This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
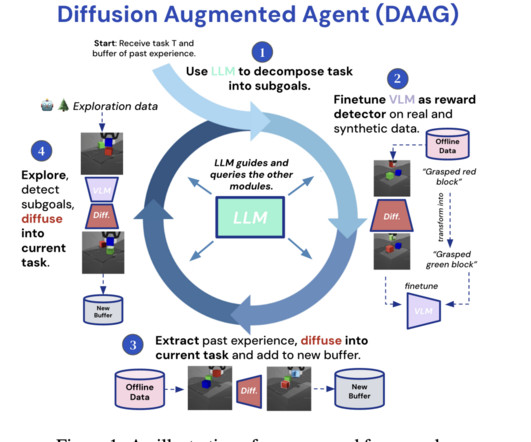
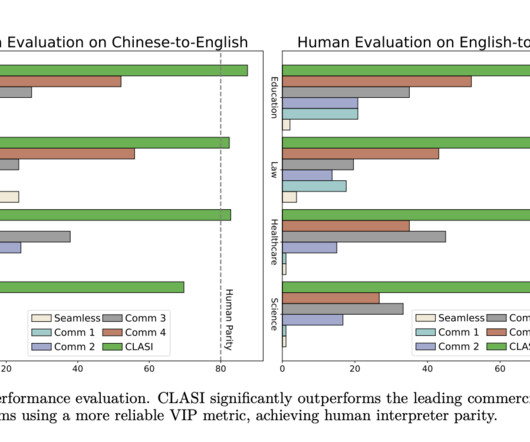
A major issue in RL is the datascarcity in embodied AI, where agents must interact with physical environments. This problem is exacerbated by the need for substantial reward-labeled data to train agents effectively. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
The rapid advancement of Artificial Intelligence (AI) and Machine Learning (ML) has highlighted the critical need for large, diverse, and high-quality datasets to train and evaluate foundation models. Utilizing advanced models like GPT4o, LLaMa3, Mixtral, Gemma, and Gemma2, OAK addresses datascarcity, privacy concerns, and diversity issues.
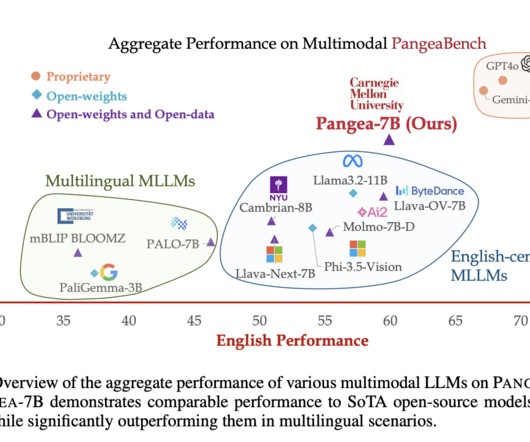
The dataset was designed to address the major challenges of multilingual multimodal learning: datascarcity, cultural nuances, catastrophic forgetting, and evaluation complexity. Don’t Forget to join our 50k+ ML SubReddit. Moreover, PANGEA matches or even outperforms proprietary models like Gemini-1.5-Pro
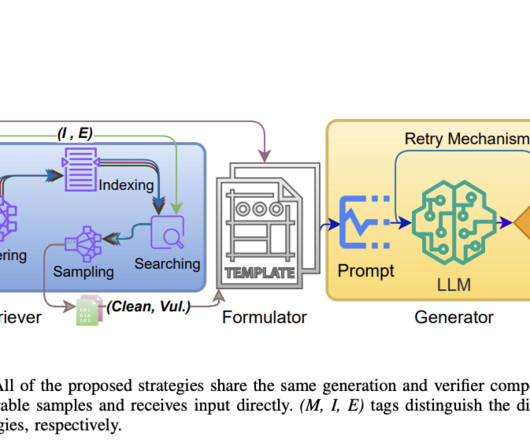
The success of VulScribeR highlights the importance of large-scale data augmentation in the field of vulnerability detection. By generating diverse and realistic vulnerable code samples, this approach provides a practical solution to the datascarcity problem that has long hindered the development of effective DLVD models.
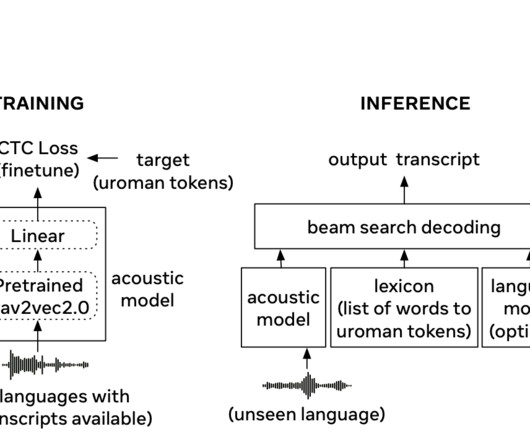
With its extensive language training and romanization technique, the MMS Zero-shot method offers a promising solution to the datascarcity challenge, advancing the field towards more inclusive and universal speech recognition systems. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
To address datascarcity and granularity issues, the system employs sophisticated synthetic data generation techniques, particularly focusing on dense captioning and visual question-answering tasks. Don’t Forget to join our 55k+ ML SubReddit. If you like our work, you will love our newsletter.
They use a three-stage training methodology—pretraining, ongoing training, and fine-tuning—to tackle the datascarcity of the SiST job. The team trains their model continuously using billions of tokens of low-quality synthetic speech translation data to further their goal of achieving modal alignment between voice and text.
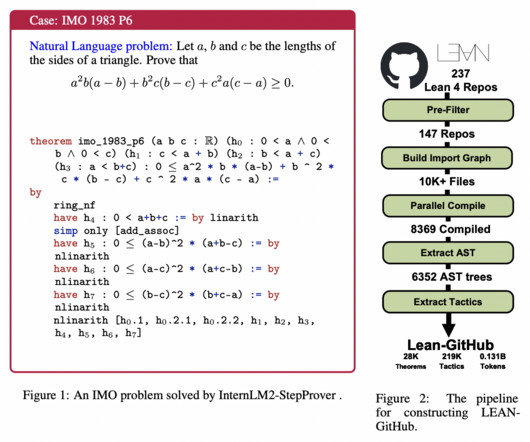
Large language models (LLMs) show promise in solving high-school-level math problems using proof assistants, yet their performance still needs to improve due to datascarcity. Formalized systems like Lean, Isabelle, and Coq offer computer-verifiable proofs, but creating these demands substantial human effort.
The SFM method marks a meaningful advancement in atmospheric science, setting a new benchmark in model accuracy for high-resolution weather data, especially when conventional models face limitations due to datascarcity and resolution misalignment. Don’t Forget to join our 55k+ ML SubReddit. Check out the Paper.
While deep learning’s scaling effects have driven advancements in AI, particularly in LLMs like GPT, further scaling during training faces limitations due to datascarcity and computational constraints. Dont Forget to join our 60k+ ML SubReddit.
These models are trained on data collected from social media, which introduces bias and may not accurately represent diverse patient experiences. Moreover, privacy concerns and datascarcity hinder the development of robust models for mental health diagnosis and treatment. Don’t Forget to join our 50k+ ML SubReddit.
These scenarios highlight the advantages of developing lightweight, task-specific models, offering promising returns in specialized domains where datascarcity or unique requirements make large-scale pretraining unfeasible. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content