 2022 and the Generative AI in Healthcare Survey 2024 ).
How the AI Transcription & Summarization Works Fathom uses advanced naturallanguageprocessing (NLP) to transcribe your entire meeting in real time with high accuracy, typically between 85% and 90%. It's great for individuals or small teams prioritizing basic meeting documentation without additional costs.
Large Language Models (LLMs) have shown remarkable capabilities across diverse naturallanguageprocessing tasks, from generating text to contextual reasoning. Enhanced Long-Text Processing SepLLM processes sequences exceeding four million tokens, surpassing traditional length limitations.
A significant challenge with question-answering (QA) systems in NaturalLanguageProcessing (NLP) is their performance in scenarios involving extensive collections of documents that are structurally similar or ‘indistinguishable.’ Knowledge graphs and LLMs are used to model these relationships.
However, with Healthcare NLP s task-based pretrained pipelines, these challenges can be overcome with simple one-liner solutions that tackle everything from entity recognition to de-identification. Similarly, Healthcare NLP pipelines follow this principle, enabling seamless text processing for clinical applications.
This advancement has spurred the commercial use of generative AI in naturallanguageprocessing (NLP) and computer vision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
Knowledge base and database connectors: Give the bot context from your documents or data tables. This means your AI agents can automatically update records, send emails, pull documents, or trigger workflows in your existing software stack. Visit BotPress 2. plus the ability to record UI actions for legacy systems.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. Model monitoring of key NLP metrics was incorporated and controls were implemented to prevent unsafe, unethical, or off-topic responses.
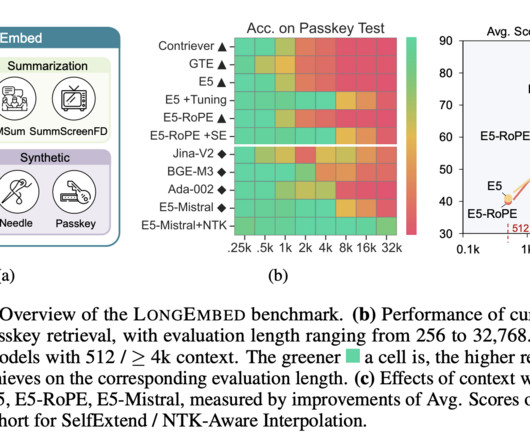
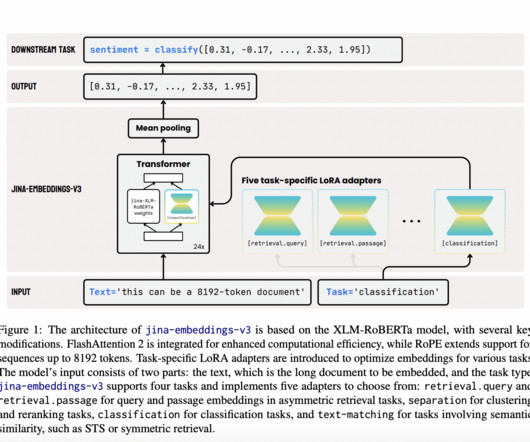
Embedding models are fundamental tools in naturallanguageprocessing (NLP), providing the backbone for applications like information retrieval and retrieval-augmented generation. Existing research in NLP embedding models has progressively focused on extending context capabilities.
In today’s data-driven business landscape, the ability to efficiently extract and process information from a wide range of documents is crucial for informed decision-making and maintaining a competitive edge. Confidence scores and human review Maintaining data accuracy and quality is paramount in any documentprocessing solution.
An early hint of today’s naturallanguageprocessing (NLP), Shoebox could calculate a series of numbers and mathematical commands spoken to it, creating a framework used by the smart speakers and automated customer service agents popular today.
This solution used AWS services such as Amazon Bedrock, Amazon ECS and Amazon S3 to assess solution design documents, stay updated with regulatory updates and industry best practices. They developed a “Resilience by Design Advisor” to address these challenges. It also incorporated the bank’s technology resilience framework.
Text embedding models have become foundational in naturallanguageprocessing (NLP). These models convert text into high-dimensional vectors that capture semantic relationships, enabling tasks like document retrieval, classification, clustering, and more.
The Eora MRIO (Multi-region input-output) dataset is a globally recognized spend-based emission factor set that documents the inter-sectoral transfers amongst 15.909 sectors across 190 countries. In recent years, remarkable strides have been achieved in crafting extensive foundation language models for naturallanguageprocessing (NLP).
Translating naturallanguage into vectors reduces the richness of the information, potentially leading to less accurate answers. Also, end-user queries are not always aligned semantically to useful information in provided documents, leading to vector search excluding key data points needed to build an accurate answer.
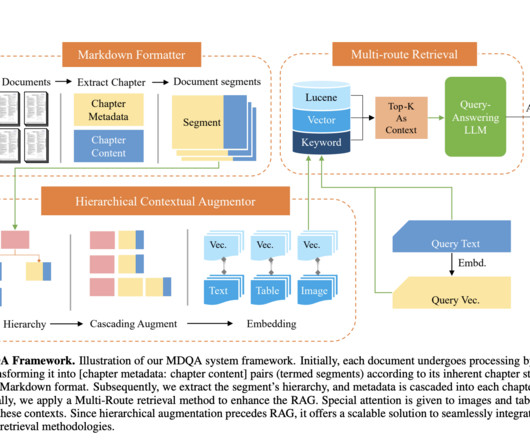
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional documentprocessing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content