This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Meet Tajinder, a seasoned Senior DataScientist and MLEngineer who has excelled in the rapidly evolving field of data science. Tajinder’s passion for unraveling hidden patterns in complex datasets has driven impactful outcomes, transforming raw data into actionable intelligence.
This article was published as a part of the Data Science Blogathon. Introduction A Machine Learning solution to an unambiguously defined business problem is developed by a DataScientist ot MLEngineer.
Ray streamlines complex tasks for MLengineers, datascientists, and developers. Its versatility spans data processing, model training, hyperparameter tuning, deployment, and reinforcement learning. Python Ray is a dynamic framework revolutionizing distributed computing.
This article was published as a part of the Data Science Blogathon. Image designed by the author – Shanthababu Introduction Every MLEngineer and DataScientist must understand the significance of “Hyperparameter Tuning (HPs-T)” while selecting your right machine/deep learning model and improving the performance of the model(s).
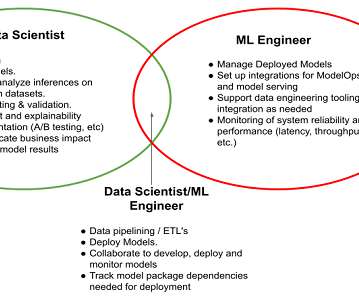
How much machine learning really is in MLEngineering? There are so many different data- and machine-learning-related jobs. But what actually are the differences between a DataEngineer, DataScientist, MLEngineer, Research Engineer, Research Scientist, or an Applied Scientist?!
It is often too much to ask for the datascientist to become a domain expert. However, in all cases the datascientist must develop strong domain empathy to help define and solve the right problems. Nina Zumel and John Mount, Practical Data Science with R, 2nd Ed. But this statement also goes upstream.
Generative AI Fundamentals Specialization This specialization offers a comprehensive introduction to generative AI, covering models like GPT and DALL-E, prompt engineering, and ethical considerations. It includes five self-paced courses with hands-on labs and projects using tools like ChatGPT, Stable Diffusion, and IBM Watsonx.ai.
Datascientists and MLengineers often need help to build full-stack applications. These professionals typically have a firm grasp of data and AI algorithms. It is a Python-based framework for datascientists and machine learning engineers. This is where Taipy comes into play.
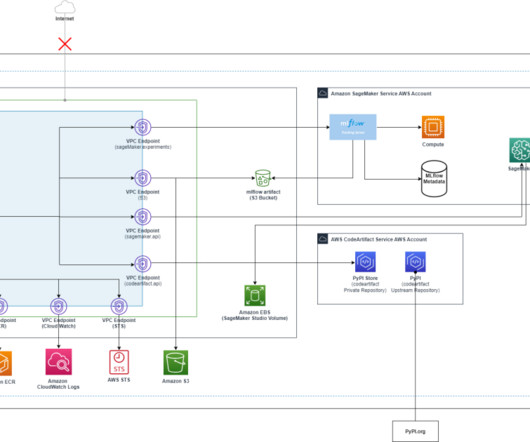
Amazon SageMaker is a cloud-based machine learning (ML) platform within the AWS ecosystem that offers developers a seamless and convenient way to build, train, and deploy ML models. The solution illustrated in this post focuses on the new SageMaker Studio experience, particularly private JupyterLab and Code Editor spaces.
According to a recent report by Harnham , a leading data and analytics recruitment agency in the UK, the demand for MLengineering roles has been steadily rising over the past few years. Harnham’s report provides comprehensive insights into the salaries and day rates of various data science roles across the UK.
End users should also seek companies that can help with this testing as often an MLEngineer can help with deployment vs. the DataScientist that created the model. Quite often deployment of a large model is too expensive to make it practical for use.
This also led to a backlog of data that needed to be ingested. Steep learning curve for datascientists: Many of Rockets datascientists did not have experience with Spark, which had a more nuanced programming model compared to other popular ML solutions like scikit-learn.
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for Data Science and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for datascientists and machine learning (ML) engineers.
The AI/MLengine built into MachineMetrics analyzes this machine data to detect anomalies and patterns that might indicate emerging problems. Continuous Anomaly Detection: Continuously monitors data streams and uses AI to detect anomalies or deviations, instantly alerting teams to potential problems.
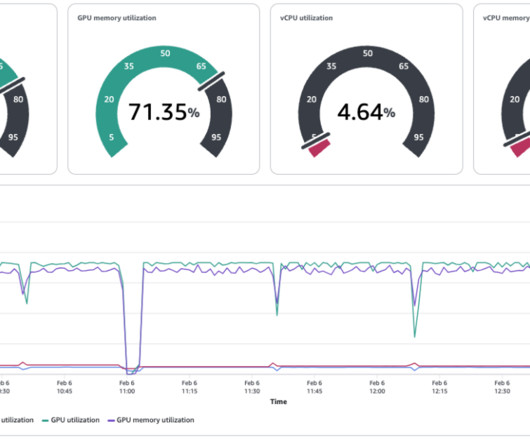
In this example, the MLengineering team is borrowing 5 GPUs for their training task With SageMaker HyperPod, you can additionally set up observability tools of your choice. Datascientist experience Datascientists are the second persona interacting with SageMaker HyperPod clusters. HyperPod CLI v2.0.0
Because the machine learning lifecycle has many complex components that reach across multiple teams, it requires close-knit collaboration to ensure that hand-offs occur efficiently, from data preparation and model training to model deployment and monitoring. How to use ML to automate the refining process into a cyclical ML process.
It helps companies streamline and automate the end-to-end ML lifecycle, which includes data collection, model creation (built on data sources from the software development lifecycle), model deployment, model orchestration, health monitoring and data governance processes.
The solution described in this post is geared towards machine learning (ML) engineers and platform teams who are often responsible for managing and standardizing custom environments at scale across an organization.
So, before we look at how to learn data science, we need to know: what really is a datascientist? I mean, MLengineers often spend most of their time handling and understanding data. So, how is a datascientist different from an MLengineer?
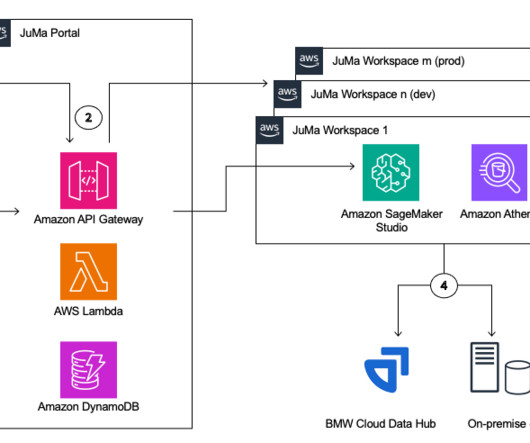
In an increasingly digital and rapidly changing world, BMW Group’s business and product development strategies rely heavily on data-driven decision-making. With that, the need for datascientists and machine learning (ML) engineers has grown significantly. Direct internet access is disabled within their domain.
VEW SPEAKER LINEUP Here’s a sneak peek of the agenda: LangChain Keynote: Hear from Lance Martin, an ML leader at LangChain, a leading orchestration framework for large language models (LLMs). Dive deep into these topics with our expert speakers and gain actionable insights for mastering AI and ML.
The new SDK is designed with a tiered user experience in mind, where the new lower-level SDK ( SageMaker Core ) provides access to full breadth of SageMaker features and configurations, allowing for greater flexibility and control for MLengineers.
Training Sessions Bayesian Analysis of Survey Data: Practical Modeling withPyMC Allen Downey, PhD, Principal DataScientist at PyMCLabs Alexander Fengler, Postdoctoral Researcher at Brown University Bayesian methods offer a flexible and powerful approach to regression modeling, and PyMC is the go-to library for Bayesian inference in Python.
Manager, MLEngineering at HelloFresh “Fireside Chat: LLMs, Real Time & Other Trends in the Production ML Space,” with Ali Ghodsi, CEO & Co-founder at Databricks , and Mike Del Balso, CEO & Co-founder at Tecton “Evolution of the Ads Ranking System at Pinterest,” by Aayush Mudgal, Sr.
The Vertex AI platform has gained growing popularity among clients as it accelerates ML development, slashing production time by up to 80% compared to alternative methods. It offers an extensive suite of ML Ops capabilities, enabling MLengineers, datascientists, and developers to contribute efficiently.
In the initial stages of an ML project, datascientists collaborate closely, sharing experimental results to address business challenges. MLflow , a popular open-source tool, helps datascientists organize, track, and analyze ML and generative AI experiments, making it easier to reproduce and compare results.
TWCo datascientists and MLengineers took advantage of automation, detailed experiment tracking, integrated training, and deployment pipelines to help scale MLOps effectively. ML model experimentation is one of the sub-components of the MLOps architecture.
The ML team lead federates via IAM Identity Center, uses Service Catalog products, and provisions resources in the ML team’s development environment. Datascientists from ML teams across different business units federate into their team’s development environment to build the model pipeline.
Data Analysis : Applying statistical methods to discover trends. Data Visualization : Presenting findings via charts and graphs. Predictive Modeling : Using data to predict future outcomes. Datascientists need to be skilled in programming, statistics, and domain knowledge. What is Machine Learning?
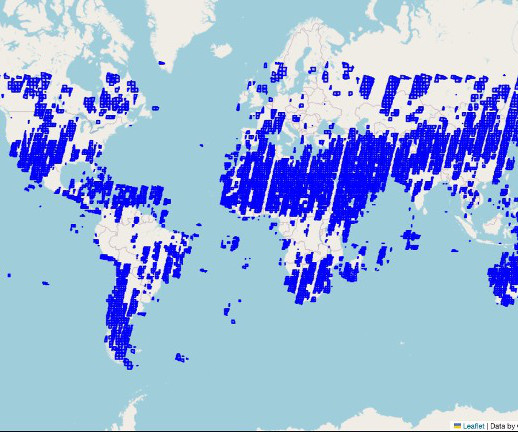
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing datascientists and MLengineers to build, train, and deploy ML models using geospatial data. These geospatial capabilities open up a new world of possibilities for environmental monitoring.
Working as a DataScientist — Expectation versus Reality! 11 key differences in 2023 Photo by Jan Tinneberg on Unsplash Working in Data Science and Machine Learning (ML) professions can be a lot different from the expectation of it. You could be working entirely on data analytics under a DataScientist job title.
Artificial intelligence (AI) and machine learning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. However, putting an ML model into production at scale is challenging and requires a set of best practices.
Clean up To clean up the model and endpoint, use the following code: predictor.delete_model() predictor.delete_endpoint() Conclusion In this post, we explored how SageMaker JumpStart empowers datascientists and MLengineers to discover, access, and run a wide range of pre-trained FMs for inference, including the Falcon 3 family of models.
You can use this framework as a starting point to monitor your custom metrics or handle other unique requirements for model quality monitoring in your AI/ML applications. DataScientist at AWS, bringing a breadth of data science, MLengineering, MLOps, and AI/ML architecting to help businesses create scalable solutions on AWS.
According to IDC , 83% of CEOs want their organizations to be more data-driven. Datascientists could be your key to unlocking the potential of the Information Revolution—but what do datascientists do? What Do DataScientists Do? Datascientists drive business outcomes.
Because if companies use code to automate business rules, they use ML/AI to automate decisions. Given that, what would you say is the job of a datascientist (or MLengineer, or any other such title)? But first, let’s talk about the typical ML workflow. I’ll share my answer in a bit.
The role of a datascientist is in demand and 2023 will be no exception. To get a better grip on those changes we reviewed over 25,000 datascientist job descriptions from that past year to find out what employers are looking for in 2023. Data Science Of course, a datascientist should know data science!
Generative AI Fundamentals Specialization This specialization offers a comprehensive introduction to generative AI, covering models like GPT and DALL-E, prompt engineering, and ethical considerations. It includes five self-paced courses with hands-on labs and projects using tools like ChatGPT, Stable Diffusion, and IBM Watsonx.ai.
Introduction to AI and Machine Learning on Google Cloud This course introduces Google Cloud’s AI and ML offerings for predictive and generative projects, covering technologies, products, and tools across the data-to-AI lifecycle.
FMEval is an open source LLM evaluation library, designed to provide datascientists and machine learning (ML) engineers with a code-first experience to evaluate LLMs for various aspects, including accuracy, toxicity, fairness, robustness, and efficiency.
They are often built by datascientists who are not software engineers or computer science majors by training. Python written in Jupyter notebooks following the tradition of data-centric programming is very different from Python used to implement a scalable web server. Data Science Layers. Software Architecture.
You can’t just cram a bunch of datascientists into an office and cross your fingers that everything works out. Bringing AI into a company means you have new roles to fill (datascientist, MLengineer) as well as new knowledge to backfill in existing roles (product, ops).
Simplified Synthetic Data Generation Designed to generate synthetic datasets using either local large language models (LLMs) or hosted models (OpenAI, Anthropic, Google Gemini, etc.), Promptwright makes synthetic data generation more accessible and flexible for developers and datascientists.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content