This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon A datascientist’s ability to extract value from data is closely related to how well-developed a company’s data storage and processing infrastructure is.
This article was published as a part of the Data Science Blogathon. Introduction Datascientists, engineers, and BI analysts often need to analyze, process, or query different data sources.
For example, recently, I started working on developing a model in an open-science manner for the European Space Agency for fine-tuning an LLM on data concerning earth observation and earth science. The whole thing is very exciting, but where do I get the data from?
30% Off ODSC East, Fan-Favorite Speakers, Foundation Models for Times Series, and ETL Pipeline Orchestration The ODSC East 2025 Schedule isLIVE! Explore the must-attend sessions and cutting-edge tracks designed to equip AI practitioners, datascientists, and engineers with the latest advancements in AI and machine learning.
But trust isn’t important only for executives; before executive trust can be established, datascientists and citizen datascientists who create and work with ML models must have faith in the data they’re using. This can lead to more accurate predictions and better decision-making.
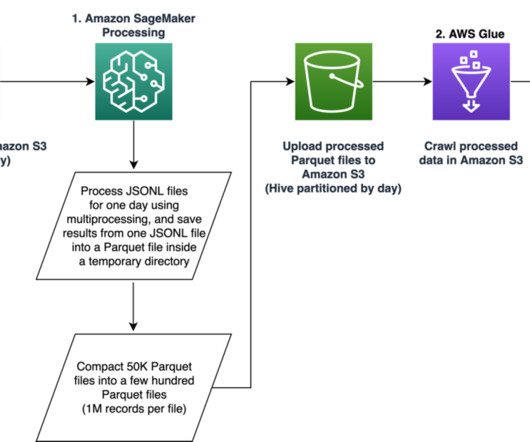
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. This post shows how we used SageMaker to build a large-scale data processing pipeline for preparing features for the job recommendation engine at Talent.com.
For budding datascientists and data analysts, there are mountains of information about why you should learn R over Python and the other way around. Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the data science world can agree on, SQL.
Db2 Warehouse fully supports open formats such as Parquet, Avro, ORC and Iceberg table format to share data and extract new insights across teams without duplication or additional extract, transform, load (ETL). This allows you to scale all analytics and AI workloads across the enterprise with trusted data.
This also led to a backlog of data that needed to be ingested. Steep learning curve for datascientists: Many of Rockets datascientists did not have experience with Spark, which had a more nuanced programming model compared to other popular ML solutions like scikit-learn.
Introduction to Data Engineering Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Datascientists often spend up to 80% of their time on data engineering in data science projects.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
Meet Lightski , an AI-powered startup that lets anyone feel like a datascientist in no time—regardless of their coding skills. By integrating ChatGPT Code Interpreter with your app, Lightski can provide your users with an artificial intelligence/ datascientist superior to Excel.
This skill is essential for efficiently managing and extracting value from large volumes of data, enabling businesses to stay competitive and innovative in their industries. By the end, you’ll be equipped to design and manage complex data solutions on the Azure platform.
Working as a DataScientist — Expectation versus Reality! 11 key differences in 2023 Photo by Jan Tinneberg on Unsplash Working in Data Science and Machine Learning (ML) professions can be a lot different from the expectation of it. As I was working on these projects, I knew I wanted to work as a DataScientist once I graduate.
Automation has been a key trend in the past few years and that ranges from the design to building of a data warehouse to loading and maintaining, all of that can be automated. So pretty much what is available to a developer or datascientist who is working with the open source libraries and going through their own data science journey.
Data engineering can be interpreted as learning the moral of the story. Welcome to the mini tour of data engineering where we will discover how a data engineer is different from a datascientist and analyst. Processes like exploring, cleaning, and transforming the data that make the data as efficient as possible.
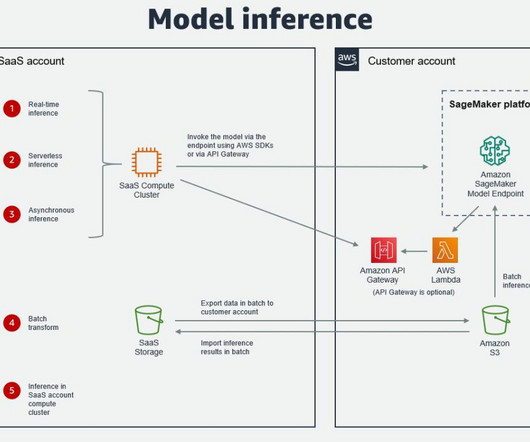
In addition to the challenge of defining the features for the ML model, it’s critical to automate the feature generation process so that we can get ML features from the raw data for ML inference and model retraining. The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account.
From there, I began programming liquid-handling robots and helping datascientists understand the parameters for anomaly detection, which made me more interested in programming. To address this, teams should implement robust ETL (extract, transform, load) pipelines to preprocess, clean, and align time series data.
This is part of the Full Stack DataScientist blog series. Building end-to-end data science solutions means developing data collection, feature engineering, model building and model serving processes. If you’re looking to do more with your data, please get in touch via our website.
Datascientists and engineers frequently collaborate on machine learning ML tasks, making incremental improvements, iteratively refining ML pipelines, and checking the model’s generalizability and robustness. To minimize the possibility of mistakes, the user must repeat and check each step of the machine-learning workflow.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities.
To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings. Datascientists can accomplish this process by connecting through Amazon SageMaker notebooks.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data. Big Data Architect. Zach Mitchell is a Sr.
DataScientists and ML Engineers typically write lots and lots of code. From writing code for doing exploratory analysis, experimentation code for modeling, ETLs for creating training datasets, Airflow (or similar) code to generate DAGs, REST APIs, streaming jobs, monitoring jobs, etc.
An ML model registered by a datascientist needs an approver to review and approve before it is used for an inference pipeline and in the next environment level (test, UAT, or production). When datascientists develop a model, they register it to the SageMaker Model Registry with the model status of PendingManualApproval.
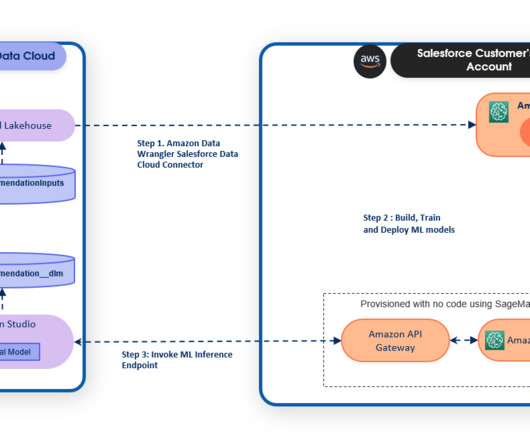
Introducing Einstein Studio on Data Cloud Data Cloud is a data platform that provides businesses with real-time updates of their customer data from any touch point. With Einstein Studio, a gateway to AI tools on the data platform, admins and datascientists can effortlessly create models with a few clicks or using code.
Unfolding the difference between data engineer, datascientist, and data analyst. Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Role of DataScientistsDataScientists are the architects of data analysis.
Data Science focuses on analysing data to find patterns and make predictions. Data engineering, on the other hand, builds the foundation that makes this analysis possible. Without well-structured data, DataScientists cannot perform their work efficiently.
Data engineering is a rapidly growing field, and there is a high demand for skilled data engineers. If you are a datascientist, you may be wondering if you can transition into data engineering. The good news is that there are many skills that datascientists already have that are transferable to data engineering.
Many organizations choose SageMaker as their ML platform because it provides a common set of tools for developers and datascientists. Alternatively, a service such as AWS Glue or a third-party extract, transform, and load (ETL) tool can be used for data transfer.
Collaboration – Datascientists each worked on their own local Jupyter notebooks to create and train ML models. They lacked an effective method for sharing and collaborating with other datascientists. This has helped the datascientist team to create and test pipelines at a much faster pace.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow datascientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
You can take two different approaches to ingest training data: Batch ingestion – You can use AWS Glue to transform and ingest interactions and items data residing in an Amazon Simple Storage Service (Amazon S3) bucket into Amazon Personalize datasets. Happy building!
Its guidance can help understand data patterns, missing numbers, and other data features better. Datascientists, engineers, and business users can construct and execute cleansing rules on a target database. Data transformation, enrichment, and management across business landscapes are all within the user’s reach.
Set specific, measurable targets Data science goals to “increase sales” lack the clarity needed to evaluate success and secure ongoing funding. Audit existing data assets Inventory internal datasets, ETL capabilities, past analytical initiatives, and available skill sets. Complexity limits accessibility and value creation.
They learn the complete data analysis process, including data wrangling, exploration, visualization using Matplotlib and Seaborn, and effective communication of findings. Real-world projects provide hands-on experience in investigating datasets and performing advanced data-wrangling tasks.
In contrast, data warehouses and relational databases adhere to the ‘Schema-on-Write’ model, where data must be structured and conform to predefined schemas before being loaded into the database. Schema Enforcement: Data warehouses use a “schema-on-write” approach.
The company’s H20 Driverless AI streamlines AI development and predictive analytics for professionals and citizen datascientists through open source and customized recipes. The platform makes collaborative data science better for corporate users and simplifies predictive analytics for professional datascientists.
Collaboration : Ensuring that all teams involved in the project, including datascientists, engineers, and operations teams, are working together effectively. Two DataScientists: Responsible for setting up the ML models training and experimentation pipelines. We primarily used ETL services offered by AWS.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, datascientists typically start their workflow by discovering relevant data sources and connecting to them.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
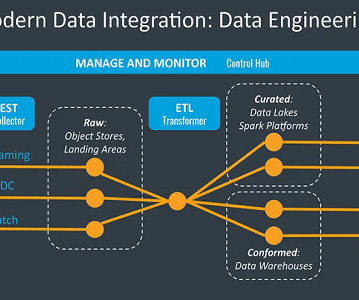
There are various architectural design patterns in data engineering that are used to solve different data-related problems. This article discusses five commonly used architectural design patterns in data engineering and their use cases. Finally, the transformed data is loaded into the target system.
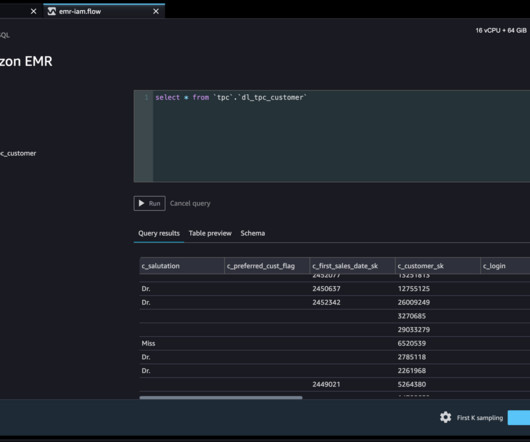
We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction. To demonstrate fine-grained data access permissions, we consider the following two users: David, a datascientist on the marketing team.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content