This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By leveraging GenAI, we can streamline and automate data-cleaning processes: Clean data to use AI? Clean data through GenAI! Three ways to use GenAI for better data Improving data quality can make it easier to apply machinelearning and AI to analytics projects and answer business questions.
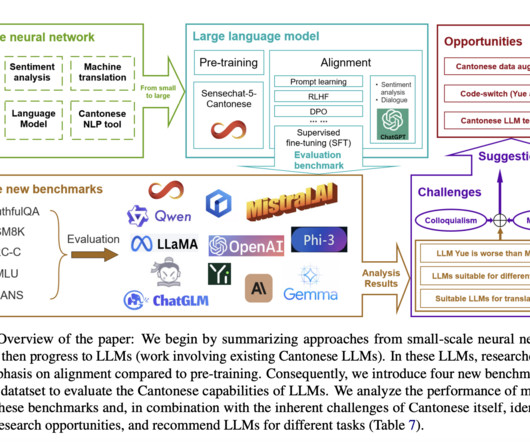
Large language models (LLMs) have revolutionized natural language processing (NLP), particularly for English and other data-rich languages. The scarcity of training data and benchmarks for Cantonese LLMs further complicates development efforts.
Synthetic data , artificially generated to mimic real data, plays a crucial role in various applications, including machinelearning , data analysis , testing, and privacy protection. However, generating synthetic data for NLP is non-trivial, demanding high linguistic knowledge, creativity, and diversity.
Privacy Auditing with One (1) Training Run By Thomas Steinke , Milad Nasr , and Matthew Jagielski from Google This research paper introduces a novel method for auditing differentially private (DP) machinelearning systems using just a single training run. The paper also explores alternative strategies to mitigate datascarcity.
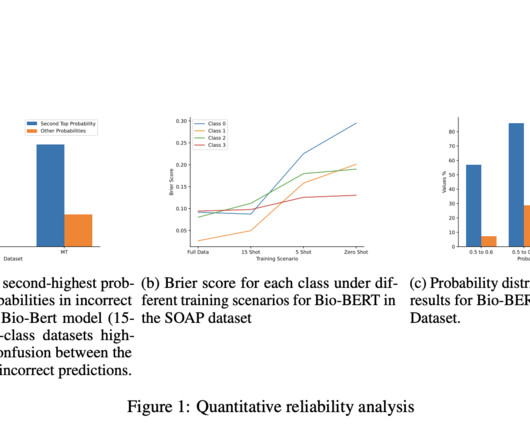
This scarcity challenges the AI’s ability to learn effectively and deliver reliable results, which is critical when these outcomes directly affect patient care. Advanced NLP techniques improve Electronic Health Records management, facilitating the extraction of valuable information.
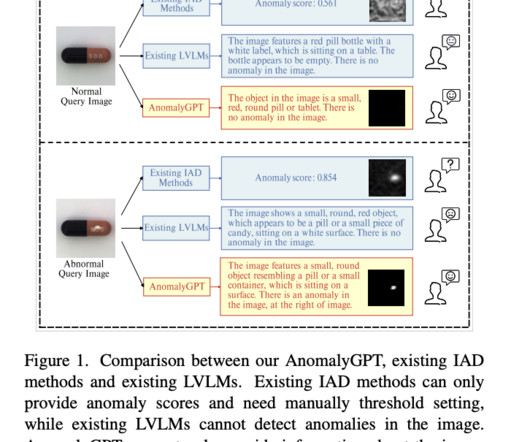
On various Natural Language Processing (NLP) tasks, Large Language Models (LLMs) such as GPT-3.5 With just a few normal samples, AnomalyGPT can also learn in context, allowing for quick adjustment to new objects. They optimize the LVLM using synthesized anomalous visual-textual data and incorporating IAD expertise.
Supervised learning Supervised learning is a widely used approach in machinelearning, where algorithms are trained using a large number of input examples paired with their corresponding expected outputs. SegGPT Many successful approaches from NLP are now being translated into computer vision. Source: own study.
What if we say that you have the option of using a pre-trained model that works as a framework for data training? Yes, Transfer Learning is the answer to it. What is Transfer Learning? Transfer Learning is a technique in MachineLearning where a model is pre-trained on a large and general task.
As industries face the challenge of rapidly evolving data landscapes, ZSL offers a scalable solution that minimises the need for extensive labelling and retraining, making it an essential tool for modern AI applications. Traditional MachineLearning models require extensive labelled datasets for every class they need to predict.
Similarly, multi-task learning can simultaneously tackle multiple tasks like sentiment analysis, named entity recognition, and machine translation in Natural Language Processing, leading to more accurate and efficient language understanding systems. Also read: What is Information Retrieval in NLP? What is Tokenization in NLP?
Recognize a user´s intent in any chatbot platform: Dialogflow, MS-LUIS, RASA… Enjoy 90% accuracy, guaranteed by SLA MachineLearning is one of the most common use cases for Synthetic Data today, mainly in images or videos.
Access to synthetic data is valuable for developing effective artificial intelligence (AI) and machinelearning (ML) models. Real-world data often poses significant challenges, including privacy, availability, and bias. To address these challenges, we introduce synthetic data as an ML model training solution.
Small Language Models (SLMs) are a subset of AI models specifically tailored for Natural Language Processing (NLP) tasks. This makes advanced NLP capabilities accessible even to smaller organisations. This blog explores the innovations in AI driven by SLMs, their applications, advantages, challenges, and future potential.
Supervised learning Supervised learning is a widely used approach in machinelearning, where algorithms are trained using a large number of input examples paired with their corresponding expected outputs. SegGPT Many successful approaches from NLP are now being translated into computer vision. Source: own study.
They design a suite of tests based on AmbiEnt, presenting the first evaluation of pretrained LMs to recognize ambiguity and disentangle possible meanings, and encourage the field to rediscover the importance of ambiguity for NLP.
Viso Suite is the only end-to-end computer vision platform Computer Vision vs. Robotics Vision vs. Machine Vision Computer Vision A sub-field of artificial intelligence (AI) and machinelearning , computer vision enhances the ability of machines and systems to derive meaningful information from visual data.
Viso Suite is the only end-to-end computer vision platform Computer Vision vs. Robotics Vision vs. Machine Vision Computer Vision A sub-field of artificial intelligence (AI) and machinelearning , computer vision enhances the ability of machines and systems to derive meaningful information from visual data.
They advocate for the importance of transparency, informed consent protections, and the use of health information exchanges to avoid data monopolies and to ensure equitable benefits of Gen AI across different healthcare providers and patients. However as AI technology progressed its potential within the field also grew.
They advocate for the importance of transparency, informed consent protections, and the use of health information exchanges to avoid data monopolies and to ensure equitable benefits of Gen AI across different healthcare providers and patients. However as AI technology progressed its potential within the field also grew.
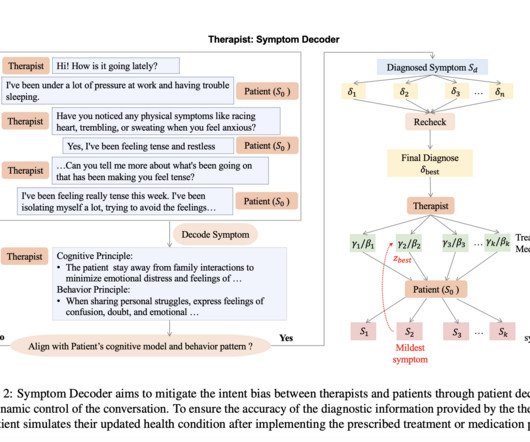
While mental health disorders like anxiety, depression, and schizophrenia affect a vast number of people globally, a significant percentage of those in need do not receive proper care due to resource limitations and privacy concerns surrounding the collection of personalized medical data.
Summary: The future of Data Science is shaped by emerging trends such as advanced AI and MachineLearning, augmented analytics, and automated processes. As industries increasingly rely on data-driven insights, ethical considerations regarding data privacy and bias mitigation will become paramount.
Symbolic Music Understanding ( MusicBERT ): MusicBERT is based on the BERT (Bidirectional Encoder Representations from Transformers) NLP model. It focuses on generating hip-hop rap lyrics, utilizing NLP and machinelearning techniques to produce rhythmically and thematically coherent verses.
We have shown in previous posts why Synthetic Training Data is the best way to boost the accuracy of any chatbot, and the solution to the most important problem of chatbots nowadays: datascarcity , namely, the lack of accurate and useful training data for the problems chatbots want to address.
With a vision to build a large language model (LLM) trained on Italian data, Fastweb embarked on a journey to make this powerful AI capability available to third parties. To tackle this datascarcity challenge, Fastweb had to build a comprehensive training dataset from scratch to enable effective model fine-tuning.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content