This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One effective way to improve context relevance is through metadata filtering, which allows you to refine search results by pre-filtering the vector store based on custom metadata attributes. By combining the capabilities of LLM function calling and Pydantic data models, you can dynamically extract metadata from user queries.
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
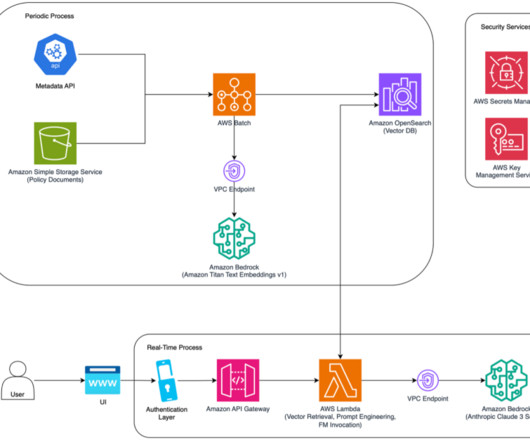
Along with each document slice, we store the metadata associated with it using an internal Metadata API, which provides document characteristics like document type, jurisdiction, version number, and effective dates. This process has been implemented as a periodic job to keep the vector database updated with new documents.
The platform automatically analyzes metadata to locate and label structured data without moving or altering it, adding semantic meaning and aligning definitions to ensure clarity and transparency. When onboarding customers, we automatically retrain these ontologies on their metadata.
Also, a lakehouse can introduce definitionalmetadata to ensure clarity and consistency, which enables more trustworthy, governed data. Watsonx.data enables users to access all data through a single point of entry, with a shared metadata layer deployed across clouds and on-premises environments.
Establishing standardized definitions and control measures builds a solid foundation that evolves as the framework matures. Data owners manage data domains, help to ensure quality, address data-related issues, and approve data definitions, promoting consistency across the enterprise.
MLflow metadata backend This crucial part of the tracking server is responsible for storing all the essential information about your experiments. ModelRunner definition For BedrockModelRunner , we need to find the model content_template. This allows you to keep track of your ML experiments.
And it definitely didn’t understand the Masters. The AI translates the metadata from each shot into descriptive textual elements. . “Garbage in, garbage out” has never been more true than it is right now. But it didn’t understand golf. For example, at Augusta National Golf Club, a sand trap is called a bunker.
Therefore, we see national and international guidelines address these overlapping and intersecting definitions in a variety of ways. Relevant definitions of AI: Model owners may not realize that what they are procuring or deploying actually meets the definition of AI or intelligent automation as described by a regulation.
SELECT count (*) FROM FLIGHT.FLIGHTS_DATA — — — 99879 Look into the scheme definition of the table. Here are some of the key tables: FLIGHT_DECTREE_MODEL: this table contains metadata about the model. CREATE TABLE FLIGHT.FLIGHTS_DATA AS (SELECT * FROM FLIGHTS.FLIGHTS_DATA_V3 WHERE RAND () < 0.1)
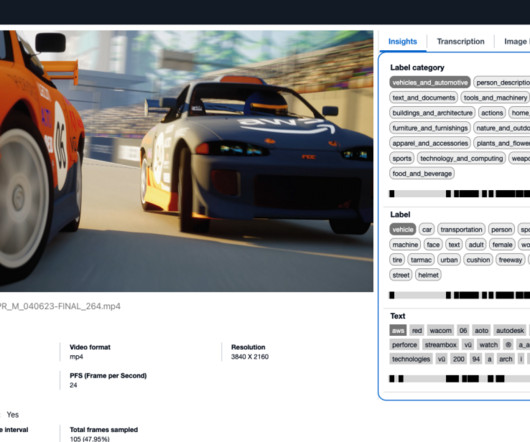
Veritone’s current media search and retrieval system relies on keyword matching of metadata generated from ML services, including information related to faces, sentiment, and objects. We use the Amazon Titan Text and Multimodal Embeddings models to embed the metadata and the video frames and index them in OpenSearch Service.
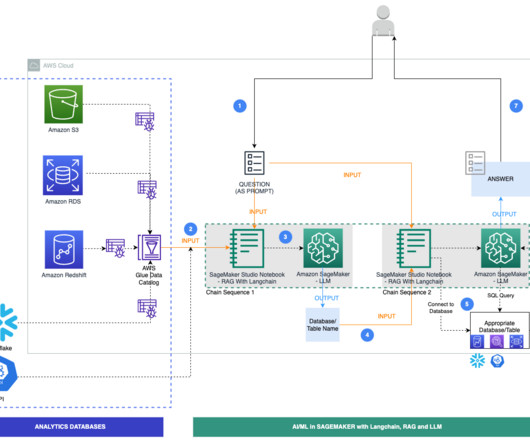
This configuration takes the form of a Directed Acyclic Graph (DAG) represented as a JSON pipeline definition. The DevOps engineer can then use the Kubernetes APIs provided by ACK to submit the pipeline definition and initiate one or more pipeline runs in SageMaker. This entire workflow is shown in the following solution diagram.
Update the Kubernetes secret definition by adding or removing fields or updating the referenced Secrets Manager CRN for a TLS secret. v1 kind: Ingress metadata: annotations: kubernetes.io/ingress.class: Update Update the configuration of a domain. Update an ALB version for a specific ALB. ingress.class: public-iks-k8s-nginx // 2.
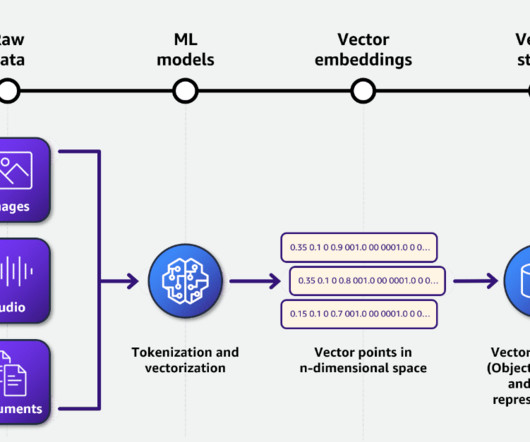
The embeddings, along with metadata about the source documents, are indexed for quick retrieval. It provides constructs to help developers build generative AI applications using pattern-based definitions for your infrastructure. The embeddings are stored in the Amazon OpenSearch Service owner manuals index.
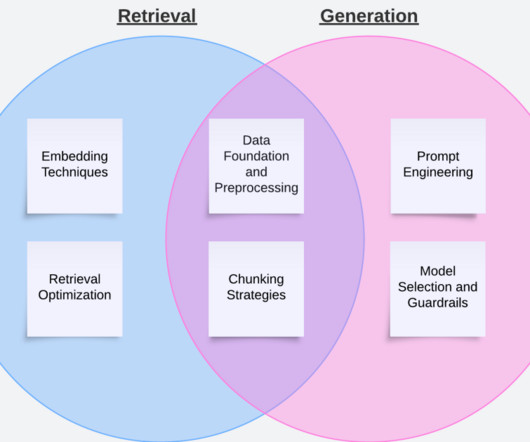
Implement metadata filtering , adding contextual layers to chunk retrieval. For code samples for metadata filtering using Amazon Bedrock Knowledge Bases, refer to the following GitHub repo. What specific components require refinement? Where should you focus your optimization efforts for maximum impact?
Each frame will be analyzed using Amazon Rekognition and Amazon Bedrock for metadata extraction. Policy evaluation – Using the extracted metadata from the video, the system conducts LLM evaluation. An Amazon OpenSearch Service cluster stores the extracted video metadata and facilitates users’ search and discovery needs.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. JSONs inherently structured format allows for clear and organized representation of complex data such as table schemas, column definitions, synonyms, and sample queries.
the definitions of the conflicting attributes in the example). The files containing code spans that satisfy the query definition constitute the positive examples for the query. An answer to these semantic queries should identify code spans constituting the answer (e.g.,
If it was a 4xx error, its written in the metadata of the Job. In a metadata generation use case, we can provide the image and ask the LLM to generate a description and keywords describing the image in a specific format. Failed The job is marked Failed if there was an error while processing.
It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. In the notebook, we already added the @step decorator at the beginning of each function definition in the cell where the function was defined, as shown in the following code.
In her book, Data lineage from a business perspective , Dr. Irina Steenbeek introduces the concept of descriptive lineage as “a method to record metadata-based data lineage manually in a repository.” The first two use cases are primarily aimed at a technical audience, as the lineage definitions apply to actual physical assets.
There was no mechanism to pass and store the metadata of the multiple experiments done on the model. Because we wanted to track the metrics of an ongoing training job and compare them with previous training jobs, we just had to parse this StdOut by defining the metric definitions through regex to fetch the metrics from StdOut for every epoch.
This marketplace provides a search mechanism, utilizing metadata and a knowledge graph to enable asset discovery. Metadata plays a key role here in discovering the data assets. As it is clear from the definition above, unlike data fabric, data mesh is about analytical data. Data fabric promotes data discoverability.
For explainability, KGs allow us to link answers back to term definitions, data sources, and metrics, providing a verifiable trail that enhances trust and usability. KGs use semantics to represent data as real-world entities and relationships, making them more accurate than SQL databases, which focus on tables and columns.
In the terminal with the AWS Command Line Interface (AWS CLI) or AWS CloudShell , run the following commands to upload the documents and metadata to the data source bucket: aws s3 cp s3://aws-ml-blog/artifacts/building-a-secure-search-application-with-access-controls-kendra/docs.zip. For Metadata files prefix folder location , enter Meta/.
The absence of centralized workflow definitions means that message processing occurs naturally based on publication timing and agent availability, creating a fluid and adaptable system that can evolve with changing requirements. The only change is the additional agent added to the collaboration stored as configuration outside of the broker.
The work definitely signals the path for Apple on-device model strategy and the large number of modalities is quite shocking. Metadata: Various types of metadata from RGB images and other modalities. Text Tokenizer: For encoding text and other modalities like bounding boxes and metadata.
An AWS Glue crawler is scheduled to run at frequent intervals to extract metadata from databases and create table definitions in the AWS Glue Data Catalog. As part of Chain Sequence 1, the prompt and Data Catalog metadata are passed to an LLM, hosted on a SageMaker endpoint, to identify the relevant database and table using LangChain.
Solution overview To solve this problem, you can identify one or more unique metadata information that is associated with the documents being indexed and searched. In Amazon Kendra, you provide document metadata attributes using custom attributes.
A media metadata store keeps the promotion movie list up to date. The agent takes the promotion item list (movie name, description, genre) from a media metadata store. The first component retrieves data from a feature store, and the second component acquires a list of movie promotions from the metadata store.
It supports three primary data ingestion patterns: Event data sources for timestamped activity Entity data sources for attribute metadata related to business entities Cumulative Event Sources for tracking historical changes in slowly changing dimensions Computation Contexts and Types Chronon operates in two distinct contexts: online and offline.
Connection definition JSON file When connecting to different data sources in AWS Glue, you must first create a JSON file that defines the connection properties—referred to as the connection definition file. The following is a sample connection definition JSON for Snowflake.
A document is a collection of information that consists of a title, the content (or the body), metadata (data about the document), and access control list (ACL) information to make sure answers are provided from documents that the user has access to. Amazon Q supports the crawling and indexing of these custom objects and custom metadata.
The output of a SageMaker Ground Truth labeling job is a file in JSON-lines format containing the labels and additional metadata. Create a SageMaker pipeline definition to orchestrate model building. If you are interested in the detailed pipeline code, check out the pipeline definition in our sample repository.
The devs definitely put some extra effort into the contract to double check their work, to ensure that Creyzies tokens went to the right addresses and never exceeded mfers supply. This URI points to metadata , which is where to find the NFT image and properties. Metadata being served from a web app can be changed very easily.
The devs definitely put some extra effort into the contract to double check their work, to ensure that Creyzies tokens went to the right addresses and never exceeded mfers supply. This URI points to metadata , which is where to find the NFT image and properties. Metadata being served from a web app can be changed very easily.
This helped to better organize the chunks and enhance them with relevant metadata. The metadata included: Identification of the document section where a paragraph was located. Detection of whether a paragraph was providing legal definitions. Recognition of whether a paragraph was discussing a date. We built them in a single day.
This helped to better organize the chunks and enhance them with relevant metadata. The metadata included: Identification of the document section where a paragraph was located. Detection of whether a paragraph was providing legal definitions. Recognition of whether a paragraph was discussing a date. We built them in a single day.
Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition. Understanding Data Lakes A data lake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format.
product specifications, movie metadata, documents, etc.) With reaching billions, no hardware can process these operations in a definite amount of time. Imagine a database with billions of samples ( ) (e.g., where comparing all samples with each other produces an infeasible time complexity of.
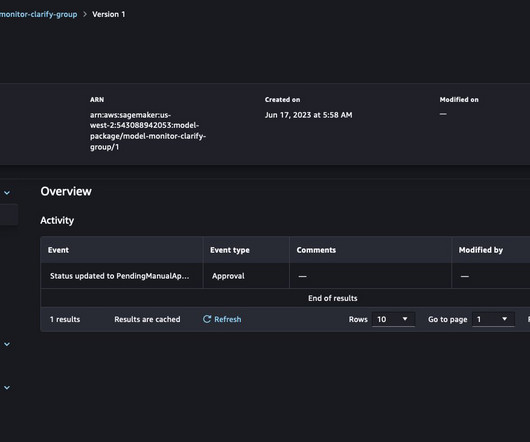
Model cards are intended to be a single source of truth for business and technical metadata about the model that can reliably be used for auditing and documentation purposes. The model registry supports a hierarchical structure for organizing and storing ML models with model metadata information.
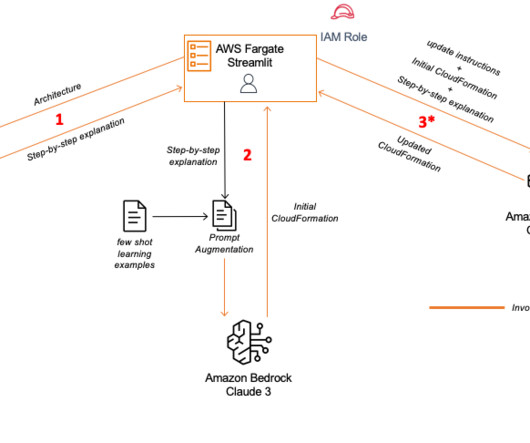
Exposing Anthropic’s Claude 3 Sonnet to multiple CloudFormation templates will allow it to analyze and learn from the structure, resource definitions, parameter configurations, and other essential elements consistently implemented across your organization’s templates. Second, we want to add metadata to the CloudFormation template.
Machine Learning Operations (MLOps): Overview, Definition, and Architecture” By Dominik Kreuzberger, Niklas Kühl, Sebastian Hirschl Great stuff. If you haven’t read it yet, definitely do so. Founded neptune.ai , a modular MLOps component for ML metadata store , aka “experiment tracker + model registry”. Came to ML from software.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content