This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. The post Top 8 Low code/No code ML Libraries every DataScientist should know appeared first on Analytics Vidhya. Introduction The main motto of this post is to give a brief.
Introduction DataScientists have an important role in the modern machine-learning world. Leveraging ML pipelines can save them time, money, and effort and ensure that their models make accurate predictions and insights. Datascientists […] The post Why DataScientists Should Adopt Machine Learning Pipelines?
This article was published as a part of the Data Science Blogathon About Streamlit Streamlit is an open-source Python library that assists developers in creating interactive graphical user interfaces for their systems. It was designed especially for Machine Learning and DataScientist team. Frontend […].
The post 3 Building Blocks of Machine Learning you Should Know as a DataScientist appeared first on Analytics Vidhya. Overview A machine learning system consists of multiple building blocks that need to be managed Learn about the three key building blocks of machine.
Introduction A Machine Learning solution to an unambiguously defined business problem is developed by a DataScientist ot ML Engineer. The Model development process undergoes multiple iterations and finally, a model which has acceptable performance metrics on test data is taken to the production […].
Machine learning creates static models from historical data. But, once deployed in production, ML models become unreliable and obsolete and degrade with time. There might be changes in the data distribution in production, thus causing […].
Introduction Meet Tajinder, a seasoned Senior DataScientist and ML Engineer who has excelled in the rapidly evolving field of data science. Tajinder’s passion for unraveling hidden patterns in complex datasets has driven impactful outcomes, transforming raw data into actionable intelligence.
Introduction Jupyter Notebook is a web-based interactive computing platform that many datascientists use for data wrangling, data visualization, and prototyping of their Machine Learning models. The post How to Convert Jupyter Notebook into ML Web App? appeared first on Analytics Vidhya.
Uncomfortable reality: In the era of large language models (LLMs) and AutoML, traditional skills like Python scripting, SQL, and building predictive models are no longer enough for datascientist to remain competitive in the market. Coding skills remain important, but the real value of datascientists today is shifting.
The post Step-by-Step Guide to Become a DataScientist in 2023 appeared first on Analytics Vidhya. Despite facing many challenges and setbacks, they never gave up on their dream. Eventually, their hard work and determination paid off, as they landed […].
Machine learning (ML) models can be computationally intensive, and training the models can take longer. Datascientists can iterate faster, experiment […] The post RAPIDS: Use GPU to Accelerate ML Models Easily appeared first on Analytics Vidhya.
Introduction One of the key challenges in Machine Learning Model is the explainability of the ML Model that we are building. In general, ML Model is a Black Box. As Datascientists, we may understand the algorithm & statistical methods used behind the scene. […].
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product.
According to a recent report by Harnham , a leading data and analytics recruitment agency in the UK, the demand for ML engineering roles has been steadily rising over the past few years. Harnham’s report provides comprehensive insights into the salaries and day rates of various data science roles across the UK.
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machine learning (ML) models in Amazon SageMaker , users want a seamless and secure way to experiment with and select the models that deliver the most value for their business.
Introduction The area of machine learning (ML) is rapidly expanding and has applications across many different sectors. This can result in many problems for datascientists, such as: Given the above challenges, […] The post Machine Learning Experiment Tracking Using MLflow appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Machine learning (ML) has become an increasingly important tool for organizations of all sizes, providing the ability to learn and improve from data automatically.
The new SDK is designed with a tiered user experience in mind, where the new lower-level SDK ( SageMaker Core ) provides access to full breadth of SageMaker features and configurations, allowing for greater flexibility and control for ML engineers. In the following example, we show how to fine-tune the latest Meta Llama 3.1
Machine learning (ML) has become a critical component of many organizations’ digital transformation strategy. From predicting customer behavior to optimizing business processes, ML algorithms are increasingly being used to make decisions that impact business outcomes.
Leland Hyman is the Lead DataScientist at Sherlock Biosciences. He is an experienced computer scientist and researcher with a background in machine learning and molecular diagnostics. How does ML predict which molecular diagnostic components will perform with the greatest speed and accuracy?
Ray streamlines complex tasks for ML engineers, datascientists, and developers. Its versatility spans data processing, model training, hyperparameter tuning, deployment, and reinforcement learning. Python Ray is a dynamic framework revolutionizing distributed computing.
This article was published as a part of the Data Science Blogathon. Image designed by the author – Shanthababu Introduction Every ML Engineer and DataScientist must understand the significance of “Hyperparameter Tuning (HPs-T)” while selecting your right machine/deep learning model and improving the performance of the model(s).
This article was published as a part of the Data Science Blogathon. Image 1- [link] Whether you are an experienced or an aspiring datascientist, you must have worked on machine learning model development comprising of data cleaning, wrangling, comparing different ML models, training the models on Python Notebooks like Jupyter.
TrueFoundry offers a unified Platform as a Service (PaaS) that empowers enterprise AI/ML teams to build, deploy, and manage large language model (LLM) applications across cloud and on-prem infrastructure.
And every DataScientist wants to progress as fast as possible, so time-saving tips & tricks are a big deal as well. That’s why low-code tools are adopted among datascientists. The post Find External Data for Machine Learning Pipelines appeared first on Analytics Vidhya. So, there are two […].
Mid-market companies who weren't able to afford datascientists like P & G will now have the same capability at a fraction of the cost. Email subject lines and advertising that follow a similar ML script will likely create a boring experience for consumers. Over-automation can lead to content similarities.
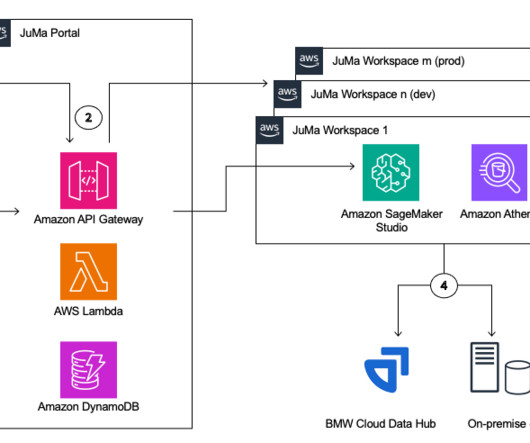
In an increasingly digital and rapidly changing world, BMW Group’s business and product development strategies rely heavily on data-driven decision-making. With that, the need for datascientists and machine learning (ML) engineers has grown significantly.
The agency wanted to use AI [artificial intelligence] and ML to automate document digitization, and it also needed help understanding each document it digitizes, says Duan. The demand for modernization is growing, and Precise can help government agencies adopt AI/ML technologies.
Datascientists and ML engineers often need help to build full-stack applications. These professionals typically have a firm grasp of data and AI algorithms. It is a Python-based framework for datascientists and machine learning engineers. This is where Taipy comes into play.
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for Data Science and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for datascientists and machine learning (ML) engineers.
Amazon SageMaker is a cloud-based machine learning (ML) platform within the AWS ecosystem that offers developers a seamless and convenient way to build, train, and deploy ML models. He focuses on architecting and implementing large-scale generative AI and classic ML pipeline solutions.
Below are the phases to make AI processes adaptable to DevOps culture: Data preparation To create a high-quality dataset, you need to convert raw data into valuable insights through machine learning. ” DataOps uses technology to automate data delivery, ensuring quality and consistency. Define objectives for DevOps teams.
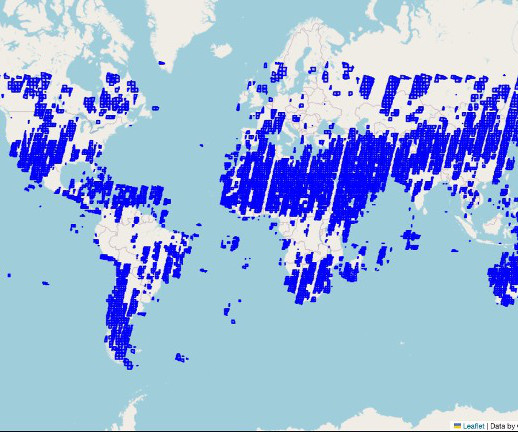
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing datascientists and ML engineers to build, train, and deploy ML models using geospatial data. Identify areas of interest We begin by illustrating how SageMaker can be applied to analyze geospatial data at a global scale.
Overview Interpretable machine learning is a critical concept every datascientist should be aware of How can you build interpretable machine learning models? The post Decoding the Black Box: An Important Introduction to Interpretable Machine Learning Models in Python appeared first on Analytics Vidhya.
Generative AI for DataScientists Specialization This specialization by IBM is designed for data professionals to learn generative AI, including prompt engineering and applying AI tools in data science.
Introduction Data Science is one of the most promising careers of 2022 and beyond. Do you know that, for the past 5 years, ‘DataScientist’ consistently ranked among the top 3 job professions in the US market? Keeping this in mind, many working professionals and students have started upskilling themselves.
Instead, businesses tend to rely on advanced tools and strategies—namely artificial intelligence for IT operations (AIOps) and machine learning operations (MLOps)—to turn vast quantities of data into actionable insights that can improve IT decision-making and ultimately, the bottom line.
Amazon SageMaker is a fully managed service that enables developers and datascientists to quickly and effortlessly build, train, and deploy machine learning (ML) models at any scale. Deploy traditional models to SageMaker endpoints In the following examples, we showcase how to use ModelBuilder to deploy traditional ML models.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. This also led to a backlog of data that needed to be ingested.
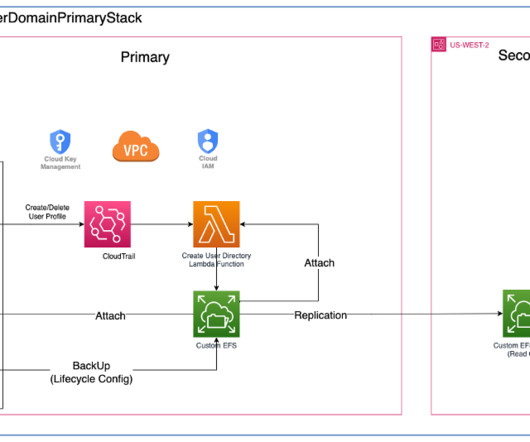
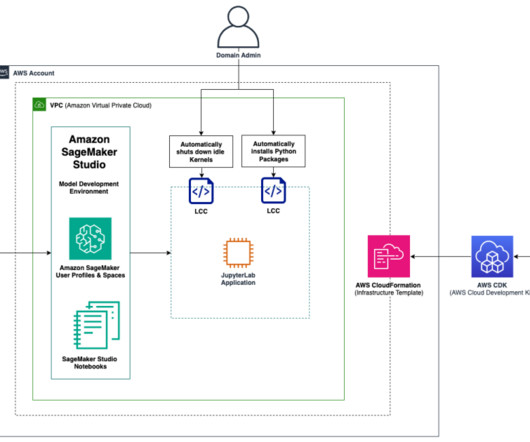
Amazon SageMaker Studio is the first integrated development environment (IDE) purposefully designed to accelerate end-to-end machine learning (ML) development. You can create multiple Amazon SageMaker domains , which define environments with dedicated data storage, security policies, and networking configurations.
Real-world applications vary in inference requirements for their artificial intelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor monitors the quality of SageMaker ML models in production. Your client applications invoke this endpoint to get inferences from the model.
The solution described in this post is geared towards machine learning (ML) engineers and platform teams who are often responsible for managing and standardizing custom environments at scale across an organization. You can use this solution to promote consistency of the analytical environments for data science teams across your enterprise.
DataScientists and AI experts: Historically we have seen DataScientists build and choose traditional ML models for their use cases. DataScientists will typically help with training, validating, and maintaining foundation models that are optimized for data tasks. IBM watsonx.ai
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content