This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
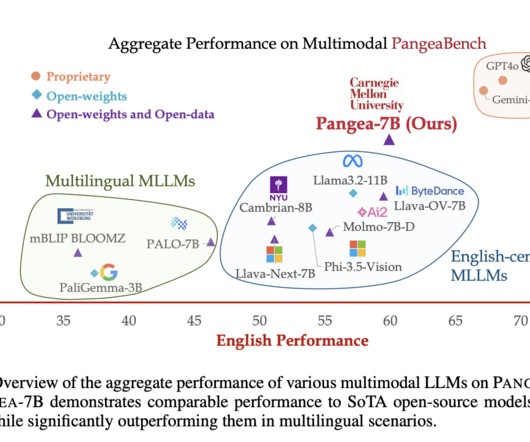
A team of researchers from Carnegie Mellon University introduced PANGEA, a multilingual multimodal LLM designed to bridge linguistic and cultural gaps in visual understanding tasks. PANGEA represents a significant step forward in creating inclusive and robust multilingual multimodal LLMs. Don’t Forget to join our 50k+ ML SubReddit.
However, acquiring such datasets presents significant challenges, including datascarcity, privacy concerns, and high data collection and annotation costs. Artificial (synthetic) data has emerged as a promising solution to these challenges, offering a way to generate data that mimics real-world patterns and characteristics.
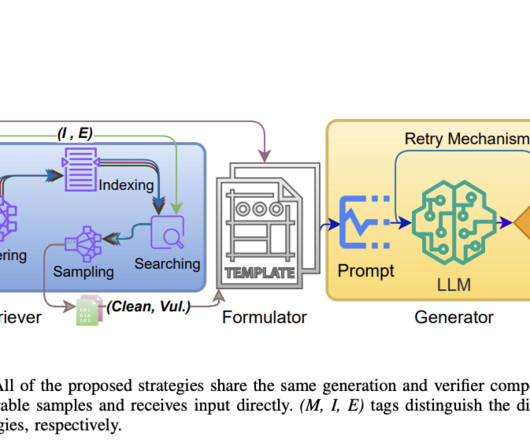
The Mutation strategy prompts the LLM to modify vulnerable code samples, ensuring that the changes do not alter the code’s original functionality. The Injection strategy involves retrieving similar vulnerable and clean code samples, with the LLM injecting the vulnerable logic into the clean code to create new samples.
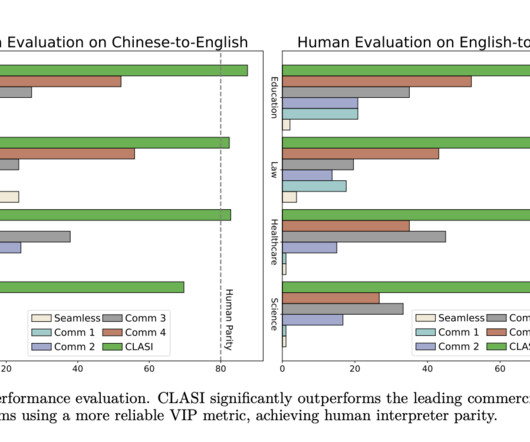
LLMs are suggested to complete the SiST task because of their enormous success with machine and spoken translation. Starting with the read-write policy, which requires LLM only to offer partial translation for input speech, integrating LLM into the SiST takes work. If you like our work, you will love our newsletter.
While deep learning’s scaling effects have driven advancements in AI, particularly in LLMs like GPT, further scaling during training faces limitations due to datascarcity and computational constraints. Also,dont forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
This surprising trend highlights the continued relevance of SLMs and raises important questions about their role in the LLM era, a topic previously overlooked in research. This study examines the role of SMs in the LLM era from two perspectives: collaboration with LLMs and competition against them.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content