This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Computational methodologies, particularly machinelearning and predictive modeling, have emerged as pivotal tools to streamline this process. The traditional drug discovery process necessitates extensive experimental validations from initial target identification to late-stage clinical trials, consuming substantial resources and time.
He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machinelearning. He assists clients in adopting machinelearning and AI solutions that leverage NVIDIA-accelerated computing to address their training and inference challenges.
Together, these techniques mitigate the issues of limited target data, improving the model’s adaptability and accuracy. A recent paper published by a Chinese research team proposes a novel approach to combat datascarcity in classification tasks within target domains. Check out the Paper.
However, judgmental forecasting has introduced a nuanced approach, leveraging human intuition, domain knowledge, and diverse information sources to predict future events under datascarcity and uncertainty. The challenge in predictive forecasting lies in its inherent complexity and the limitations of existing methodologies.
RL applications range from game playing to robotic control, making it essential for researchers to develop efficient and scalable learning methods. A major issue in RL is the datascarcity in embodied AI, where agents must interact with physical environments.
By leveraging GenAI, we can streamline and automate data-cleaning processes: Clean data to use AI? Clean data through GenAI! Three ways to use GenAI for better data Improving data quality can make it easier to apply machinelearning and AI to analytics projects and answer business questions.
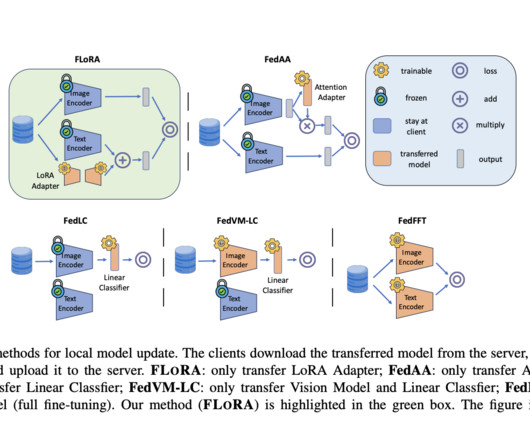
Also, FLORA’s efficiency analysis shows that it uses much less memory and communication compared to baseline methods, which shows that it could be used in real-world federated learning situations. In conclusion, FLORA presents a promising solution to the challenge of training vision-language models in federated learning settings.
Application of MachineLearning in Bioprocess Development: ML has profoundly impacted bioprocess development, particularly in strain selection and engineering stages. ML techniques like support vector machine (SVM) regression and Gaussian process (GP) regression predict optimal conditions for enzymatic activities and media composition.
However, these approaches face significant hurdles, including the curse of multilinguality, datascarcity, and the substantial computational resources required. Work with us here The post This AI Paper from SambaNova Presents a MachineLearning Method to Adapt Pretrained LLMs to New Languages appeared first on MarkTechPost.
The number of AI and, in particular, machinelearning (ML) publications related to medical imaging has increased dramatically in recent years. Datascarcity and data imbalance are two of these challenges. All Credit For This Research Goes To Researchers on This Project. Check out the paper, code and tool.
This is particularly useful in scenarios where real-world data is limited or expensive to obtain. Challenges and Best Practices While LLM-driven synthetic data generation offers numerous benefits, it also comes with challenges: Quality Control : Ensure the generated data is of high quality and relevant to your use case.
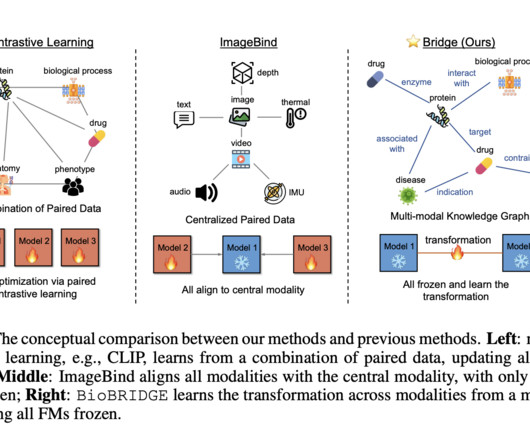
By aligning the embedding space of unimodal FMs through cross-modal transformation models utilizing KG triplets, BioBRIDGE maintains data sufficiency and efficiency and navigates the challenges posed by computational costs and datascarcity that hinder the scalability of multimodal approaches.
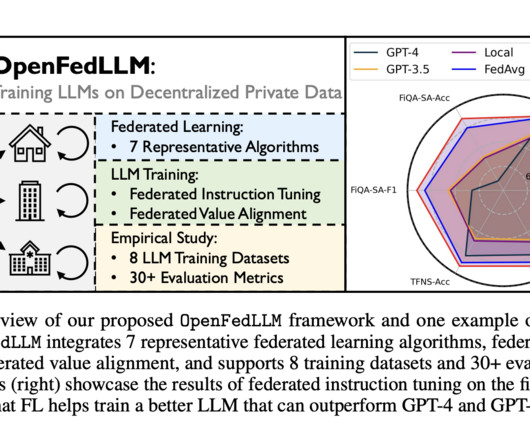
For instance, BloomberGPT excels in finance with private financial data spanning 40 years. Collaborative training on decentralized personal data, without direct sharing, emerges as a critical approach to support the development of modern LLMs amid datascarcity and privacy concerns.
The rapid advancement of Artificial Intelligence (AI) and MachineLearning (ML) has highlighted the critical need for large, diverse, and high-quality datasets to train and evaluate foundation models. OAK dataset offers a comprehensive resource for AI research, derived from Wikipedia’s main categories.
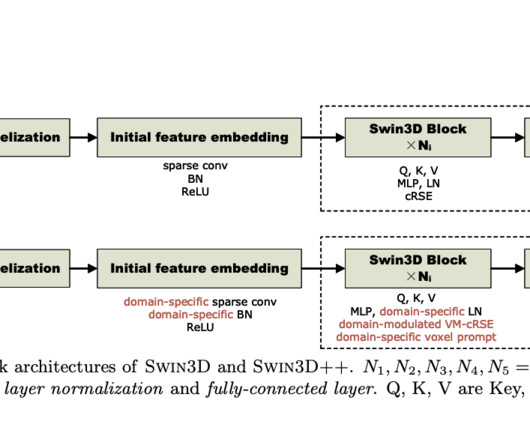
However, the scarcity and limited annotation of 3D data present significant challenges for the development and impact of 3D pretraining. One straightforward solution to address the datascarcity issue is to merge multiple existing 3D datasets and employ the combined data for universal 3D backbone pretraining.
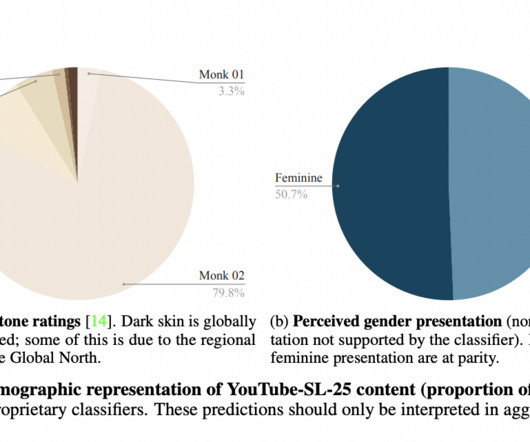
This field involves creating extensive datasets, developing sophisticated machine-learning models, and enhancing tools for translation and identification in various applications. This data bottleneck restricts the development of effective translation and interpretation tools, particularly for lesser-studied sign languages.
In the rapidly evolving landscape of artificial intelligence, the quality and quantity of data play a pivotal role in determining the success of machinelearning models. While real-world data provides a rich foundation for training, it often faces limitations such as scarcity, bias, and privacy concerns.
Here we present RhoFold+, an RNA language model-based deep learning method that accurately predicts 3D structures of single-chain RNAs from sequences. million RNA sequences and leveraging techniques to address datascarcity, RhoFold+ offers a fully automated end-to-end pipeline for RNA 3D structure prediction.
Instead of relying on aggregated human feedback, FSPO reframes reward modeling as a meta-learning problem, enabling models to construct personalized reward functions. The approach generates over a million structured synthetic preferences to address datascarcity.
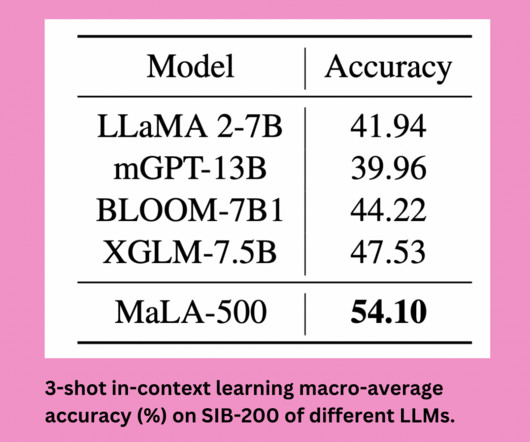
Other effective strategies to address datascarcity include vocabulary extension and ongoing pretraining. An important milestone was reached when the XLM-R auto-encoding model was introduced with 278M parameters with language coverage from 100 languages to 534 languages.
Traditionally, AI research and development have focused on refining models, enhancing algorithms, optimizing architectures, and increasing computational power to advance the frontiers of machinelearning. However, a noticeable shift is occurring in how experts approach AI development, centered around Data-Centric AI.
Where would you look for a 2023 state of AI infrastructure analysis, if you really needed one? The answer should be obvious, of course, it’s Tel Aviv …
In the age of data-driven decision-making, access to high-quality and diverse datasets is crucial for training reliable machinelearning models. However, acquiring such data often comes with numerous challenges, ranging from privacy concerns to the scarcity of domain-specific labeled samples.
While mental health disorders like anxiety, depression, and schizophrenia affect a vast number of people globally, a significant percentage of those in need do not receive proper care due to resource limitations and privacy concerns surrounding the collection of personalized medical data.
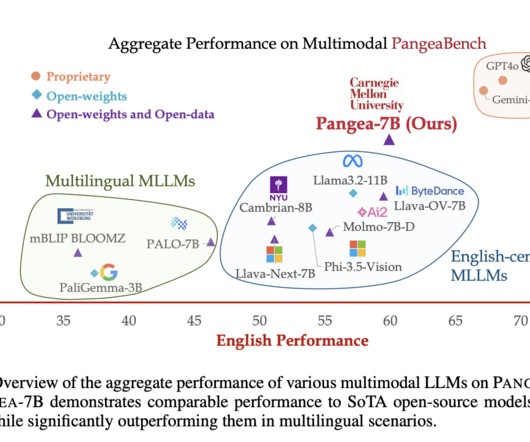
The dataset was designed to address the major challenges of multilingual multimodal learning: datascarcity, cultural nuances, catastrophic forgetting, and evaluation complexity. Moreover, PANGEA matches or even outperforms proprietary models like Gemini-1.5-Pro
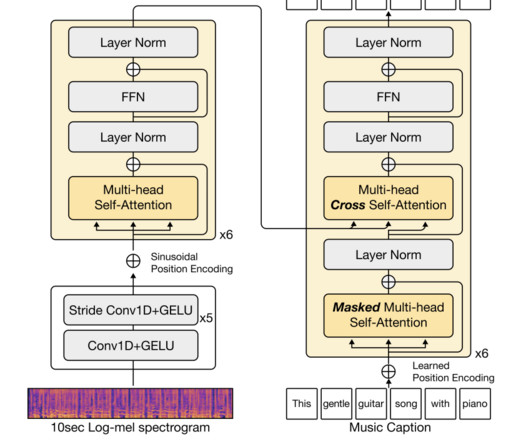
We’ll assume some general familiarity with machinelearning concepts. Datascarcity: Paired natural anguage descriptions of music and corresponding music recordings are extremely scarce, in contrast to the abundance of image/descriptions pairs available online, e.g. in online art galleries or social media.
Existing standards like ISO 26262 provide a framework, but adapting them for deep learning is complex. Deep learning introduces unique hazards and uncertainties, requiring new fault detection and mitigation approaches.
Synthetic data , artificially generated to mimic real data, plays a crucial role in various applications, including machinelearning , data analysis , testing, and privacy protection. However, generating synthetic data for NLP is non-trivial, demanding high linguistic knowledge, creativity, and diversity.
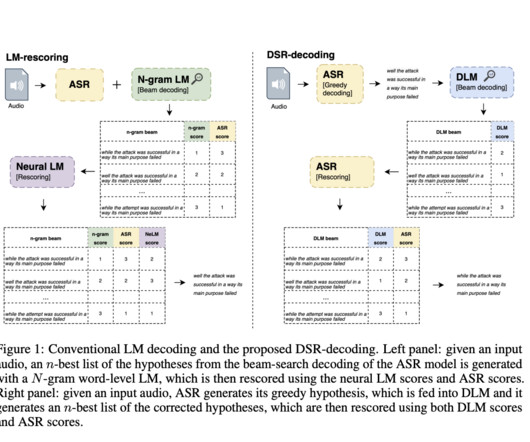
Significant advancements have been made in this field, driven by machinelearning algorithms and large datasets. The DLM’s innovative use of synthetic data addresses the datascarcity issue that has hampered the performance of earlier error correction models.
The post Meet LP-MusicCaps: A Tag-to-Pseudo Caption Generation Approach with Large Language Models to Address the DataScarcity Issue in Automatic Music Captioning appeared first on MarkTechPost.
The framework introduces a novel approach combining classical machine-learning techniques with advanced LLM capabilities. Instead, it utilizes deterministic methods and machine-learning models to ensure accuracy and scalability in trajectory verification.
Datascarcity, privacy and bias are just a few reasons why synthetic data is becoming increasingly important. In this Q&A, Brett Wujek, Senior Manager of Product Strategy at SAS, explains why synthetic data will redefine data management and speed up the production of AI and machinelearning models while cutting [.]
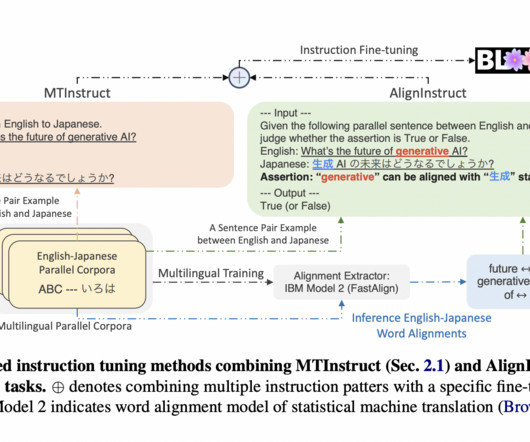
Developed by researchers from Apple, aiming to enhance machine translation, AlignInstruct represents a paradigm shift in tackling datascarcity. It introduces a cross-lingual discriminator, crafted using statistical word alignments, to strengthen the machine translation process.
Privacy Auditing with One (1) Training Run By Thomas Steinke , Milad Nasr , and Matthew Jagielski from Google This research paper introduces a novel method for auditing differentially private (DP) machinelearning systems using just a single training run. The paper also explores alternative strategies to mitigate datascarcity.
Human-sensing applications such as activity recognition, fall detection, and health monitoring have been revolutionized by advancements in artificial intelligence (AI) and machinelearning technologies.
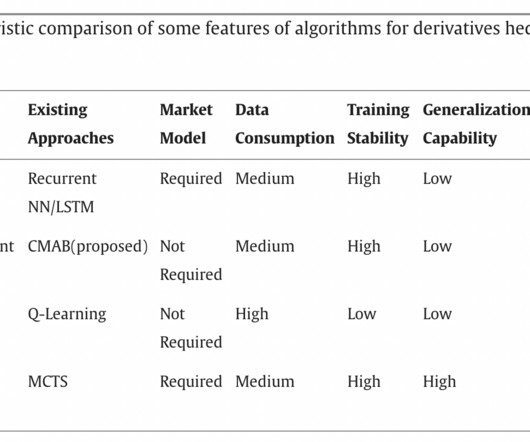
He highlighted the necessity for effective data use by stressing the significant amount of data many AI systems consume. Another researcher highlighted the challenge of considering AI model-free due to market datascarcity for training, particularly in realistic derivative markets.
Self-training has been shown to be helpful in addressing datascarcity for many domains, including vision, speech, and language. Specifically, self-training, or pseudo-labeling, labels unsupervised data and adds that to the training pool.
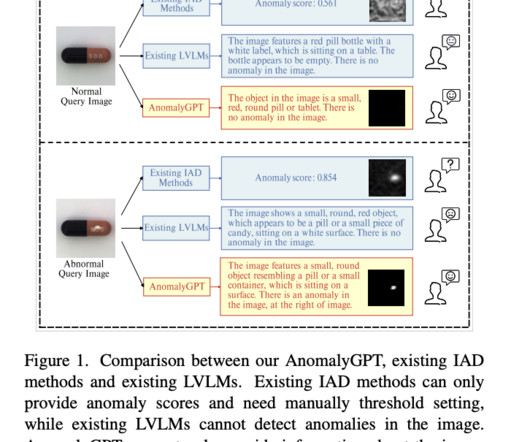
With just a few normal samples, AnomalyGPT can also learn in context, allowing for quick adjustment to new objects. They optimize the LVLM using synthesized anomalous visual-textual data and incorporating IAD expertise. Direct training using IAD data, however, needs to be improved. Datascarcity is the first.
Although fine-tuning with a large amount of high-quality original data remains the ideal approach, our findings highlight the promising potential of synthetic data generation as a viable solution when dealing with datascarcity. Yiyue holds a Ph.D. Outside of work, she enjoys sports, hiking, and traveling.
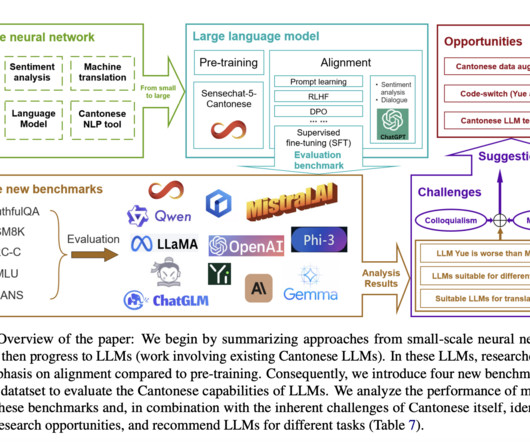
Sentiment analysis has progressed from basic machinelearning to advanced techniques using Hidden Markov Models and Transformers. Machine translation has evolved from rule-based systems to statistical and neural approaches, with recent focus on unsupervised methods and large-scale datasets.
Even given this knowledge, datascarcity and high inter/intra-speaker variability further limit the effectiveness of traditional fine-tuning. However, these approaches assume a priori knowledge of the atypical speech disorder being adapted for -- the diagnosis of which requires expert knowledge that is not always available.
Small-scale atmospheric physics, including the intricate details of storm patterns, temperature gradients, and localized events, requires high-resolution data to be accurately represented. These finer details play an important role in applications ranging from daily weather forecasts to regional planning for disaster resilience.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content