This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction One of the key challenges in Machine Learning Model is the explainability of the ML Model that we are building. In general, ML Model is a Black Box. As Datascientists, we may understand the algorithm & statistical methods used behind the scene. […].
Uncomfortable reality: In the era of large language models (LLMs) and AutoML, traditional skills like Python scripting, SQL, and building predictive models are no longer enough for datascientist to remain competitive in the market. Coding skills remain important, but the real value of datascientists today is shifting.
Savvy datascientists are already applying artificial intelligence and machine learning to accelerate the scope and scale of data-driven decisions in strategic organizations. Datascientists are in demand: the U.S. Explore these 10 popular blogs that help datascientists drive better data decisions.
How much machine learning really is in ML Engineering? There are so many different data- and machine-learning-related jobs. But what actually are the differences between a Data Engineer, DataScientist, ML Engineer, Research Engineer, Research Scientist, or an Applied Scientist?!
The new SDK is designed with a tiered user experience in mind, where the new lower-level SDK ( SageMaker Core ) provides access to full breadth of SageMaker features and configurations, allowing for greater flexibility and control for ML engineers. 8B model using the new ModelTrainer class. amazonaws.com/pytorch-training:2.2.0-gpu-py310"
Explainable AI (XAI) aims to balance model explainability with high learning performance, fostering human understanding, trust, and effective management of AI partners. It facilitates testing performance in hypothetical scenarios, analyzing data feature importance, visualizing model behavior, and assessing fairness metrics.
As a datascientist, one of the best things about working with DataRobot customers is the sheer variety of highly interesting questions that come up. Limited history of similar regimes: because machine learning models are all about recognising patterns in historical data, new markets or assets can be very difficult for ML models.
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
The software can explain, translate, summarize, or rewrite Any piece of writing. The software can explain, translate, summarize, or rewrite Any piece of writing. Having a tool that can help comprehend complicated data is vital in the convoluted realm of scientific study. Sider Chrome Extension Excellent for dealing with text.
Datascientists and engineers frequently collaborate on machine learning ML tasks, making incremental improvements, iteratively refining ML pipelines, and checking the model’s generalizability and robustness. To build a well-documented ML pipeline, data traceability is crucial.
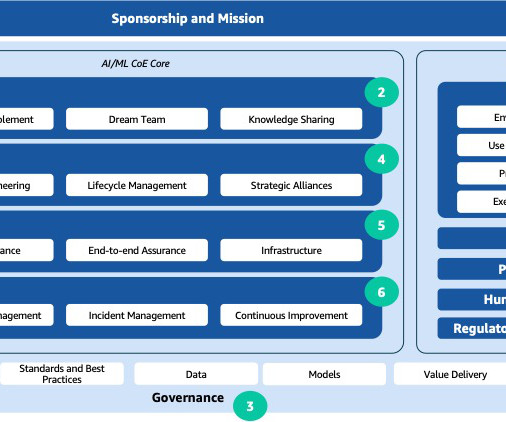
The rapid advancements in artificial intelligence and machine learning (AI/ML) have made these technologies a transformative force across industries. An effective approach that addresses a wide range of observed issues is the establishment of an AI/ML center of excellence (CoE). What is an AI/ML CoE?
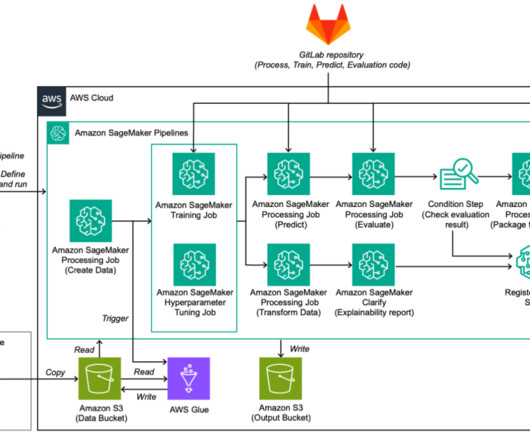
In this post, we explain how to automate this process. The solution described in this post is geared towards machine learning (ML) engineers and platform teams who are often responsible for managing and standardizing custom environments at scale across an organization. Ajay Raghunathan is a Machine Learning Engineer at AWS.
When it comes to machine learning regression models, interviewers typically focus on five key performance metrics, which are the ones mostly used by DataScientists in real time. In this article, I have explained each of these key metrics in a short and concise way, using real-life examples to make them easy to understand.
After some impressive advances over the past decade, largely thanks to the techniques of Machine Learning (ML) and Deep Learning , the technology seems to have taken a sudden leap forward. Through workload optimization an organization can reduce data warehouse costs by up to 50 percent by augmenting with this solution. [1] But why now?
These techniques include Machine Learning (ML), deep learning , Natural Language Processing (NLP) , Computer Vision (CV) , descriptive statistics, and knowledge graphs. The Need for Explainability The demand for Explainable AI arises from the opacity of AI systems, which creates a significant trust gap between users and these algorithms.
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, datascientists, and stakeholders. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value.
When it comes to machine learning regression models, interviewers typically focus on five key performance metrics, which are the ones mostly used by DataScientists in real time. In this article, I have explained each of these key metrics in a short and concise way, using real-life examples to make them easy to understand.
With the rapid advancements in machine learning (ML), there has been an increase in the demand for MLOps specialists as well. The book teaches how to build robust training loops and how to deploy scalable ML systems. The book also teaches how to design MLOps life cycle to ensure that the models are unbiased, fair, and explainable.
Increasingly, FMs are completing tasks that were previously solved by supervised learning, which is a subset of machine learning (ML) that involves training algorithms using a labeled dataset. About the Authors Jordan Knight is a Senior DataScientist working for Travelers in the Business Insurance Analytics & Research Department.
Training Sessions Bayesian Analysis of Survey Data: Practical Modeling withPyMC Allen Downey, PhD, Principal DataScientist at PyMCLabs Alexander Fengler, Postdoctoral Researcher at Brown University Bayesian methods offer a flexible and powerful approach to regression modeling, and PyMC is the go-to library for Bayesian inference in Python.
Both computer scientists and business leaders have taken note of the potential of the data. Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. MLOps is the next evolution of data analysis and deep learning. What is MLOps?
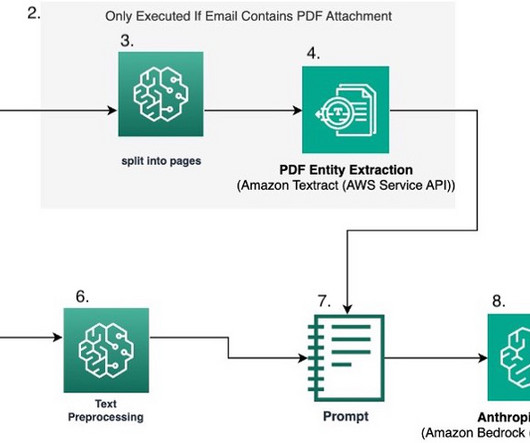
In addition to Anthropics Claude on Amazon Bedrock, the solution uses the following services: Amazon SageMaker JupyterLab The SageMakerJupyterLab application is a web-based interactive development environment (IDE) for notebooks, code, and data. He is passionate about applying cloud technologies and ML to solve real life problems.
After the launch of ChatGPT in late 2022, many companies have started to implement their own AI and ML technologies in their platforms. AI-first companies are those who in their every product and workflow implement AI and ML. In ML, Uber focuses on two domains i.e., operations and research. Such is the case for Uber.
Moreover, Multimodal AI techniques have emerged, capable of processing multiple data modalities, i.e., text, images, audio, and videos simultaneously. With these advancements, it’s natural to wonder: Are we approaching the end of traditional machine learning (ML)? What is Traditional Machine Learning?
I explore the differences between RAG and sending all data in the input and explain why we believe RAG will remain relevant for the foreseeable future. by Sachin Khandewal This blog explains different ways to query SQL Databases using Groq to access the LLMs. So, is RAG dead? Read the complete issue here!
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts. Mitigation strategies : Implementing measures to minimize or eliminate risks.
Sequence modeling uses sequentially ordered training data to teach models to predict the next element in a series, taking previous elements context and dependencies into account. It is vital in the machine learning (ML) field, inspiring numerous architectures. However, it has left datascientists without a unified framework.
Can you explain the vision behind TileDB and how it aims to revolutionize the modern database landscape? The problem is that complex data that is not naturally represented as tables is considered as “unstructured,” and is typically either stored as flat files in bespoke data formats, or managed by disparate, purpose-built databases.
Do you need help to move your organization’s Machine Learning (ML) journey from pilot to production? Most executives think ML can apply to any business decision, but on average only half of the ML projects make it to production. Challenges Customers may face several challenges when implementing machine learning (ML) solutions.
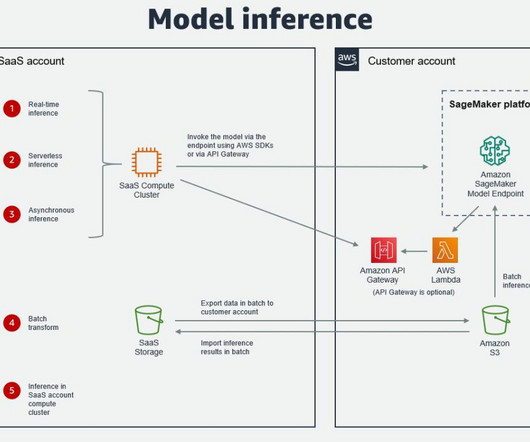
Many organizations choose SageMaker as their ML platform because it provides a common set of tools for developers and datascientists. Most of the options explained are also applicable if SageMaker is running in the SaaS AWS account. In some cases, an ISV may deploy their software in the customer AWS account.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. This is a guest post written by Axfood AB.
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. What does a modern technology stack for streamlined ML processes look like? Why: Data Makes It Different. All ML projects are software projects.
Introduction to AI and Machine Learning on Google Cloud This course introduces Google Cloud’s AI and ML offerings for predictive and generative projects, covering technologies, products, and tools across the data-to-AI lifecycle. It includes labs on feature engineering with BigQuery ML, Keras, and TensorFlow.
IBM Data Science Professional Certificate This course helps master the practical skills and knowledge necessary for a proficient datascientist. It is a beginner-friendly course that teaches the tools, languages, and libraries datascientists use, such as Python and SQL.
This mindset has followed me into my work in ML/AI. Because if companies use code to automate business rules, they use ML/AI to automate decisions. Given that, what would you say is the job of a datascientist (or ML engineer, or any other such title)? But first, let’s talk about the typical ML workflow.
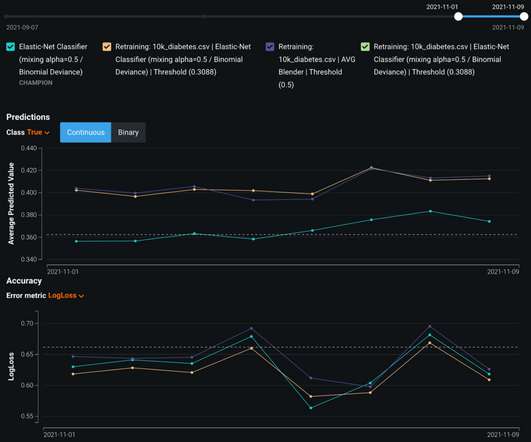
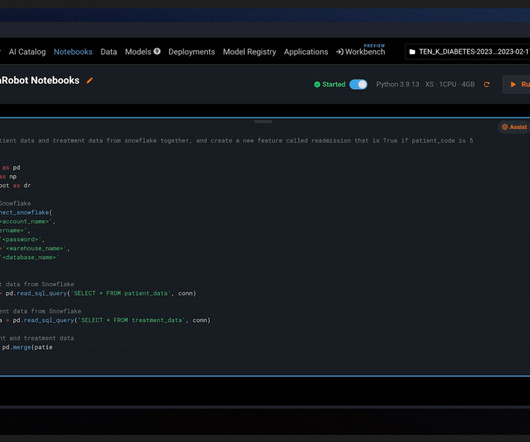
Machine learning (ML) projects are inherently complex, involving multiple intricate steps—from data collection and preprocessing to model building, deployment, and maintenance. To start our ML project predicting the probability of readmission for diabetes patients, you need to download the Diabetes 130-US hospitals dataset.
Artificial intelligence platforms enable individuals to create, evaluate, implement and update machine learning (ML) and deep learning models in a more scalable way. AI platform tools enable knowledge workers to analyze data, formulate predictions and execute tasks with greater speed and precision than they can manually.
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. SageMaker Studio set up.
Engineers who can visualize data, explain outputs, and align their work with business objectives are consistently more valuable to theirteams. Lets not forget data wrangling. Roles like DataScientist, ML Engineer, and the emerging LLM Engineer are in high demand.
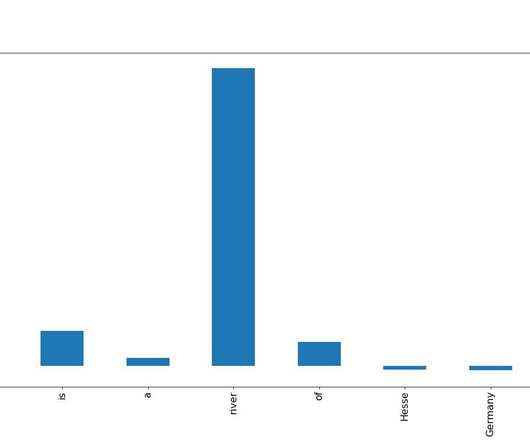
Model explainability refers to the process of relating the prediction of a machine learning (ML) model to the input feature values of an instance in humanly understandable terms. This field is often referred to as explainable artificial intelligence (XAI). In this post, we illustrate the use of Clarify for explaining NLP models.
Traditionally, developing appropriate data science code and interpreting the results to solve a use-case is manually done by datascientists. Datascientists still need to review and evaluate these results. Ultimately, users benefit from a transparent, and clear explanation of what ML predictions means to them.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content