This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
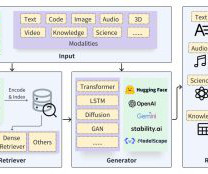
Introduction This article aims to create an AI-powered RAG and Streamlit chatbot that can answer users questions based on custom documents. Users can upload documents, and the chatbot can answer questions by referring to those documents.
Introduction LlamaParse is a document parsing library developed by Llama Index to efficiently and effectively parse documents such as PDFs, PPTs, etc. The nature of […] The post Simplifying Document Parsing: Extracting Embedded Objects with LlamaParse appeared first on Analytics Vidhya.
Integrating with various tools allows us to build LLM applications that can automate tasks, provide […] The post What are Langchain Document Loaders? appeared first on Analytics Vidhya.
RAG is replacing the traditional search-based approaches and creating a chat with a document environment. The biggest hurdle in RAG is to retrieve the right document. Only when we get […] The post Enhancing RAG with Hypothetical Document Embedding appeared first on Analytics Vidhya.
For invoice extraction, one has to gather data, build a document search machine learning model, model fine-tuning etc. The introduction of Generative AI took all of us by storm and many things were simplified using the LLM model.
JPMorgan has unveiled its latest AI – DocLLM, an extension to large language models (LLMs) designed for comprehensive document understanding. Thus, providing an efficient solution for processing visually complex documents.
These models can understand and generate human-like text, enabling applications like chatbots and document summarization. Ludwig, a low-code framework, is designed […] The post Ludwig: A Comprehensive Guide to LLM Fine Tuning using LoRA appeared first on Analytics Vidhya.
Chatgpt New ‘Bing' Browsing Feature Prompt engineering is effective but insufficient Prompts serve as the gateway to LLM's knowledge. However, crafting an effective prompt is not the full-fledged solution to get what you want from an LLM. Although advanced LLM has built-in mechanisms to recognize and avoid such outputs.
Use it for a variety of tasks, like translating text, answering […] The post Unlocking LangChain & Flan-T5 XXL | A Guide to Efficient Document Querying appeared first on Analytics Vidhya. For example, OpenAI’s GPT-3 model has 175 billion parameters.
Alibaba has announced Marco-o1, a large language model (LLM) designed to tackle both conventional and open-ended problem-solving tasks. The Marco-o1 model and associated datasets have been made available to the research community through Alibaba’s GitHub repository, complete with comprehensive documentation and implementation guides.
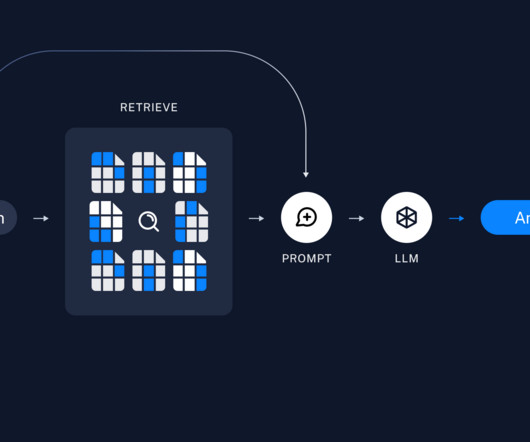
Large Language Models (LLMs) are revolutionizing how we process and generate language, but they're imperfect. Just like humans might see shapes in clouds or faces on the moon, LLMs can also ‘hallucinate,' creating information that isn’t accurate. Let’s take a closer look at how RAG makes LLMs more accurate and reliable.
With a remarkable 500,000-token context window —more than 15 times larger than most competitors—Claude Enterprise is now capable of processing extensive datasets in one go, making it ideal for complex document analysis and technical workflows. Let's dive into the top options and their impact on enterprise AI.
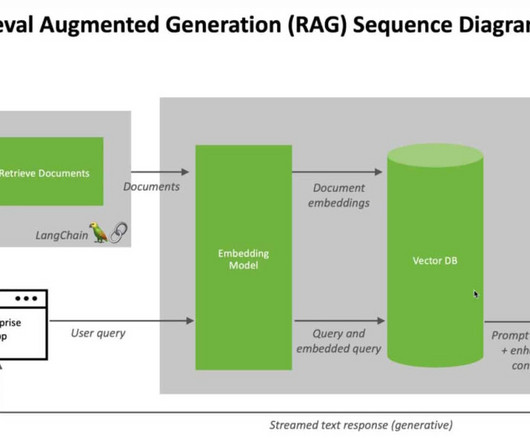
In-context learning has emerged as an alternative, prioritizing the crafting of inputs and prompts to provide the LLM with the necessary context for generating accurate outputs. They help in importing data from varied sources and formats, encapsulating them into a simplistic ‘Document' representation.
Introduction In my previous blog post, Building Multi-Document Agentic RAG using LLamaIndex, I demonstrated how to create a retrieval-augmented generation (RAG) system that could handle and query across three documents using LLamaIndex.
Google’s researchers have unveiled a groundbreaking achievement – Large Language Models (LLMs) can now harness Machine Learning (ML) models and APIs with the mere aid of tool documentation.
In this comprehensive guide, we'll explore LLM-driven synthetic data generation, diving deep into its methods, applications, and best practices. Introduction to Synthetic Data Generation with LLMs Synthetic data generation using LLMs involves leveraging these advanced AI models to create artificial datasets that mimic real-world data.
ResearchBot is a cutting-edge LLM-powered application project that uses the capabilities of OpenAI’s LLM (Large Language Models) with Langchain for Information retrieval.
This breakdown will look into some of the tools that enable running LLMs locally, examining their features, strengths, and weaknesses to help you make informed decisions based on your specific needs. AnythingLLM AnythingLLM is an open-source AI application that puts local LLM power right on your desktop.
Every customer conversation or VC pitch involves questions about how ready LLM tech is and how it will drive future applications. Large Language Models and Core Strengths LLMs are good at understanding language, that’s their forte. Then the search results are compiled into a prompt and sent to the LLM mostly as an API call.
Large Language Model (LLM) technology will play a significant role in the development of future applications. LLMs are very good at understanding language because of the extensive pre-training that has been done for foundation models on trillions of lines of public domain text, including code. Let’s look at these various levels.
Introduction With the advent of RAG (Retrieval Augmented Generation) and Large Language Models (LLMs), knowledge-intensive tasks like Document Question Answering, have become a lot more efficient and robust without the immediate need to fine-tune a cost-expensive LLM to solve downstream tasks.
Chat with Multiple Documents using Gemini LLM is the project use case on which we will build this RAG pipeline. Introduction Retriever is the most important part of the RAG(Retrieval Augmented Generation) pipeline. In this article, you will implement a custom retriever combining Keyword and Vector search retriever using LlamaIndex.
The LLM-as-a-Judge framework is a scalable, automated alternative to human evaluations, which are often costly, slow, and limited by the volume of responses they can feasibly assess. Here, the LLM-as-a-Judge approach stands out: it allows for nuanced evaluations on complex qualities like tone, helpfulness, and conversational coherence.
I recently wrotea blog which (amongst other things) complained that LLM benchmarks did not measure real-world utility. A few people responded that they thought coding benchmarks might be an exception, since many software developers use LLMs to help them create software. Debugging time.
Handling long text sequences efficiently is crucial for document summarization, retrieval-augmented question answering, and multi-turn dialogues […] The post Optimizing LLM for Long Text Inputs and Chat Applications appeared first on Analytics Vidhya.
I recently wrote a blog complaining that LLM benchmarks do a bad job of assessing NLG. I got a lot of feedback and comments on this, which highlighted to me that there were lots of problems with LLM benchmarks and benchmark suites. It seems to be standard practice to use such suites to assess LLMs. then it may not be important.
Ease of Integration : Groq offers both Python and OpenAI client SDKs, making it straightforward to integrate with frameworks like LangChain and LlamaIndex for building advanced LLM applications and chatbots. Real-Time Streaming : Enables streaming of LLM outputs, minimizing perceived latency and enhancing user experience.
Retrieval-Augmented Generation (RAG) is a technique that combines the power of LLMs with external knowledge retrieval. RAG allows us to ground LLM responses in factual, up-to-date information, significantly improving the accuracy and reliability of AI-generated content. What are LLM Agents?
This new tool, LLM Suite, is being hailed as a game-changer and is capable of performing tasks traditionally assigned to research analysts. ” The purpose of the platform is to change how employees work with their daily tasks, and it has various functions, including writing, helping to generate ideas, and document summarisation.
Google Open Source LLM Gemma In this comprehensive guide, we'll explore Gemma 2 in depth, examining its architecture, key features, and practical applications. ") print(response["result"]) This RAG system uses Gemma 2 through Ollama for the language model, and Nomic embeddings for document retrieval.
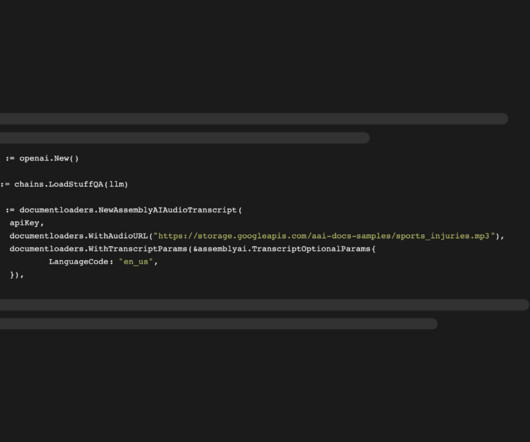
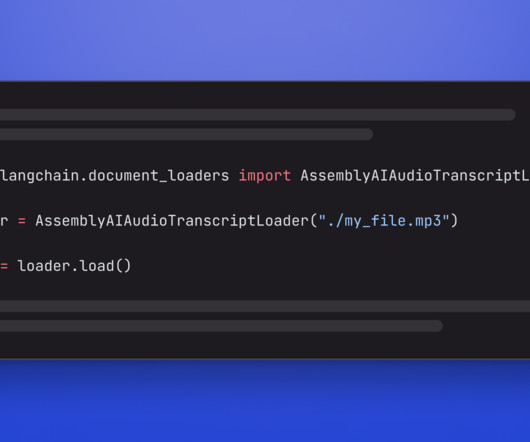
However, LLMs only operate on textual data and don't understand audio data. With our recent contribution to LangChain Go , you can now integrate AssemblyAI's industry-leading speech-to-text models using the new document loader. The following example answers a question about an audio file.
To deal with this issue, various tools have been developed to detect and correct LLM inaccuracies. Pythia Image source Pythia uses a powerful knowledge graph and a network of interconnected information to verify the factual accuracy and coherence of LLM outputs. Well-documented with tutorials. Continuously evolving.
A researcher within Google leaked a document on a public Discord server recently. There is much controversy surrounding the document’s authenticity. Discord is an open-source community platform. Many other groups also use it, but Discord is primarily designed for communities of gamers to facilitate voice, video, and text chat.
Thankfully, retrieval-augmented generation (RAG) has emerged as a promising solution to ground large language models (LLMs) on the most accurate, up-to-date information. Enabling Generative AI outcomes with the cloud Generative AI and LLMs have already proven to have great potential for transforming organizations across industries.
This week, I am super excited to finally announce that we released our first independent industry-focus course: From Beginner to Advanced LLM Developer. Put a dozen experts (frustrated ex-PhDs, graduates, and industry) and a year of dedicated work, and you get the most practical and in-depth LLM Developer course out there (~90 lessons).
For AI and large language model (LLM) engineers , design patterns help build robust, scalable, and maintainable systems that handle complex workflows efficiently. This article dives into design patterns in Python, focusing on their relevance in AI and LLM -based systems. BERT, GPT, or T5) based on the task.
Furthermore, the document outlines plans for implementing a “consent popup” mechanism to inform users about potential defects or errors produced by AI. Developers will also only be able to deploy these technologies after labelling the potential fallibility or unreliability of the output generated.
In this tutorial, well learn how to build a chatbot that interacts with your documents, like PDFs, using Retrieval-Augmented Generation (RAG). By the end, youll have a chatbot capable of answering questions directly from your documents, keeping context of your conversation, and providing concise, accurate answers. and run python app.py
For this, we create a small demo application that lets you load audio data and apply an LLM that can answer questions about your spoken data. This document loader transcribes the given audio file and loads the transcribed text into LangChain documents. You can read more about the integration in the official LangChain docs.
Retrieval Augmented Generation (RAG) is a method to augment the relevance and transparency of Large Language Model (LLM) responses. In this approach, the LLM query retrieves relevant documents from a database and passes these into the LLM as additional context. The source code for this tutorial can be found in this repo.
Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing allows us to understand an LLMs capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk.
As the demand for large language models (LLMs) continues to rise, ensuring fast, efficient, and scalable inference has become more crucial than ever. NVIDIA's TensorRT-LLM steps in to address this challenge by providing a set of powerful tools and optimizations specifically designed for LLM inference.
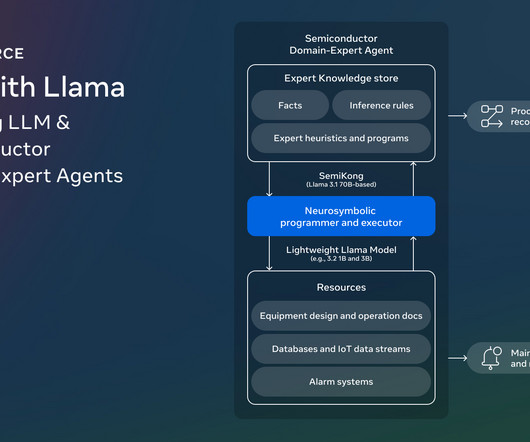
SemiKong represents the worlds first semiconductor-focused large language model (LLM), designed using the Llama 3.1 This model was fine-tuned with extensive semiconductor-specific datasets, including industry documents, research papers, and anonymized operational data. Trending: LG AI Research Releases EXAONE 3.5:
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content