This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for DataScience and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for data scientists and machine learning (ML) engineers.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. The solution in this post aims to bring enterprise analytics operations to the next level by shortening the path to your data using natural language. Today, generative AI can enable people without SQL knowledge.
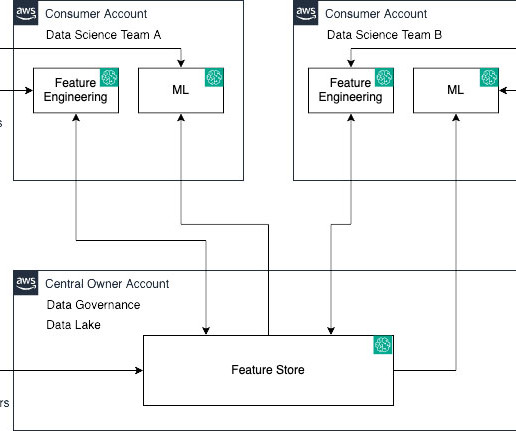
Data scientists search and pull features from the central feature store catalog, build models through experiments, and select the best model for promotion. Data scientists create and share new features into the central feature store catalog for reuse.
Data preparation isn’t just a part of the MLengineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. Writing Output: Centralizing data into a structure, like a delta table.
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy datascience projects.
Secondly, to be a successful MLengineer in the real world, you cannot just understand the technology; you must understand the business. We should start by considering the broad elements that should constitute any ML solution, as indicated in the following diagram: Figure 1.2:
It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. The SageMaker Pipelines decorator feature helps convert local ML code written as a Python program into one or more pipeline steps. SageMaker Pipelines can handle model versioning and lineage tracking.
ML Governance: A Lean Approach Ryan Dawson | Principal DataEngineer | Thoughtworks Meissane Chami | Senior MLEngineer | Thoughtworks During this session, you’ll discuss the day-to-day realities of ML Governance. Some of the questions you’ll explore include How much documentation is appropriate?
Amazon SageMaker provides purpose-built tools for machine learning operations (MLOps) to help automate and standardize processes across the ML lifecycle. In this post, we describe how Philips partnered with AWS to develop AI ToolSuite—a scalable, secure, and compliant ML platform on SageMaker.
Let’s demystify this using the following personas and a real-world analogy: Data and MLengineers (owners and producers) – They lay the groundwork by feeding data into the feature store Data scientists (consumers) – They extract and utilize this data to craft their models Dataengineers serve as architects sketching the initial blueprint.
In this post, we provide best practices to maximize the value of SageMaker HyperPod task governance and make the administration and datascience experiences seamless. Access control When working with SageMaker HyperPod task governance, data scientists will assume their specific role.
Specialist DataEngineering at Merck, and Prabakaran Mathaiyan, Sr. MLEngineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. This post is co-written with Jayadeep Pabbisetty, Sr.
You can use this framework as a starting point to monitor your custom metrics or handle other unique requirements for model quality monitoring in your AI/ML applications. Data Scientist at AWS, bringing a breadth of datascience, MLengineering, MLOps, and AI/ML architecting to help businesses create scalable solutions on AWS.
Model cards are intended to be a single source of truth for business and technical metadata about the model that can reliably be used for auditing and documentation purposes. Depending on your governance requirements, DataScience & Dev accounts can be merged into a single AWS account.
Came to ML from software. Founded neptune.ai , a modular MLOps component for MLmetadata store , aka “experiment tracker + model registry”. Most of our customers are doing ML/MLOps at a reasonable scale, NOT at the hyperscale of big-tech FAANG companies. . – How about the MLengineer? Let me explain.
Topics Include: Agentic AI DesignPatterns LLMs & RAG forAgents Agent Architectures &Chaining Evaluating AI Agent Performance Building with LangChain and LlamaIndex Real-World Applications of Autonomous Agents Who Should Attend: Data Scientists, Developers, AI Architects, and MLEngineers seeking to build cutting-edge autonomous systems.
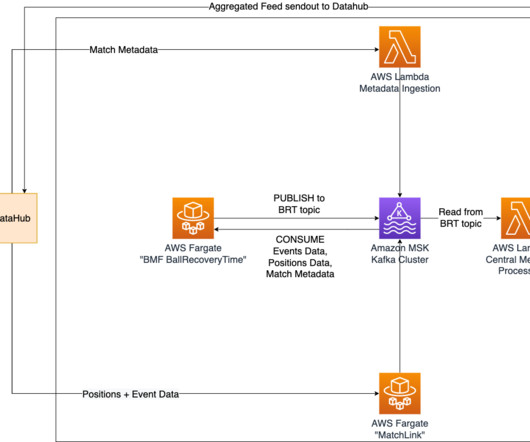
This allows for seamless communication of positional data and various outputs of Bundesliga Match Facts between containers in real time. The match-related data is collected and ingested using DFL’s DataHub. Both the Lambda function and the Fargate container publish the data for further consumption in the relevant MSK topics.
Additionally, you can enable model invocation logging to collect invocation logs, full request response data, and metadata for all Amazon Bedrock model API invocations in your AWS account. Leveraging her expertise in Computer Vision and Deep Learning, she empowers customers to harness the power of the ML in AWS cloud efficiently.
ML operations, known as MLOps, focus on streamlining, automating, and monitoring ML models throughout their lifecycle. Data scientists, MLengineers, IT staff, and DevOps teams must work together to operationalize models from research to deployment and maintenance.
Solution overview The ML solution for LTV forecasting is composed of four components: the training dataset ETL pipeline, MLOps pipeline, inference dataset ETL pipeline, and ML batch inference. MLengineers no longer need to manage this training metadata separately.
MLflow is an open-source platform designed to manage the entire machine learning lifecycle, making it easier for MLEngineers, Data Scientists, Software Developers, and everyone involved in the process. MLOps aims to automate and operationalize ML models, enabling smoother transitions to production and deployment.
Model cards are intended to be a single source of truth for business and technical metadata about the model that can reliably be used for auditing and documentation purposes. Depending on your governance requirements, DataScience & Dev accounts can be merged into a single AWS account.
So I was able to get from growth hacking to data analytics, then data analytics to datascience, and then datascience to MLOps. I switched from analytics to datascience, then to machine learning, then to dataengineering, then to MLOps. How do I get this model in production?
This is Piotr Niedźwiedź and Aurimas Griciūnas from neptune.ai , and you’re listening to ML Platform Podcast. Stefan is a software engineer, data scientist, and has been doing work as an MLengineer. As you’ve been running the MLdata platform team, how do you do that? Stefan: Yeah.
These data owners are focused on providing access to their data to multiple business units or teams. Datascience team – Data scientists need to focus on creating the best model based on predefined key performance indicators (KPIs) working in notebooks.
One of the most prevalent complaints we hear from MLengineers in the community is how costly and error-prone it is to manually go through the ML workflow of building and deploying models. Building end-to-end machine learning pipelines lets MLengineers build once, rerun, and reuse many times. Kale v0.7.0.
However, model governance functions in an organization are centralized and to perform those functions, teams need access to metadata about model lifecycle activities across those accounts for validation, approval, auditing, and monitoring to manage risk and compliance. An experiment collects multiple runs with the same objective.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and MLengineers to build and deploy models at scale.
Enabling such a secure, compliant environment in the cloud within minutes relieves data scientists from the burden of handling cloud infrastructure, networking requirements, and security standards measures, to focus instead on the datascience problem. The following diagram illustrates this architecture. Model deployment.
SageMaker Projects helps organizations set up and standardize environments for automating different steps involved in an ML lifecycle. Although notebooks are helpful for model building and experimentation, a team of data scientists and MLengineers sharing code need a more scalable way to maintain code consistency and strict version control.
You can now register machine learning (ML) models in Amazon SageMaker Model Registry with Amazon SageMaker Model Cards , making it straightforward to manage governance information for specific model versions directly in SageMaker Model Registry in just a few clicks.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content