This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
30% Off ODSC East, Fan-Favorite Speakers, Foundation Models for Times Series, and ETL Pipeline Orchestration The ODSC East 2025 Schedule isLIVE! Explore the must-attend sessions and cutting-edge tracks designed to equip AI practitioners, data scientists, and engineers with the latest advancements in AI and machine learning.
The field of datascience has evolved dramatically over the past several years, driven by technological breakthroughs, industry demands, and shifting priorities within the community. 20212024: Interest declined as deep learning and pre-trained models took over, automating many tasks previously handled by classical ML techniques.
Learn the basics of data engineering to improve your ML modelsPhoto by Mike Benna on Unsplash It is not news that developing Machine Learning algorithms requires data, often a lot of data. Collecting this data is not trivial, in fact, it is one of the most relevant and difficult parts of the entire workflow.
DataScience You heard this term most of the time all over the internet, as well this is the most concerning topic for newbies who want to enter the world of data but don’t know the actual meaning of it. I’m not saying those are incorrect or wrong even though every article has its mindset behind the term ‘ DataScience ’.
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. Many organizations have been using a combination of on-premises and open source datascience solutions to create and manage machine learning (ML) models.
Introduction Machine learning has become an essential tool for organizations of all sizes to gain insights and make data-driven decisions. However, the success of ML projects is heavily dependent on the quality of data used to train models. Poor data quality can lead to inaccurate predictions and poor model performance.
Introduction to Data Engineering Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Data scientists often spend up to 80% of their time on data engineering in datascience projects.
AI and machine learning (ML) models are incredibly effective at doing this but are complex to build and require datascience expertise. HT: Today’s marketers need to not only understand past customer behaviour but must be able to anticipate and act on customers’ future wants and needs.
This post presents a solution that uses a workflow and AWS AI and machine learning (ML) services to provide actionable insights based on those transcripts. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture. Validation set 11 1500 0.82
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Programming for DataScience with Python This course series teaches essential programming skills for data analysis, including SQL fundamentals for querying databases and Unix shell basics. Students also learn Python programming, from fundamentals to data manipulation with NumPy and Pandas, along with version control using Git.
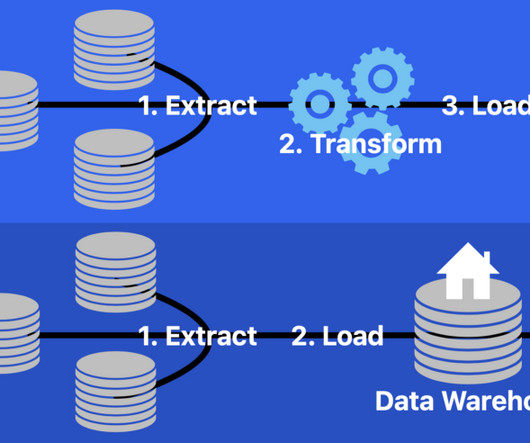
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is. ELT stands for extract, load and transform.
Automation has been a key trend in the past few years and that ranges from the design to building of a data warehouse to loading and maintaining, all of that can be automated. Speed Varying data formats Data publishing What are some ways that Astera has integrated AI into customer workflow?
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
This post is a bitesize walk-through of the 2021 Executive Guide to DataScience and AI — a white paper packed with up-to-date advice for any CIO or CDO looking to deliver real value through data. Team Building the right datascience team is complex. Download the free, unabridged version here.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. Watsonx.data allows customers to augment data warehouses such as Db2 Warehouse and Netezza and optimize workloads for performance and cost. IBM watsonx.ai
Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. ML Engineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. The input to the training pipeline is the features dataset.
The embeddings are captured in Amazon Simple Storage Service (Amazon S3) via Amazon Kinesis Data Firehose , and we run a combination of AWS Glue extract, transform, and load (ETL) jobs and Jupyter notebooks to perform the embedding analysis. Set the parameters for the ETL job as follows and run the job: Set --job_type to BASELINE.
For budding data scientists and data analysts, there are mountains of information about why you should learn R over Python and the other way around. Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the datascience world can agree on, SQL.
This situation is not different in the ML world. Data Scientists and ML Engineers typically write lots and lots of code. Building a mental model for ETL components Learn the art of constructing a mental representation of the components within an ETL process.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. They can contain structured, unstructured, or semi-structured data.
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently.
And we at deployr , worked alongside them to find the best possible answers for everyone involved and build their Data and ML Pipelines. Building data and ML pipelines: from the ground to the cloud It was the beginning of 2022, and things were looking bright after the lockdown’s end.
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. Stefan: Yeah.
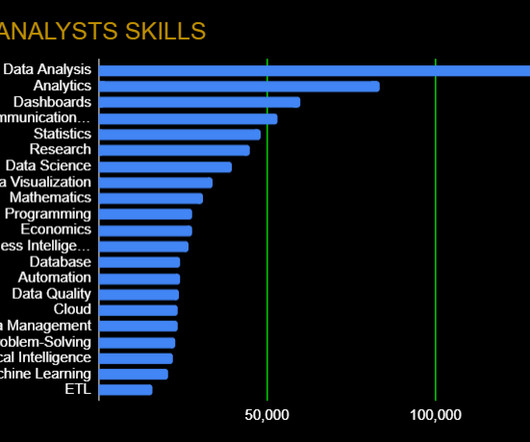
As the sibling of datascience, data analytics is still a hot field that garners significant interest. Companies have plenty of data at their disposal and are looking for people who can make sense of it and make deductions quickly and efficiently.
Dolt LakeFS Delta Lake Pachyderm Git-like versioning Database tool Data lake Data pipelines Experiment tracking Integration with cloud platforms Integrations with ML tools Examples of data version control tools in ML DVC Data Version Control DVC is a version control system for data and machine learning teams.
IBM merged the critical capabilities of the vendor into its more contemporary Watson Studio running on the IBM Cloud Pak for Data platform as it continues to innovate. The platform makes collaborative datascience better for corporate users and simplifies predictive analytics for professional data scientists.
Over the past few years DataScience has MIGRATED from individual computers to service cloud platforms. I just finished learning Azure’s service cloud platform using Coursera and the Microsoft Learning Path for DataScience. Be sure to create an Environment for the ML workspace.
11 key differences in 2023 Photo by Jan Tinneberg on Unsplash Working in DataScience and Machine Learning (ML) professions can be a lot different from the expectation of it. A popular focus of a majority of DataScience courses, degrees, and online competitions is on creating a model that has the highest accuracy or best fit.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
About the authors Samantha Stuart is a Data Scientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements. He has touched on most aspects of these projects, from infrastructure and DevOps to software development and AI/ML.
Microsoft introduces a new unit AIOps detailing in the following post : Cloud Intelligence/AIOps (“AIOps” for brevity) aims to innovate AI/ML technologies to help design, build, and operate complex cloud platforms and services at scale—effectively and efficiently.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machine learning (ML) from weeks to minutes. Account A is the data lake account that houses all the ML-ready data obtained through extract, transform, and load (ETL) processes. Let’s go back to our data flow.
Confirmed sessions related to software engineering include: Building Data Contracts with Open-Source Tools Chronon — Open Source Data Platform for AI/ML Creating APIs That Data Scientists Will Love with FastAPI, SQLAlchemy, and Pydantic Using APIs in DataScience Without Breaking Anything Don’t Go Over the Deep End: Building an Effective OSS Management (..)
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them.
Jupyter notebooks have been one of the most controversial tools in the datascience community. Nevertheless, many data scientists will agree that they can be really valuable – if used well. I’ll show you best practices for using Jupyter Notebooks for exploratory data analysis. Aside neptune.ai
A unified data fabric also enhances data security by enabling centralised governance and compliance management across all platforms. Automated Data Integration and ETL Tools The rise of no-code and low-code tools is transforming data integration and Extract, Transform, and Load (ETL) processes.
In my 7 years of DataScience journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. A lot of you who are already in the datascience field must be familiar with BigQuery and its advantages.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of data pipelines, including the two major types of existing data pipelines. You also learned how to build an Extract Transform Load (ETL) pipeline and discovered the automation capabilities of Apache Airflow for ETL pipelines.
It provided a platform for big data processing and machine learning, simplifying the process of building and deploying data pipelines. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. It helps data engineering teams by simplifying ETL development and management.
Tools such as Python’s Pandas library, Apache Spark, or specialised data cleaning software streamline these processes, ensuring data integrity before further transformation. Step 3: Data Transformation Data transformation focuses on converting cleaned data into a format suitable for analysis and storage.
As the company continues to evolve to integrate AI into its existing and new product catalog, this requires sophisticated approaches to train and deploy multi-modal machine learning (ML) ensemble models for solving complex business needs. Daniel Suarez is a DataScience Engineer at CCC Intelligent Solutions.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content