This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machine learning (ML) has become a critical component of many organizations’ digital transformation strategy. From predicting customer behavior to optimizing business processes, ML algorithms are increasingly being used to make decisions that impact business outcomes.
Learn the basics of data engineering to improve your ML modelsPhoto by Mike Benna on Unsplash It is not news that developing Machine Learning algorithms requires data, often a lot of data. Collecting this data is not trivial, in fact, it is one of the most relevant and difficult parts of the entire workflow.
30% Off ODSC East, Fan-Favorite Speakers, Foundation Models for Times Series, and ETL Pipeline Orchestration The ODSC East 2025 Schedule isLIVE! Explore the must-attend sessions and cutting-edge tracks designed to equip AI practitioners, datascientists, and engineers with the latest advancements in AI and machine learning.
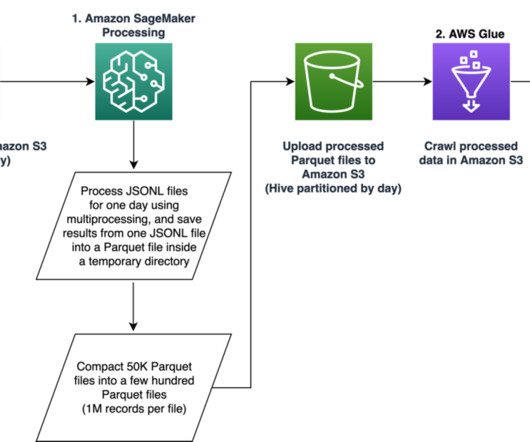
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. This post shows how we used SageMaker to build a large-scale data processing pipeline for preparing features for the job recommendation engine at Talent.com.
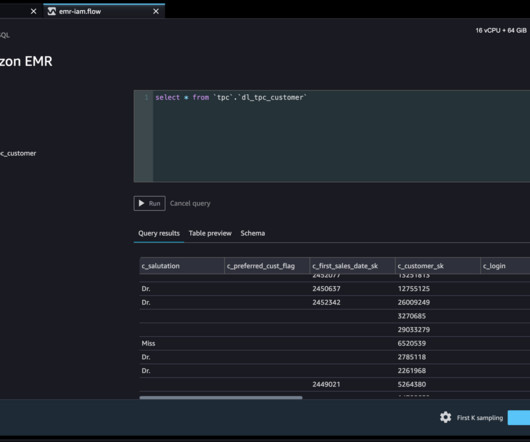
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. This also led to a backlog of data that needed to be ingested.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Db2 Warehouse fully supports open formats such as Parquet, Avro, ORC and Iceberg table format to share data and extract new insights across teams without duplication or additional extract, transform, load (ETL). This allows you to scale all analytics and AI workloads across the enterprise with trusted data.
For budding datascientists and data analysts, there are mountains of information about why you should learn R over Python and the other way around. Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the data science world can agree on, SQL.
Introduction to Data Engineering Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Datascientists often spend up to 80% of their time on data engineering in data science projects.
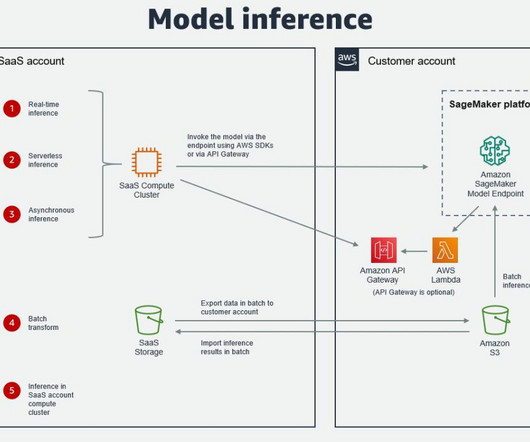
Many organizations choose SageMaker as their ML platform because it provides a common set of tools for developers and datascientists. This is usually in a dedicated customer AWS account, meaning there still needs to be cross-account access to the customer AWS account where SageMaker is running.
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
Automation has been a key trend in the past few years and that ranges from the design to building of a data warehouse to loading and maintaining, all of that can be automated. Speed Varying data formats Data publishing What are some ways that Astera has integrated AI into customer workflow?
Working as a DataScientist — Expectation versus Reality! 11 key differences in 2023 Photo by Jan Tinneberg on Unsplash Working in Data Science and Machine Learning (ML) professions can be a lot different from the expectation of it. There’s a lot more to a data science role than building ML models.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data.
Datascientists and engineers frequently collaborate on machine learning ML tasks, making incremental improvements, iteratively refining ML pipelines, and checking the model’s generalizability and robustness. To build a well-documented ML pipeline, data traceability is crucial.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. Automated development: Automates data preparation, model development, feature engineering and hyperparameter optimization using AutoAI. IBM watsonx.ai
In this first post, we introduce mobility data, its sources, and a typical schema of this data. We then discuss the various use cases and explore how you can use AWS services to clean the data, how machine learning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights.
Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. ML Engineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. The input to the training pipeline is the features dataset.
From there, I began programming liquid-handling robots and helping datascientists understand the parameters for anomaly detection, which made me more interested in programming. To address this, teams should implement robust ETL (extract, transform, load) pipelines to preprocess, clean, and align time series data.
And eCommerce companies have a ton of use cases where ML can help. The problem is, with more ML models and systems in production, you need to set up more infrastructure to reliably manage everything. And because of that, many companies decide to centralize this effort in an internal ML platform. But how to build it?
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models.
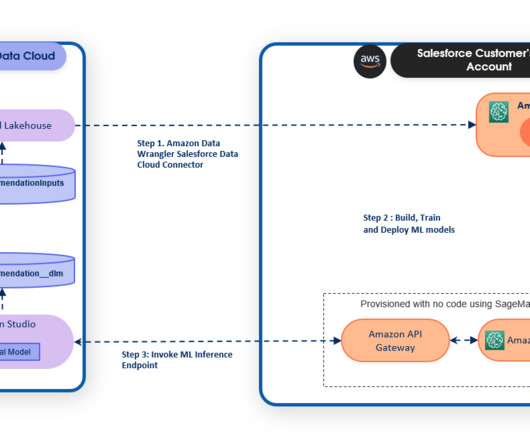
Introducing Einstein Studio on Data Cloud Data Cloud is a data platform that provides businesses with real-time updates of their customer data from any touch point. With Einstein Studio, a gateway to AI tools on the data platform, admins and datascientists can effortlessly create models with a few clicks or using code.
This situation is not different in the ML world. DataScientists and ML Engineers typically write lots and lots of code. Building a mental model for ETL components Learn the art of constructing a mental representation of the components within an ETL process.
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. Stefan: Yeah.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow datascientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
And we at deployr , worked alongside them to find the best possible answers for everyone involved and build their Data and ML Pipelines. Building data and ML pipelines: from the ground to the cloud It was the beginning of 2022, and things were looking bright after the lockdown’s end.
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently.
When it comes to data complexity, it is for sure that in machine learning, we are dealing with much more complex data. First of all, machine learning engineers and datascientists often use data from different data vendors. Some data sets are being corrected by data entry specialists and manual inspectors.
This includes the tools and techniques we used to streamline the ML model development and deployment processes, as well as the measures taken to monitor and maintain models in a production environment. Costs: Oftentimes, cost is the most important aspect of any ML model deployment. This includes data quality, privacy, and compliance.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, datascientists typically start their workflow by discovering relevant data sources and connecting to them.
The company’s H20 Driverless AI streamlines AI development and predictive analytics for professionals and citizen datascientists through open source and customized recipes. The platform makes collaborative data science better for corporate users and simplifies predictive analytics for professional datascientists.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction.
They learn the complete data analysis process, including data wrangling, exploration, visualization using Matplotlib and Seaborn, and effective communication of findings. Real-world projects provide hands-on experience in investigating datasets and performing advanced data-wrangling tasks.
Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of DataScientists , Data Engineers and Data Analysts to include in your team? The Data Engineer Not everyone working on a data science project is a datascientist.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply Machine Learning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. So ML ends up being a huge part of many large companies’ core functions. Why is this important?
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply Machine Learning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. So ML ends up being a huge part of many large companies’ core functions. Why is this important?
About the authors Samantha Stuart is a DataScientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements. He has touched on most aspects of these projects, from infrastructure and DevOps to software development and AI/ML.
The rules in this engine were predefined and written in SQL, which aside from posing a challenge to manage, also struggled to cope with the proliferation of data from TR’s various integrated data source. TR customer data is changing at a faster rate than the business rules can evolve to reflect changing customer needs.
There are various architectural design patterns in data engineering that are used to solve different data-related problems. This article discusses five commonly used architectural design patterns in data engineering and their use cases. Finally, the transformed data is loaded into the target system.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply Machine Learning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. So ML ends up being a huge part of many large companies’ core functions. Why is this important?
And because it takes more than technologies and processes to succeed with MLOps, he will also share details on: 1 Brainly’s ML use cases, 2 MLOps culture, 3 Team structure, 4 And technologies Brainly uses to deliver AI services to its clients, Enjoy the article! Multiple AI teams also contribute to ML infrastructure initiatives.
Nevertheless, many datascientists will agree that they can be really valuable – if used well. And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & ML Engineering. Data on its own is not sufficient for a cohesive story. Aside neptune.ai
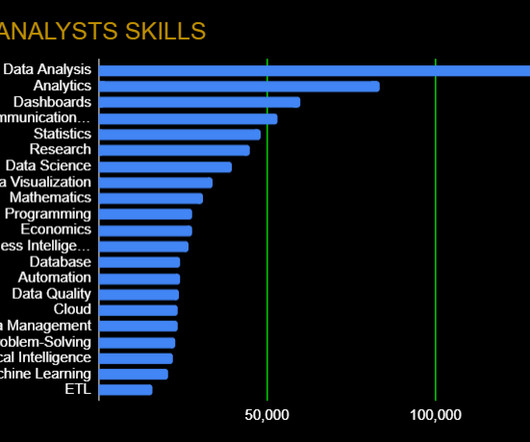
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
A unified data fabric also enhances data security by enabling centralised governance and compliance management across all platforms. Automated Data Integration and ETL Tools The rise of no-code and low-code tools is transforming data integration and Extract, Transform, and Load (ETL) processes.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content