This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. Generate metadata for the page. Generate metadata for the full document. Upload the content and metadata to Amazon S3.
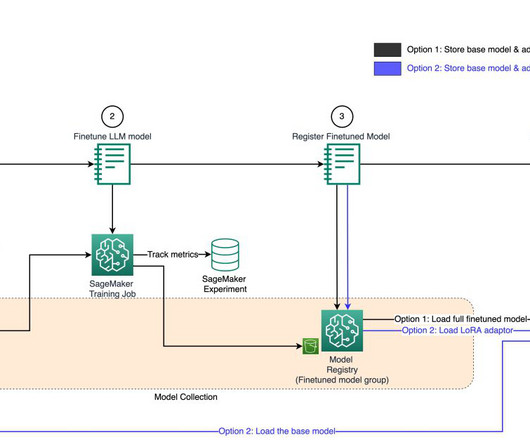
The functional architecture with different capabilities is implemented using a number of AWS services, including AWS Organizations , Amazon SageMaker , AWS DevOps services, and a data lake. Solution overview The following diagram illustrates the ML platform reference architecture using various AWS services.
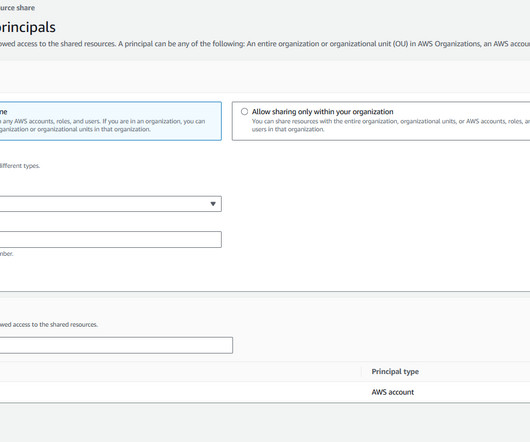
The steering committee or governance council can establish data governance policies around privacy, retention, access and security while defining data management standards to streamline processes and certify consistency and compliance as new data is introduced.
DataScientist at AWS, bringing a breadth of data science, ML engineering, MLOps, and AI/ML architecting to help businesses create scalable solutions on AWS. He is a technology enthusiast and a builder with a core area of interest in AI/ML, data analytics, serverless, and DevOps. About the Authors Joe King is a Sr.
The use of multiple external cloud providers complicated DevOps, support, and budgeting. This includes file type verification, size validation, and metadata extraction before routing to Amazon Textract. The extracted content is stored in a dedicated S3 prefix, separate from the source documents, maintaining clear data lineage.
Lived through the DevOps revolution. Founded neptune.ai , a modular MLOps component for ML metadata store , aka “experiment tracker + model registry”. If you’d like a TLDR, here it is: MLOps is an extension of DevOps. There will be only one type of ML metadata store (model-first), not three. Came to ML from software.
It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. After being tested locally or as a training job, a datascientist or practitioner who is an expert on SageMaker can convert the function to a SageMaker pipeline step by adding a @step decorator.
DevOps engineers often use Kubernetes to manage and scale ML applications, but before an ML model is available, it must be trained and evaluated and, if the quality of the obtained model is satisfactory, uploaded to a model registry. curl for transmitting data with URLs. They often work with DevOps engineers to operate those pipelines.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. It provides a high-level API that makes it easy to define and execute data science workflows.
Many businesses already have datascientists and ML engineers who can build state-of-the-art models, but taking models to production and maintaining the models at scale remains a challenge. Machine learning operations (MLOps) applies DevOps principles to ML systems.
It combines principles from DevOps, such as continuous integration, continuous delivery, and continuous monitoring, with the unique challenges of managing machine learning models and datasets. Model Training Frameworks This stage involves the process of creating and optimizing predictive models with labeled and unlabeled data.
The functional architecture with different capabilities is implemented using a number of AWS services, including AWS Organizations , SageMaker, AWS DevOps services, and a data lake. Datascientists from ML teams across different business units federate into their team’s development environment to build the model pipeline.
Best-Practice Compliance and Governance: Businesses need to know that their DataScientists are delivering models that they can trust and defend over time. This means implementing safety best practices proactively, and applying the highest governance standards without slowing down the process.
The output of a SageMaker Ground Truth labeling job is a file in JSON-lines format containing the labels and additional metadata. With a passion for automation, Joerg has worked as a software developer, DevOps engineer, and Site Reliability Engineer in his pre-AWS life.
The examples focus on questions on chunk-wise business knowledge while ignoring irrelevant metadata that might be contained in a chunk. About the authors Samantha Stuart is a DataScientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements.
In addition to data engineers and datascientists, there have been inclusions of operational processes to automate & streamline the ML lifecycle. Model cards are intended to be a single source of truth for business and technical metadata about the model that can reliably be used for auditing and documentation purposes.
These data owners are focused on providing access to their data to multiple business units or teams. Data science team – Datascientists need to focus on creating the best model based on predefined key performance indicators (KPIs) working in notebooks. The following figure depicts an example architecture.
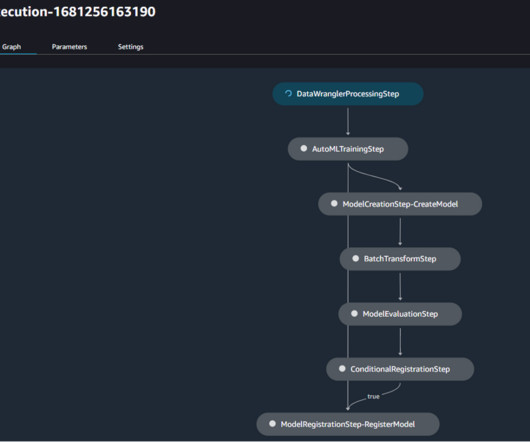
model.create() creates a model entity, which will be included in the custom metadata registered for this model version and later used in the second pipeline for batch inference and model monitoring. In Studio, you can choose any step to see its key metadata. large", accelerator_type="ml.eia1.medium", large", accelerator_type="ml.eia1.medium",
As an MLOps engineer on your team, you are often tasked with improving the workflow of your datascientists by adding capabilities to your ML platform or by building standalone tools for them to use. And since you are reading this article, the datascientists you support have probably reached out for help.
The metadata store is where MLflow keeps the experiment and model metadata. In my experience, even solo datascientists prefer setting up a tracking server rather than directly interfacing with metadata and artifact stores. The artifact store is where models and other large binary artifacts are saved.
Datascientists, ML engineers, IT staff, and DevOps teams must work together to operationalize models from research to deployment and maintenance. The model registry maintains records of model versions, their associated artifacts, lineage, and metadata.
This data version is frequently recorded into your metadata management solution to ensure that your model training is versioned and repeatable. It’s time to examine the best data version control tools on the market so you can keep track of each component of your code. Using Delta makes upserts straightforward.
MLflow is an open-source platform designed to manage the entire machine learning lifecycle, making it easier for ML Engineers, DataScientists, Software Developers, and everyone involved in the process. MLflow can be seen as a tool that fits within the MLOps (synonymous with DevOps) framework.
It provides the flexibility to log your model metrics, parameters, files, artifacts, plot charts from the different metrics, capture various metadata, search through them and support model reproducibility. Datascientists can quickly compare the performance and hyperparameters for model evaluation through visual charts and tables.
Stefan is a software engineer, datascientist, and has been doing work as an ML engineer. He also ran the data platform in his previous company and is also co-creator of open-source framework, Hamilton. To a junior datascientist, it doesn’t matter if you’re using Airflow, Prefect , Dexter.
Source Model packaging is a process that involves packaging model artifacts, dependencies, configuration files, and metadata into a single format for effortless distribution, installation, and reuse. These teams may include but are not limited to datascientists, software developers, machine learning engineers, and DevOps engineers.
So I tell people honestly, I’ve spent the last eight years working up and down the data and ML value chain effectively – a fancy way of saying “job hopping.” How to transition from data analytics to MLOps engineering Piotr: Miki, you’ve been a datascientist, right? Quite fun, quite chaotic at times.
In addition to data engineers and datascientists, there have been inclusions of operational processes to automate & streamline the ML lifecycle. Model cards are intended to be a single source of truth for business and technical metadata about the model that can reliably be used for auditing and documentation purposes.
quality attributes) and metadata enrichment (e.g., The DevOps and Automation Ops departments are under the infrastructure team. Machine learning use cases at Brainly The AI department at Brainly aims to build a predictive intervention system for its users. On top of the teams, they also have departments.
The platform typically includes components for the ML ecosystem like data management, feature stores, experiment trackers, a model registry, a testing environment, model serving, and model management. It checks the data for quality issues and detects outliers and anomalies. How long does it take to return a prediction?
Amazon SageMaker is a fully managed service to prepare data and build, train, and deploy machine learning (ML) models for any use case with fully managed infrastructure, tools, and workflows. This is where datascientists can choose a template and have their ML workflow bootstrapped and preconfigured.
Akshit Arora is a senior datascientist at NVIDIA, where he works on deploying conversational AI models on GPUs at scale. He’s a graduate of University of Colorado at Boulder, where he applied deep learning to improve knowledge tracking on a K-12 online tutoring platform.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for datascientists and ML engineers to build and deploy models at scale.
Historically at TR, ML has been a capability for teams with advanced datascientists and engineers. TR’s AI Platform microservices are built with Amazon SageMaker as the core engine, AWS serverless components for workflows, and AWS DevOps services for CI/CD practices. Data service. The challenges.
Datascientists can analyze detailed results with SageMaker Clarify visualizations in Notebooks, SageMaker Model Cards, and PDF reports. The following figure shows the end-to-end MLOps lifecycle: A typical journey starts with a datascientist creating a proof-of-concept (PoC) notebook to prove that ML can solve a business problem.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content