This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
Because ML is becoming more integrated into daily business operations, datascience teams are looking for faster, more efficient ways to manage ML initiatives, increase model accuracy and gain deeper insights. MLOps is the next evolution of data analysis and deep learning. How MLOps will be used within the organization.
This article was published as a part of the DataScience Blogathon. Introduction Machine learning (ML) has become an increasingly important tool for organizations of all sizes, providing the ability to learn and improve from data automatically.
Consequently, AIOps is designed to harness data and insight generation capabilities to help organizations manage increasingly complex IT stacks. Here, we’ll discuss the key differences between AIOps and MLOps and how they each help teams and businesses address different IT and datascience challenges.
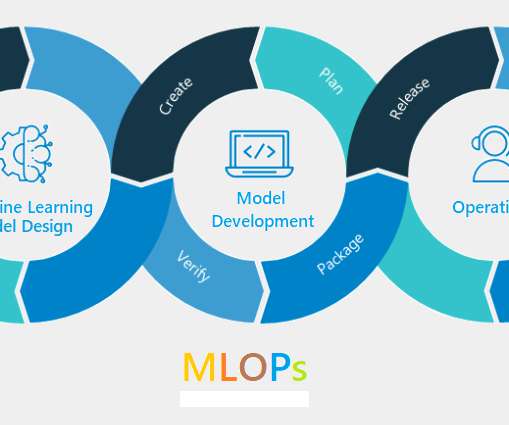
While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments. DataScience Layers.
Photo by CDC on Unsplash The DataScientist Show, by Daliana Liu, is one of my favorite YouTube channels. Unlike many other datascience programs that are very technical and require concentration to follow through, Daliana’s talk show strikes a delicate balance between profession and relaxation.
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, data lakes, and datascience teams, and maintaining compliance with relevant financial regulations.
Many organizations have been using a combination of on-premises and open source datascience solutions to create and manage machine learning (ML) models. Datascience and DevOps teams may face challenges managing these isolated tool stacks and systems.
For individual datascientists seeking a self-service experience, we recommend that you use the native Docker support in SageMaker Studio, as described in Accelerate ML workflows with Amazon SageMaker Studio Local Mode and Docker support. Ajay Raghunathan is a Machine Learning Engineer at AWS.
This article was published as a part of the DataScience Blogathon. Introduction MLOps, as a new area, is quickly gaining traction among DataScientists, Machine Learning Engineers, and AI enthusiasts. MLOps are required for anything to reach production.
MLOps, or Machine Learning Operations, is a multidisciplinary field that combines the principles of ML, software engineering, and DevOps practices to streamline the deployment, monitoring, and maintenance of ML models in production environments. ML Operations : Deploy and maintain ML models using established DevOps practices.
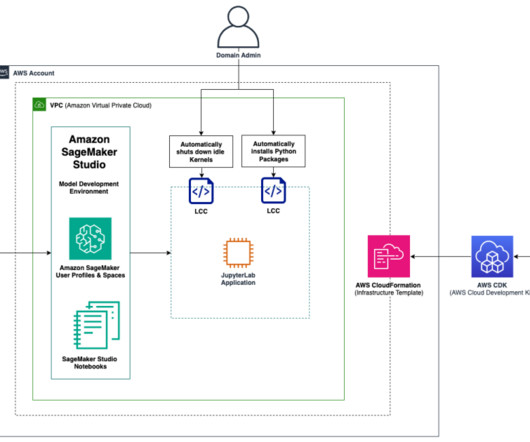
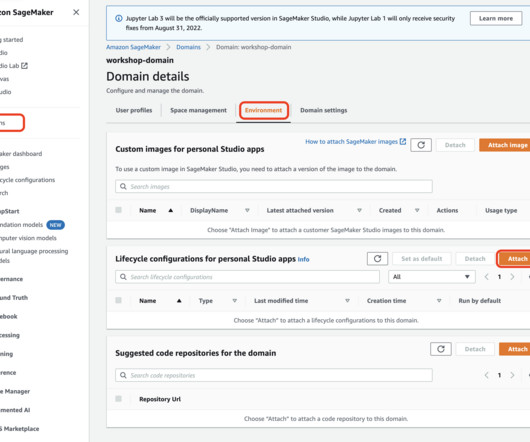
Amazon SageMaker Studio provides a single web-based visual interface where datascientists create dedicated workspaces to perform all ML development steps required to prepare data and build, train, and deploy models. In this solution, a JupyterLab space has been included in the infrastructure stack.
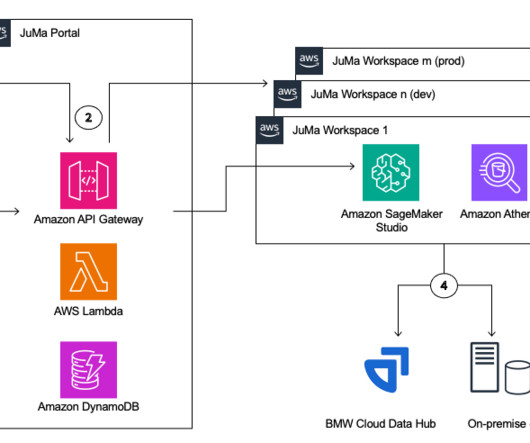
In an increasingly digital and rapidly changing world, BMW Group’s business and product development strategies rely heavily on data-driven decision-making. With that, the need for datascientists and machine learning (ML) engineers has grown significantly.
Using a full-stack approach for deploying applications to the edge, a datascientist can perform fine-tuning, testing and deployment of the models. The software stack included the Red Hat OpenShift Container Platform and Red Hat OpenShift DataScience.
Cloud computing and datascience are interconnected, making data-related cloud skills highly valuable. Understanding the Role of a Cloud Engineer Cloud computing has changed how businesses store and access data. Understand DevOps and CI/CD Cloud Engineers often work closely with DevOps teams to ensure smooth deployments.
Axfood has a structure with multiple decentralized datascience teams with different areas of responsibility. Together with a central data platform team, the datascience teams bring innovation and digital transformation through AI and ML solutions to the organization.
DataScientist at AWS, bringing a breadth of datascience, ML engineering, MLOps, and AI/ML architecting to help businesses create scalable solutions on AWS. He is a technology enthusiast and a builder with a core area of interest in AI/ML, data analytics, serverless, and DevOps. Raju Patil is a Sr.
Programming for DataScience with Python This course series teaches essential programming skills for data analysis, including SQL fundamentals for querying databases and Unix shell basics. Students also learn Python programming, from fundamentals to data manipulation with NumPy and Pandas, along with version control using Git.
MLOps practitioners have many options to establish an MLOps platform; one among them is cloud-based integrated platforms that scale with datascience teams. TWCo datascientists and ML engineers took advantage of automation, detailed experiment tracking, integrated training, and deployment pipelines to help scale MLOps effectively.
MLOps acts as the link between datascientists and the production team’s operations (a team consisting of machine learning engineers, software engineers, and IT operations professionals) as they work together to develop ML models and supervise the use of ML models in production. They might also help with data preparation and cleaning.
Lived through the DevOps revolution. If you’d like a TLDR, here it is: MLOps is an extension of DevOps. Not a fork: – The MLOps team should consist of a DevOps engineer, a backend software engineer, a datascientist, + regular software folks. Model monitoring tools will merge with the DevOps monitoring stack.
Although the solution did alleviate GPU costs, it also came with the constraint that datascientists needed to indicate beforehand how much GPU memory their model would require. Furthermore, DevOps were burdened with manually provisioning GPU instances in response to demand patterns.
This evolution has spurred a significant demand for specialized skills in areas such as AI, data engineering, machine learning, datascience, cybersecurity, and cloud computing. Key Drivers of This Hiring Boom Evolution Beyond Support Functions GCCs are shedding their old image as mere cost-arbitrage centers.
This approach led to datascientists spending more than 50% of their time on operational tasks, leaving little room for innovation, and posed challenges in monitoring model performance in production. This feature integrates with Amazon SageMaker Experiments to provide datascientists with insights into the tuning process.
The functional architecture with different capabilities is implemented using a number of AWS services, including AWS Organizations , SageMaker, AWS DevOps services, and a data lake. Datascientists from ML teams across different business units federate into their team’s development environment to build the model pipeline.
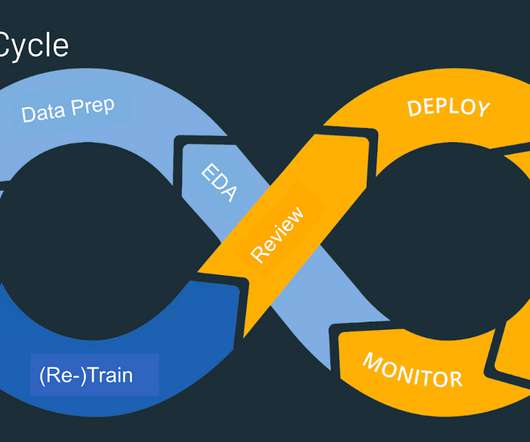
It combines principles from DevOps, such as continuous integration, continuous delivery, and continuous monitoring, with the unique challenges of managing machine learning models and datasets. Model Training Frameworks This stage involves the process of creating and optimizing predictive models with labeled and unlabeled data.
Since the rise of DataScience, it has found several applications across different industrial domains. However, the programming languages that work at the core of DataScience play a significant role in it. Hence for an individual who wants to excel as a datascientist, learning Python is a must.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. It provides a high-level API that makes it easy to define and execute datascience workflows.
As we continue to innovate to increase datascience productivity, we’re excited to announce the improved SageMaker Studio experience, which allows users to select the managed Integrated Development Environment (IDE) of their choice, while having access to the SageMaker Studio resources and tooling across the IDEs.
Thus, MLOps is the intersection of Machine Learning, DevOps, and Data Engineering (Figure 1). The ideal MLOps engineer would have some experience with several MLOps and/or DevOps platforms. Without a central place to collaborate and manage the model lifecycle, datascience teams will encounter challenges managing model stages.
Kara Yang is a datascientist at AWS Professional Services, adept at leveraging cloud computing, machine learning, and Generative AI to tackle diverse industry challenges. Praveen Kumar Jeyarajan is a Principal DevOps Consultant at AWS, supporting Enterprise customers and their journey to the cloud.
After being tested locally or as a training job, a datascientist or practitioner who is an expert on SageMaker can convert the function to a SageMaker pipeline step by adding a @step decorator. As you move from pilot and test phases to deploying generative AI models at scale, you will need to apply DevOps practices to ML workloads.
For instance, data labeling and training has a strong datascience focus, edge deployment requires an Internet of Things (IoT) specialist, and automating the whole process is usually done by someone with a DevOps skill set. So if you have a DevOps challenge or want to go for a run: let him know.
In addition to data engineers and datascientists, there have been inclusions of operational processes to automate & streamline the ML lifecycle. Depending on your governance requirements, DataScience & Dev accounts can be merged into a single AWS account.
The main benefit is that a datascientist can choose which script to run to customize the container with new packages. There are also limited options for ad hoc script customization by users, such as datascientists or ML engineers, due to permissions of the user profile execution role. Choose Open Launcher.
The company’s H20 Driverless AI streamlines AI development and predictive analytics for professionals and citizen datascientists through open source and customized recipes. The platform makes collaborative datascience better for corporate users and simplifies predictive analytics for professional datascientists.
These data owners are focused on providing access to their data to multiple business units or teams. Datascience team – Datascientists need to focus on creating the best model based on predefined key performance indicators (KPIs) working in notebooks.
The first is by using low-code or no-code ML services such as Amazon SageMaker Canvas , Amazon SageMaker Data Wrangler , Amazon SageMaker Autopilot , and Amazon SageMaker JumpStart to help data analysts prepare data, build models, and generate predictions. Conduct exploratory analysis and data preparation.
Extension Of Devops MLOps is an extension of DevOps. DevOps aims to streamline the development and operation of software applications, while MLOps focuses on the machine learning lifecycle. MLOps extends DevOps by including datascience practices, like model training and data preprocessing.
Datascience teams often face challenges when transitioning models from the development environment to production. Usually, there is one lead datascientist for a datascience group in a business unit, such as marketing. ML Dev Account This is where datascientists perform their work.
Machine Learning Operations (MLOps) can significantly accelerate how datascientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
This containerization minimizes the complexity of managing dependencies and configurations, allowing datascientists to focus on model development rather than infrastructure concerns. DevOps Integration OpenShift is designed with DevOps in mind, providing a seamless pipeline for continuous integration and continuous deployment (CI/CD).
This architecture design represents a multi-account strategy where ML models are built, trained, and registered in a central model registry within a datascience development account (which has more controls than a typical application development account).
Machine learning (ML) projects are inherently complex, involving multiple intricate steps—from data collection and preprocessing to model building, deployment, and maintenance. She has a decade of experience in DevOps, infrastructure, and ML. These iterative challenges can hinder progress and slow down projects.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















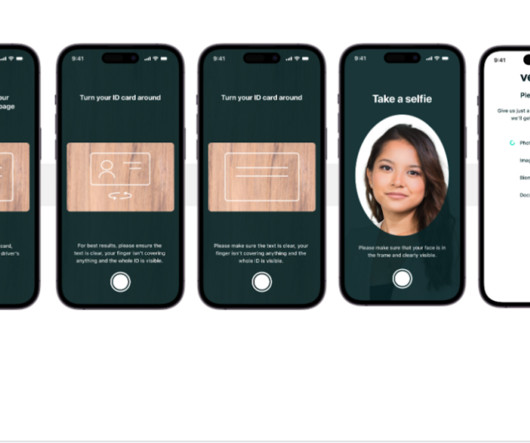










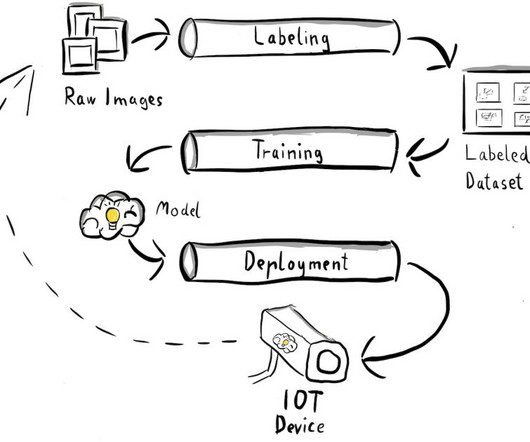




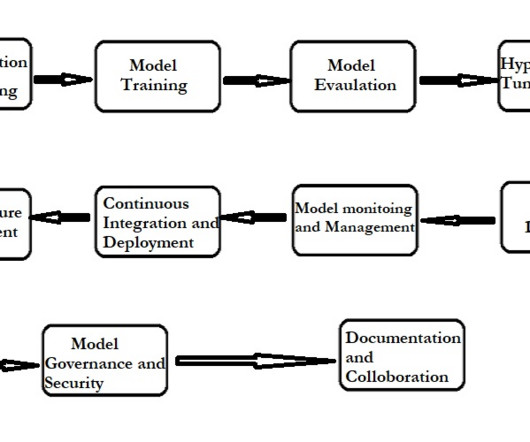











Let's personalize your content