This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the DataScience Blogathon. Introduction ETL pipelines look different today than they used to. The post Is manual ETL better than No-Code ETL: Are ETL tools dead? appeared first on Analytics Vidhya.
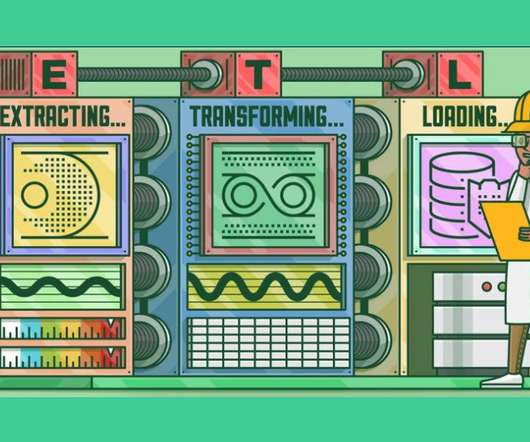
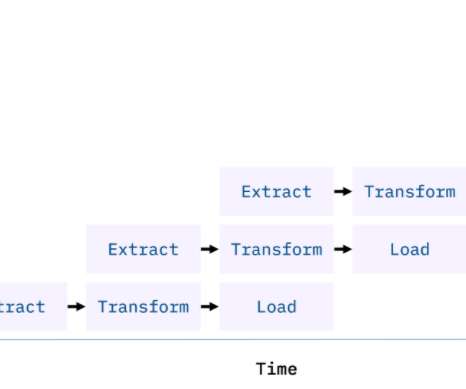
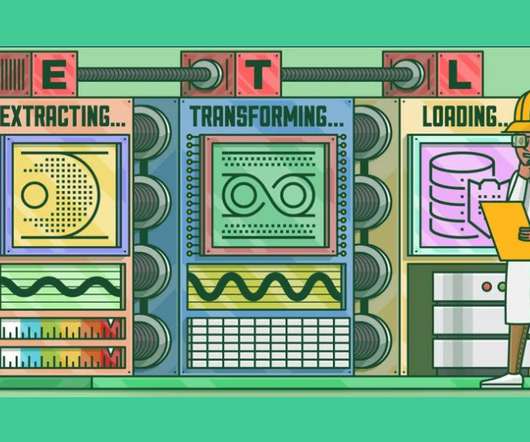
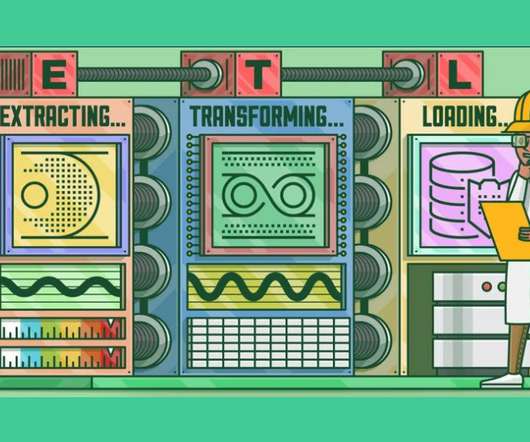
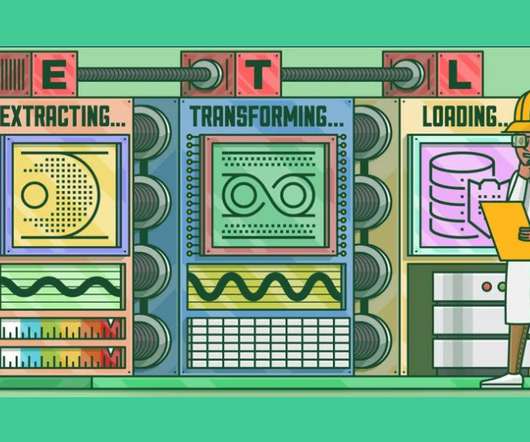
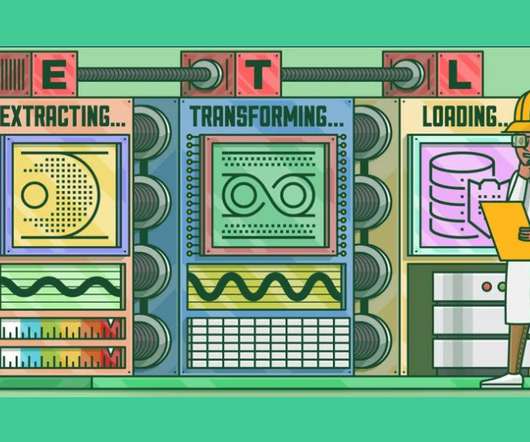
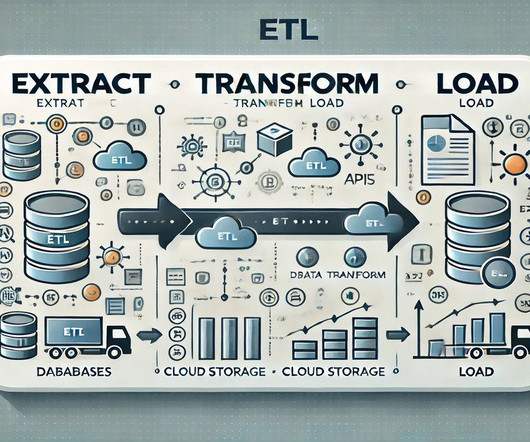
This article was published as a part of the DataScience Blogathon. Introduction to ETLETL is a type of three-step data integration: Extraction, Transformation, Load are processing, used to combine data from multiple sources. It is commonly used to build Big Data.
This article was published as a part of the DataScience Blogathon. Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective data integration. Building an ETL pipeline using Apache […]. Building an ETL pipeline using Apache […].
This article was published as a part of the DataScience Blogathon. Introduction on ETL Pipeline ETL pipelines are a set of processes used to transfer data from one or more sources to a database, like a data warehouse.
This article was published as a part of the DataScience Blogathon. The post ETL and Workflow Orchestration Tools appeared first on Analytics Vidhya. We’ll continue […].
This article was published as a part of the DataScience Blogathon. Introduction Data is ubiquitous in our modern life. Obtaining, structuring, and analyzing these data into new, relevant information is crucial in today’s world. The post ETL vs ELT in 2022: Do they matter?
This article was published as a part of the DataScience Blogathon. Introduction ETL pipelines can be built from bash scripts. You will learn about how shell scripting can implement an ETL pipeline, and how ETL scripts or tasks can be scheduled using shell scripting. What is shell scripting?
This article was published as a part of the DataScience Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in data engineering. Traditionally, ETL processes are […]. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya.
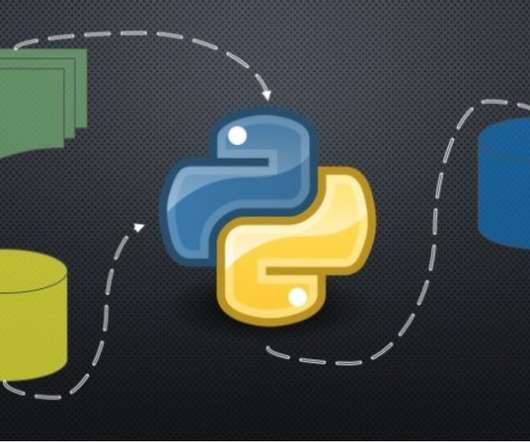
ArticleVideo Book This article was published as a part of the DataScience Blogathon Overview: Assume the job of a Data Engineer, extracting data from. The post Implementing ETL Process Using Python to Learn Data Engineering appeared first on Analytics Vidhya.
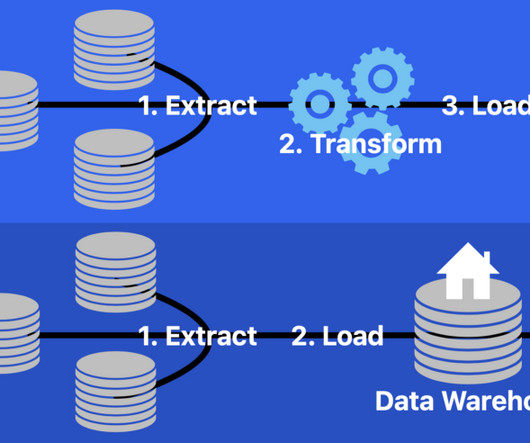
This article was published as a part of the DataScience Blogathon. Introduction At the highest level, ETL converts your data before uploading, while ELT converts data only after uploading to your repository. The post ETL & ELT – Data Engineering Essentials appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction on ETL Tools The amount of data being used or stored in today’s world is extremely huge. Many companies, organizations, and industries store the data and use it as per the requirement.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction to ETLETL as the name suggests, Extract Transform and. The post Pandas Vs PETL for ETL appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon What is ETL? ETL is a process that extracts data from multiple source systems, changes it (through calculations, concatenations, and so on), and then puts it into the Data Warehouse system. ETL stands for Extract, Transform, and Load.
This article was published as a part of the DataScience Blogathon. Introduction Organizations with a separate transactional database and data warehouse typically have many data engineering activities. For example, they extract, transform and load data from various sources into their data warehouse.
This article was published as a part of the DataScience Blogathon A data scientist’s ability to extract value from data is closely related to how well-developed a company’s data storage and processing infrastructure is.
This article was published as a part of the DataScience Blogathon. Introduction ETL is the process that extracts the data from various data sources, transforms the collected data, and loads that data into a common data repository. Azure Data Factory […].
Introduction In the era of Data storehouse, the need for assimilating the data from contrasting sources into a single consolidated database requires you to Extract the data from its parent source, Transform and amalgamate it, and thus, Load it into the consolidated database (ETL).
This article was published as a part of the DataScience Blogathon. Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well.
This article was published as a part of the DataScience Blogathon. Introduction Data acclimates to countless shapes and sizes to complete its journey from a source to a destination. Be it a streaming job or a batch job, ETL and ELT are irreplaceable.
This article was published as a part of the DataScience Blogathon. Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. It provides organizations with […].
This article was published as a part of the DataScience Blogathon. Introduction Azure data factory (ADF) is a cloud-based ETL (Extract, Transform, Load) tool and data integration service which allows you to create a data-driven workflow. In this article, I’ll show […].
This article was published as a part of the DataScience Blogathon. Introduction on ETL Tools The amount of data being used or stored in today’s world is extremely huge. Many companies, organizations, and industries store the data and use it as per the requirement.
Introduction Have you ever struggled with managing complex data transformations? In today’s data-driven world, extracting, transforming, and loading (ETL) data is crucial for gaining valuable insights. While many ETL tools exist, dbt (data build tool) is emerging as a game-changer.
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
30% Off ODSC East, Fan-Favorite Speakers, Foundation Models for Times Series, and ETL Pipeline Orchestration The ODSC East 2025 Schedule isLIVE! Explore the must-attend sessions and cutting-edge tracks designed to equip AI practitioners, data scientists, and engineers with the latest advancements in AI and machine learning.
This article was published as a part of the DataScience Blogathon. Introduction Data scientists, engineers, and BI analysts often need to analyze, process, or query different data sources.
The field of datascience has evolved dramatically over the past several years, driven by technological breakthroughs, industry demands, and shifting priorities within the community. Data Engineerings SteadyGrowth 20182021: Data engineering was often mentioned but overshadowed by modeling advancements.
The whole thing is very exciting, but where do I get the data from? In this article, we will look at some data engineering basics for developing a so-called ETL pipeline. I run the scripts of this article using Deepnote: a cloud-based notebook that’s great for collaborative datascience projects and prototyping.
DataScience You heard this term most of the time all over the internet, as well this is the most concerning topic for newbies who want to enter the world of data but don’t know the actual meaning of it. I’m not saying those are incorrect or wrong even though every article has its mindset behind the term ‘ DataScience ’.
This article was published as a part of the DataScience Blogathon Introduction Data is present everywhere. Any action we perform generates some or the other form of data. But this data might not be present in a structured form. The post How to Extract Tabular Data from Doc files Using Python?
Many organizations have been using a combination of on-premises and open source datascience solutions to create and manage machine learning (ML) models. Datascience and DevOps teams may face challenges managing these isolated tool stacks and systems.
This article was published as a part of the DataScience Blogathon. Introduction on Snowflake Architecture This article helps to focus on an in-depth understanding of Snowflake architecture, how it stores and manages data, as well as its conceptual fragmentation concepts.
Here are a few key reasons: The variety and volume of data will continue to grow, requiring the database to handle diverse data types—structured, unstructured, and semi-structured—at scale. Selecting a database that can manage such variety without complex ETL processes is important.
Introduction to Data Engineering Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Data scientists often spend up to 80% of their time on data engineering in datascience projects.
Summary: Selecting the right ETL platform is vital for efficient data integration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
AI and machine learning (ML) models are incredibly effective at doing this but are complex to build and require datascience expertise. HT: Today’s marketers need to not only understand past customer behaviour but must be able to anticipate and act on customers’ future wants and needs. With Segment, you choose where you start.
In the world of AI-driven data workflows, Brij Kishore Pandey, a Principal Engineer at ADP and a respected LinkedIn influencer, is at the forefront of integrating multi-agent systems with Generative AI for ETL pipeline orchestration. ETL ProcessBasics So what exactly is ETL? filling missing values with AI predictions).
Programming for DataScience with Python This course series teaches essential programming skills for data analysis, including SQL fundamentals for querying databases and Unix shell basics. Students also learn Python programming, from fundamentals to data manipulation with NumPy and Pandas, along with version control using Git.
The advent of big data, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in datascience across industries. However, research shows that up to 85% of datascience projects fail to move beyond proofs of concept to full-scale deployment.
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is. ELT stands for extract, load and transform.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content