This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. The post AWS Glue for Handling Metadata appeared first on Analytics Vidhya.
Amazon Bedrock Knowledge Bases has a metadata filtering capability that allows you to refine search results based on specific attributes of the documents, improving retrieval accuracy and the relevance of responses. These metadata filters can be used in combination with the typical semantic (or hybrid) similarity search.
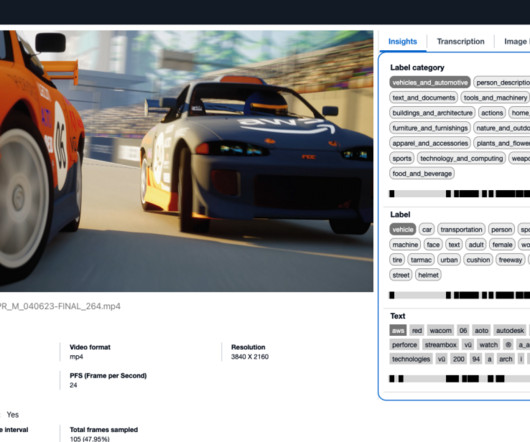
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
This article was published as a part of the DataScience Blogathon. Any type of contextual information, like device context, conversational context, and metadata, […]. Any type of contextual information, like device context, conversational context, and metadata, […].
This article was published as a part of the DataScience Blogathon. A centralized location for research and production teams to govern models and experiments by storing metadata throughout the ML model lifecycle. A Metadata Store for MLOps appeared first on Analytics Vidhya. Keeping track of […].
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, data lakes, and datascience teams, and maintaining compliance with relevant financial regulations.
This article was published as a part of the DataScience Blogathon. Introduction The purpose of a data warehouse is to combine multiple sources to generate different insights that help companies make better decisions and forecasting. It consists of historical and commutative data from single or multiple sources.
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for DataScience and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for data scientists and machine learning (ML) engineers.
Typically, on their own, data warehouses can be restricted by high storage costs that limit AI and ML model collaboration and deployments, while data lakes can result in low-performing datascience workloads. New insights and relationships are found in this combination. All of this supports the use of AI.
It drives an AI governance solution without the excessive costs of switching from your current datascience platform. The resulting automation drives scalability and accountability by capturing model development time and metadata, offering post-deployment model monitoring, and allowing for customized workflows.
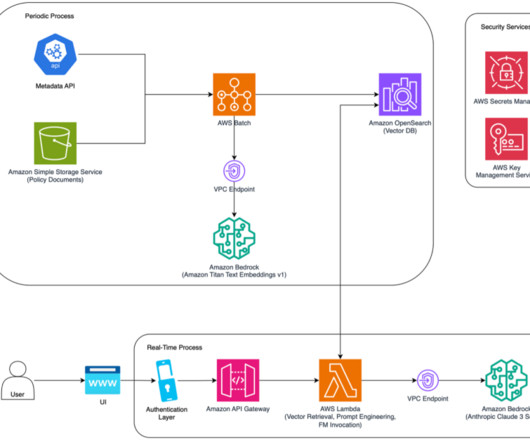
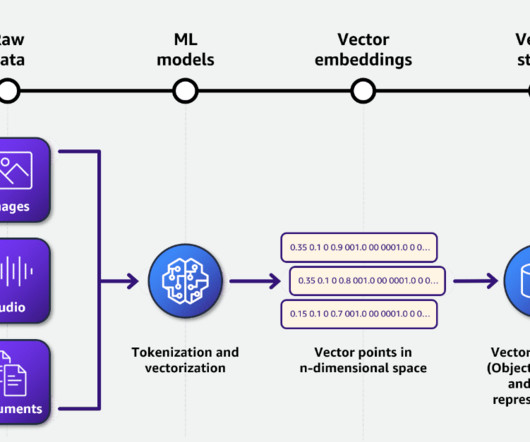
Along with each document slice, we store the metadata associated with it using an internal Metadata API, which provides document characteristics like document type, jurisdiction, version number, and effective dates. This process has been implemented as a periodic job to keep the vector database updated with new documents.
Data security must begin by understanding whether the collected data is compliant with data protection regulations such as GDPR or HIPAA. In this case, the provenance of the collected data is analyzed and the metadata is logged for future audit purposes.
Users without datascience or analytics experience can generate rigorous data-backed predictions to answer big questions like time-to-fill for important positions, or resignation risk for crucial employees. The datascience team couldn’t roll out changes independently to production.
Traditionally, developing appropriate datascience code and interpreting the results to solve a use-case is manually done by data scientists. The integration allows you to generate intelligent datascience code that reflects your use case. Data scientists still need to review and evaluate these results.
As AI models grow and data volumes expand, databases must scale horizontally, to allow organisations to add capacity without significant downtime or performance degradation. We unify source data, metadata, operational data, vector data and generated data—all in one platform.
But most important of all, the assumed dormant value in the unstructured data is a question mark, which can only be answered after these sophisticated techniques have been applied. Therefore, there is a need to being able to analyze and extract value from the data economically and flexibly. The solution integrates data in three tiers.
A/B testing and experimentation Datascience teams can systematically evaluate different model-tool combinations, measure performance metrics, and analyze response patterns in controlled environments. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance toolkit lets you direct, manage and monitor AI activities without the expense of switching your datascience platform, even for models developed using third-party tools.
Through workload optimization an organization can reduce data warehouse costs by up to 50 percent by augmenting with this solution. [1] 1] Users can access data through a single point of entry, with a shared metadata layer across clouds and on-premises environments.
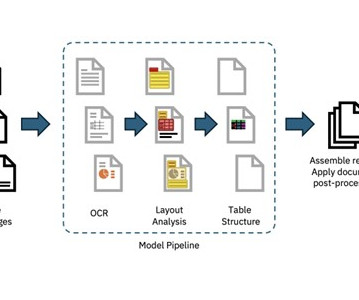
Each text, including the rotated text on the left of the page, is identified and extracted as a stand-alone text element with coordinates and other metadata that makes it possible to render a document very close to the original PDF but from a structured JSONformat.
IBM Cloud Pak for Data Express solutions offer clients a simple on ramp to start realizing the business value of a modern architecture. Data governance. The data governance capability of a data fabric focuses on the collection, management and automation of an organization’s data. Datascience and MLOps.
The advent of big data, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in datascience across industries. However, research shows that up to 85% of datascience projects fail to move beyond proofs of concept to full-scale deployment.
By supporting open-source frameworks and tools for code-based, automated and visual datascience capabilities — all in a secure, trusted studio environment — we’re already seeing excitement from companies ready to use both foundation models and machine learning to accomplish key tasks.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. Streamlit This open source Python library makes it straightforward to create and share beautiful, custom web apps for ML and datascience. The following diagram illustrates the RAG framework.
Data Scientist at AWS, bringing a breadth of datascience, ML engineering, MLOps, and AI/ML architecting to help businesses create scalable solutions on AWS. Publish the BYOC image to Amazon ECR Create a script named model_quality_monitoring.py amazonaws.com/sm-mm-mqm-byoc:1.0", instance_count=1, instance_type='ml.m5.xlarge',
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. The solution in this post aims to bring enterprise analytics operations to the next level by shortening the path to your data using natural language. Today, generative AI can enable people without SQL knowledge.
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy datascience projects.
Datascience tasks such as machine learning also greatly benefit from good data integrity. When an underlying machine learning model is being trained on data records that are trustworthy and accurate, the better that model will be at making business predictions or automating tasks.
It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model. He solves complex organizational and technical challenges using datascience and engineering. Nick Biso is a Machine Learning Engineer at AWS Professional Services.
. “Most data being generated every day is unstructured and presents the biggest new opportunity.” ” We wanted to learn more about what unstructured data has in store for AI. Donahue: We’re beginning to see datascience and machine learning engineering teams work more closely with data engineering teams.
Metadata tagging and filtering mechanisms safeguard proprietary data. Key Takeaways Data quality is critical for effective RAG implementation. Vector search alone is insufficient; metadata, filtering, and retrieval agents improve accuracy.
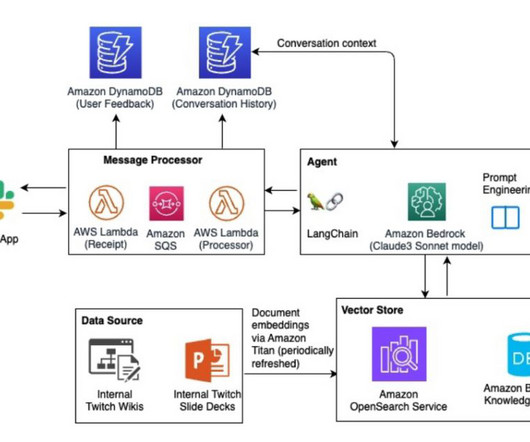
We discuss the solution components to build a multimodal knowledge base, drive agentic workflow, use metadata to address hallucinations, and also share the lessons learned through the solution development using multiple large language models (LLMs) and Amazon Bedrock Knowledge Bases. Yunfei Bai is a Principal Solutions Architect at AWS.
ETL ( Extract, Transform, Load ) Pipeline: It is a data integration mechanism responsible for extracting data from data sources, transforming it into a suitable format, and loading it into the data destination like a data warehouse. The pipeline ensures correct, complete, and consistent data.
In this post, we provide best practices to maximize the value of SageMaker HyperPod task governance and make the administration and datascience experiences seamless. Access control When working with SageMaker HyperPod task governance, data scientists will assume their specific role.
Most data scientists are familiar with the concept of time series data and work with it often. The time series database (TSDB) , however, is still an underutilized tool in the datascience community. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
Finance Organizations Detect Fraud in a Fraction of a Second Financial organizations face a significant challenge in detecting patterns of fraud due to the vast amount of transactional data that requires rapid analysis. Additionally, the scarcity of labeled data for actual instances of fraud poses a difficulty in training AI models.
It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. In this post, we show you how to convert Python code that fine-tunes a generative AI model in Amazon Bedrock from local files to a reusable workflow using Amazon SageMaker Pipelines decorators.
This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock. Twilio’s use case Twilio wanted to provide an AI assistant to help their data analysts find data in their data lake.
With “Science of Gaming” as their core philosophy, they have enabled a vision of end-to-end informatics around game dynamics, game platforms, and players by consolidating orthogonal research directions of game AI, game datascience, and game user research. We provided metadata to uniquely distinguish the model from each other.
Each frame will be analyzed using Amazon Rekognition and Amazon Bedrock for metadata extraction. Policy evaluation – Using the extracted metadata from the video, the system conducts LLM evaluation. An Amazon OpenSearch Service cluster stores the extracted video metadata and facilitates users’ search and discovery needs.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and datascience use cases. Perform data quality monitoring based on pre-configured rules.
These and many other questions are now on top of the agenda of every datascience team. To quantify how well your models are doing, DataRobot provides you with a comprehensive set of datascience metrics — from the standards (Log Loss, RMSE) to the more specific (SMAPE, Tweedie Deviance). Learn More About DataRobot MLOps.
Here are some essential strategies: Time-Stamped Snapshots: Maintaining time-stamped snapshots of the data allows for a historical view of changes made over time. These snapshots can be used to roll back to a previous state or track data lineage. You can connect with her on Linkedin.
Amazon Kendra also supports the use of metadata for each source file, which enables both UIs to provide a link to its sources, whether it is the Spack documentation website or a CloudFront link. Furthermore, Amazon Kendra supports relevance tuning , enabling boosting certain data sources.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content