This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
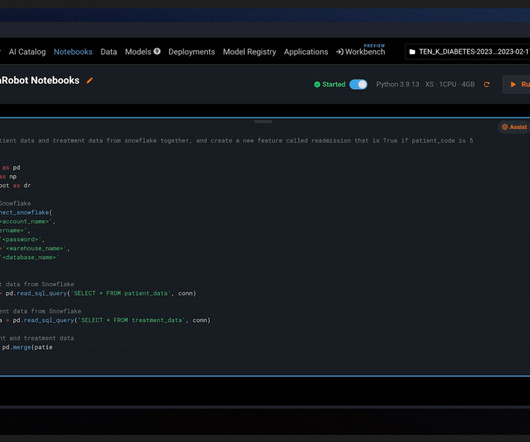
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
This article was published as a part of the DataScience Blogathon. A centralized location for research and production teams to govern models and experiments by storing metadata throughout the ML model lifecycle. A Metadata Store for MLOps appeared first on Analytics Vidhya. Keeping track of […].
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for DataScience and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for data scientists and machine learning (ML) engineers.
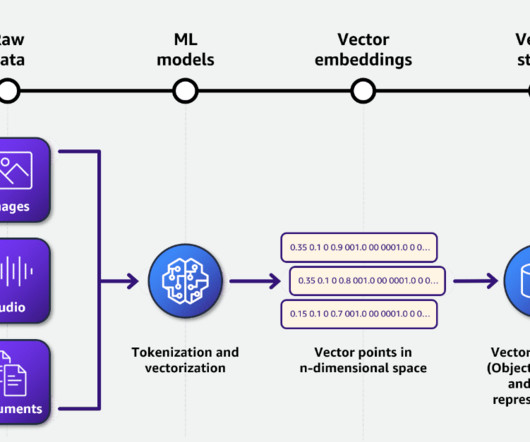
After decades of digitizing everything in your enterprise, you may have an enormous amount of data, but with dormant value. However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data. The solution integrates data in three tiers.
A data lakehouse architecture combines the performance of data warehouses with the flexibility of data lakes, to address the challenges of today’s complex data landscape and scale AI. New insights and relationships are found in this combination. All of this supports the use of AI.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
It drives an AI governance solution without the excessive costs of switching from your current datascience platform. The resulting automation drives scalability and accountability by capturing model development time and metadata, offering post-deployment model monitoring, and allowing for customized workflows.
Source Purpose of Using DevSecOps in Traditional and ML Applications The DevSecOps practices are different in traditional and ML applications as each comes with different challenges. The characteristics which we saw for DevSecOps for traditional applications also apply to ML-based applications.
Real-world applications vary in inference requirements for their artificial intelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor monitors the quality of SageMaker ML models in production. Your client applications invoke this endpoint to get inferences from the model.
A/B testing and experimentation Datascience teams can systematically evaluate different model-tool combinations, measure performance metrics, and analyze response patterns in controlled environments. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
Traditionally, developing appropriate datascience code and interpreting the results to solve a use-case is manually done by data scientists. The integration allows you to generate intelligent datascience code that reflects your use case. Data scientists still need to review and evaluate these results.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance framework ensures the ethical, responsible and transparent use of AI and machine learning (ML). Capture and document model metadata for report generation.
Users without datascience or analytics experience can generate rigorous data-backed predictions to answer big questions like time-to-fill for important positions, or resignation risk for crucial employees. The datascience team couldn’t roll out changes independently to production.
After some impressive advances over the past decade, largely thanks to the techniques of Machine Learning (ML) and Deep Learning , the technology seems to have taken a sudden leap forward. Through workload optimization an organization can reduce data warehouse costs by up to 50 percent by augmenting with this solution. [1] But why now?
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. foundation models to help users discover, augment, and enrich data with natural language. IBM watsonx.ai Later this year, it will leverage watsonx.ai
SageMaker JumpStart is a machine learning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account. It’s serverless so you don’t have to manage the infrastructure.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. The solution in this post aims to bring enterprise analytics operations to the next level by shortening the path to your data using natural language. Today, generative AI can enable people without SQL knowledge.
You can use Amazon SageMaker Model Building Pipelines to collaborate between multiple AI/ML teams. SageMaker Pipelines You can use SageMaker Pipelines to define and orchestrate the various steps involved in the ML lifecycle, such as data preprocessing, model training, evaluation, and deployment.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. Embedding is usually performed by a machine learning (ML) model. Streamlit This open source Python library makes it straightforward to create and share beautiful, custom web apps for ML and datascience.
In this post, we provide best practices to maximize the value of SageMaker HyperPod task governance and make the administration and datascience experiences seamless. Access control When working with SageMaker HyperPod task governance, data scientists will assume their specific role.
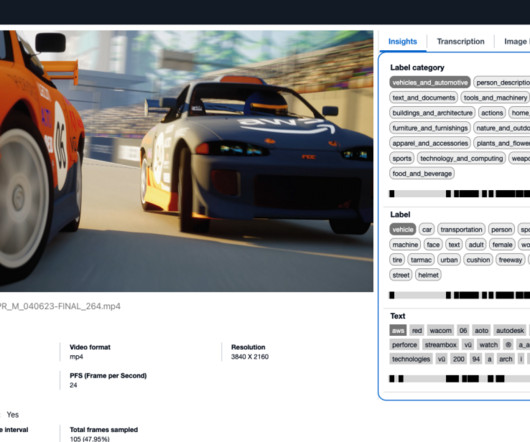
Each frame will be analyzed using Amazon Rekognition and Amazon Bedrock for metadata extraction. Policy evaluation – Using the extracted metadata from the video, the system conducts LLM evaluation. An Amazon OpenSearch Service cluster stores the extracted video metadata and facilitates users’ search and discovery needs.
It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model. He solves complex organizational and technical challenges using datascience and engineering. In addition, he builds and deploys AI/ML models on the AWS Cloud.
IDC 2 predicts that by 2024, 60% of enterprises would have operationalized their ML workflows by using MLOps. The same is true for your ML workflows – you need the ability to navigate change and make strong business decisions. These and many other questions are now on top of the agenda of every datascience team.
Secondly, to be a successful ML engineer in the real world, you cannot just understand the technology; you must understand the business. Some typical examples are given in the following table, along with some discussion as to whether or not ML would be an appropriate tool for solving the problem: Figure 1.1:
Amazon Kendra also supports the use of metadata for each source file, which enables both UIs to provide a link to its sources, whether it is the Spack documentation website or a CloudFront link. Furthermore, Amazon Kendra supports relevance tuning , enabling boosting certain data sources.
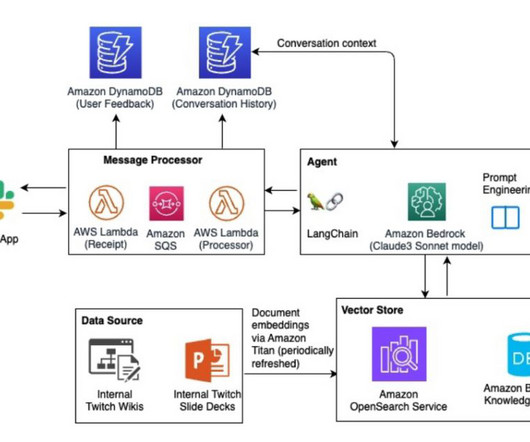
We discuss the solution components to build a multimodal knowledge base, drive agentic workflow, use metadata to address hallucinations, and also share the lessons learned through the solution development using multiple large language models (LLMs) and Amazon Bedrock Knowledge Bases. Yunfei Bai is a Principal Solutions Architect at AWS.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. The pipeline ensures correct, complete, and consistent data.
With “Science of Gaming” as their core philosophy, they have enabled a vision of end-to-end informatics around game dynamics, game platforms, and players by consolidating orthogonal research directions of game AI, game datascience, and game user research. The already existing solution through Step Functions had limitations.
Data preparation isn’t just a part of the ML engineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. Data is a key differentiator in ML projects (more on this in my blog post below).
Learn about the flow, difficulties, and tools for performing ML clustering at scale Ori Nakar | Principal Engineer, Threat Research | Imperva Given that there are billions of daily botnet attacks from millions of different IPs, the most difficult challenge of botnet detection is choosing the most relevant data.
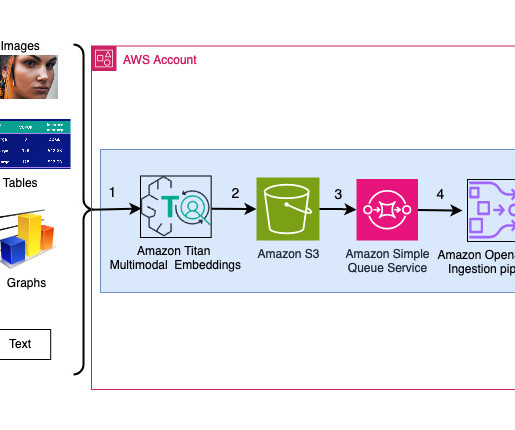
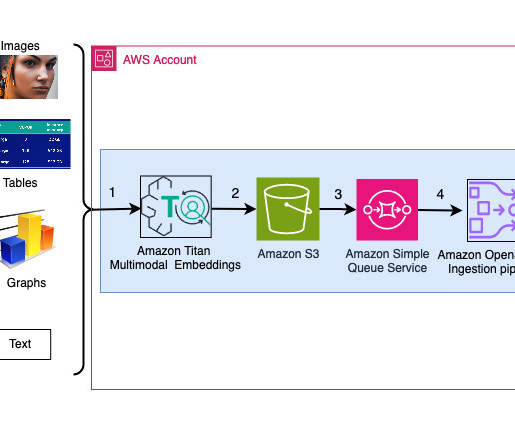
We add additional metadata fields to perform rich search queries using OpenSearch’s powerful search capabilities. The OSI pipeline ingests the data as documents into an OpenSearch Serverless index. The sample deck has 31 slides, therefore we generate 31 sets of vector embeddings, each with 1536 dimensions.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. For information about model pricing, refer to Amazon Bedrock pricing.
TL;DR Using CI/CD workflows to run ML experiments ensures their reproducibility, as all the required information has to be contained under version control. The compute resources offered by GitHub Actions directly are not suitable for larger-scale ML workloads. ML experiments are, by nature, full of uncertainty and surprises.
If you are a returning user to SageMaker Studio, in order to ensure Salesforce Data Cloud is enabled, upgrade to the latest Jupyter and SageMaker Data Wrangler kernels. This completes the setup to enable data access from Salesforce Data Cloud to SageMaker Studio to build AI and machine learning (ML) models.
Utilizing data streamed through LnW Connect, L&W aims to create better gaming experience for their end-users as well as bring more value to their casino customers. Predictive maintenance is a common ML use case for businesses with physical equipment or machinery assets.
However, managing machine learning projects can be challenging, especially as the size and complexity of the data and models increase. Without proper tracking, optimization, and collaboration tools, ML practitioners can quickly become overwhelmed and lose track of their progress. This is where Comet comes in.
We add additional metadata fields to these generated vector embeddings and create a JSON file. These additional metadata fields can be used to perform rich search queries using OpenSearch’s powerful search capabilities. json", "metadata": { "slide_filename": "mypowerpoint1.pptx", See the following code: session = boto3.Session()
Experiment tracking in machine learning is the practice of preserving all pertinent data for each experiment you conduct. Experiment tracking is implemented by ML teams in a variety of ways, including using spreadsheets, GitHub, or in-house platforms. Major ML and DL libraries like TensorFlow, Keras, or Scikit-learn are also supported.
These days enterprises are sitting on a pool of data and increasingly employing machine learning and deep learning algorithms to forecast sales, predict customer churn and fraud detection, etc., Datascience practitioners experiment with algorithms, data, and hyperparameters to develop a model that generates business insights.
Amazon SageMaker Serverless Inference is a purpose-built inference service that makes it easy to deploy and scale machine learning (ML) models. Data overview and preparation You can use a SageMaker Studio notebook with a Python 3 (DataScience) kernel to run the sample code. We use the first metadata file in this demo.
Using machine learning (ML) and natural language processing (NLP) to automate product description generation has the potential to save manual effort and transform the way ecommerce platforms operate. medium instance and the DataScience 3.0 jpg and the complete metadata from styles/38642.json.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content