This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Notably, the fine-tuning approach employed in TxGemma optimizes predictive accuracy with substantially fewer training samples, providing a crucial advantage in domains where datascarcity is prevalent. Further extending its capabilities, Agentic-Tx, powered by Gemini 2.0,
This capability is changing how we approach AI development, particularly in scenarios where real-world data is scarce, expensive, or privacy-sensitive. In this comprehensive guide, we'll explore LLM-driven synthetic data generation, diving deep into its methods, applications, and best practices.
DataScarcity: Pre-training on small datasets (e.g., In conclusion, NeoBERT represents a paradigm shift for encoder models, bridging the gap between stagnant architectures and modern LLM advancements. Wikipedia + BookCorpus) restricts knowledge diversity. Efficiency tests show NeoBERT processes 4,096-token batches 46.7%
It supports multiple LLM providers, making it compatible with a wide array of hosted and local models, including OpenAI’s models, Anthropic’s Claude, and Google Gemini. Synthetic data is particularly useful in situations where collecting real data is too costly, ethically challenging, or impractical.
However, acquiring such datasets presents significant challenges, including datascarcity, privacy concerns, and high data collection and annotation costs. Artificial (synthetic) data has emerged as a promising solution to these challenges, offering a way to generate data that mimics real-world patterns and characteristics.
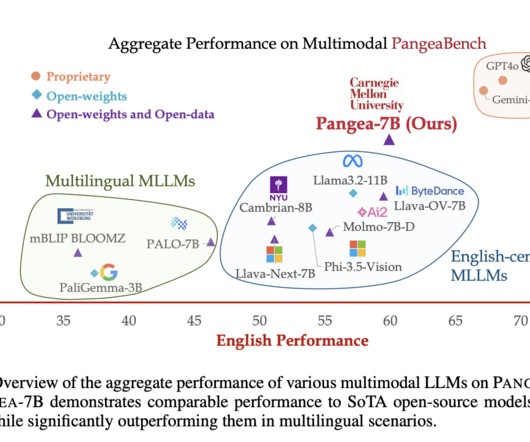
A team of researchers from Carnegie Mellon University introduced PANGEA, a multilingual multimodal LLM designed to bridge linguistic and cultural gaps in visual understanding tasks. PANGEA represents a significant step forward in creating inclusive and robust multilingual multimodal LLMs.
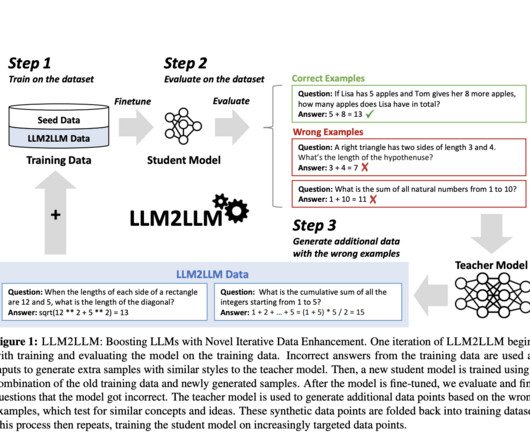
In conclusion, the LLM2LLM framework offers a robust solution to the critical challenge of datascarcity. By harnessing the power of one LLM to improve another, it demonstrates a novel, efficient pathway to fine-tune models for specific tasks with limited initial data. Similarly, on the CaseHOLD dataset, there was a 32.6%
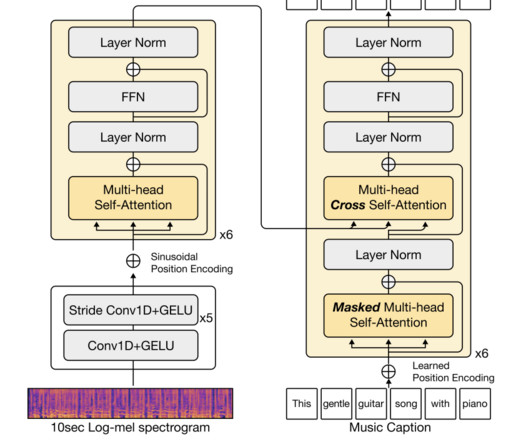
First, they proposed an LLM-based approach to generate a music captioning dataset, LP-MusicCaps. Second, they proposed a systemic evaluation scheme for music captions generated by LLMs. The researchers compared this LLM-based caption generator with template-based methods (tag concatenation, prompt template ) and K2C augmentation.
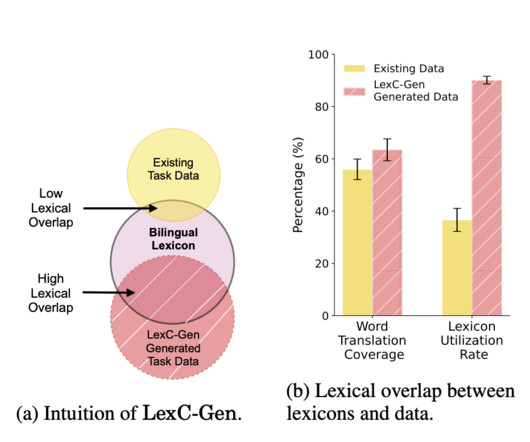
Datascarcity in low-resource languages can be mitigated using word-to-word translations from high-resource languages. However, bilingual lexicons typically need more overlap with task data, leading to inadequate translation coverage. Check out the Paper.
LLMs are suggested to complete the SiST task because of their enormous success with machine and spoken translation. Starting with the read-write policy, which requires LLM only to offer partial translation for input speech, integrating LLM into the SiST takes work.
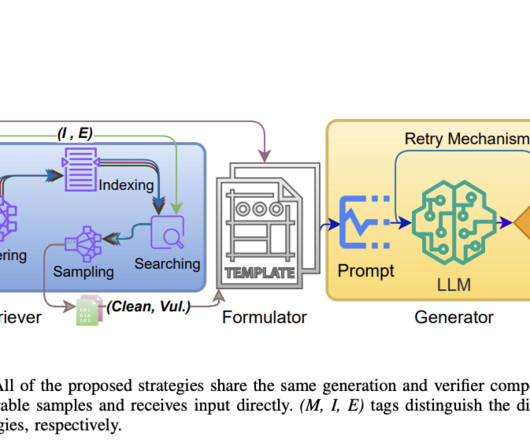
The Mutation strategy prompts the LLM to modify vulnerable code samples, ensuring that the changes do not alter the code’s original functionality. The Injection strategy involves retrieving similar vulnerable and clean code samples, with the LLM injecting the vulnerable logic into the clean code to create new samples.
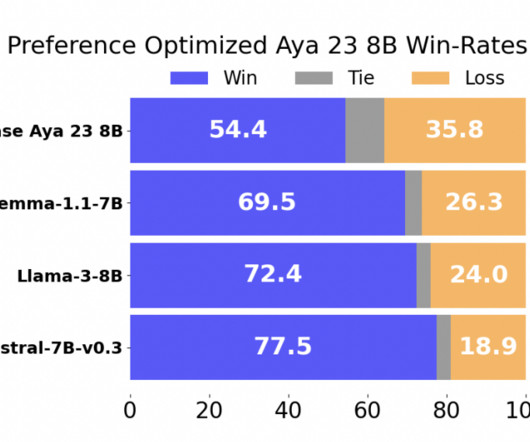
The performance of the preference-trained model was evaluated against several state-of-the-art multilingual LLMs. win rate against Aya 23 8B, the current leading multilingual LLM in its parameter class. The results were impressive, with the preference-trained model achieving a 54.4% Additionally, the model showed a 69.5%
Augmentation Augmentation plays a central role in fine-tuning by extending the capabilities of LLMs by incorporating external data or techniques. For example, augmenting an LLM with legal terminology can significantly improve its performance in drafting contracts or summarizing case law.
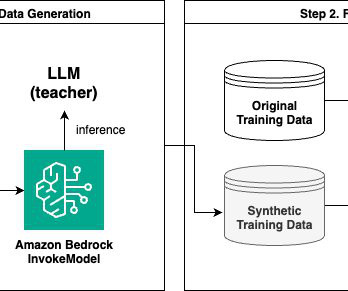
You can create synthetic training data using a larger language model and use it to fine-tune a smaller model, which has the benefit of a quicker turnaround time. In this post, we explore how to use Amazon Bedrock to generate synthetic training data to fine-tune an LLM. The following chart summarizes the judges decisions.
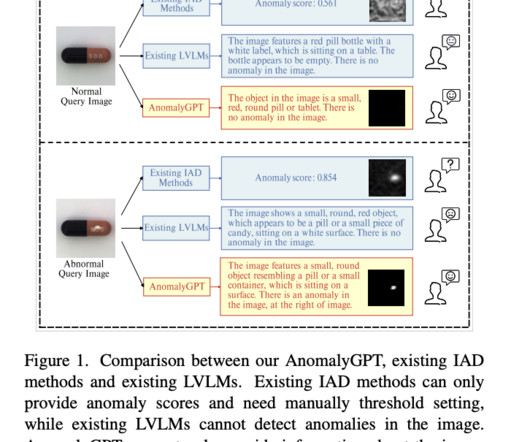
They optimize the LVLM using synthesized anomalous visual-textual data and incorporating IAD expertise. Direct training using IAD data, however, needs to be improved. Datascarcity is the first. It alleviates the constraint of LLM’s restricted ability to generate text outputs.
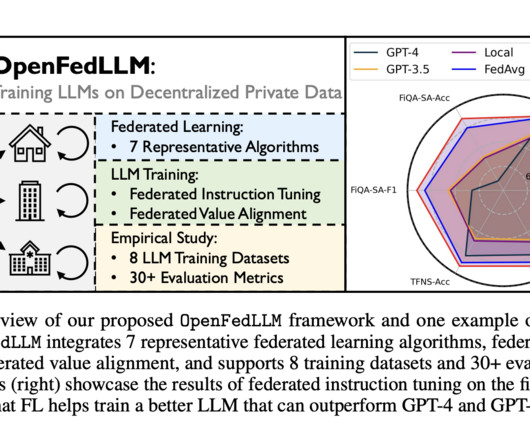
For instance, BloomberGPT excels in finance with private financial data spanning 40 years. Collaborative training on decentralized personal data, without direct sharing, emerges as a critical approach to support the development of modern LLMs amid datascarcity and privacy concerns.
Traditionally, addressing these challenges involved relying on human-labeled data or leveraging LLMs as judges to verify trajectories. While LLM-based solutions have shown promise, they face significant limitations, including sensitivity to input prompts, inconsistent outputs from API-based models, and high operational costs.
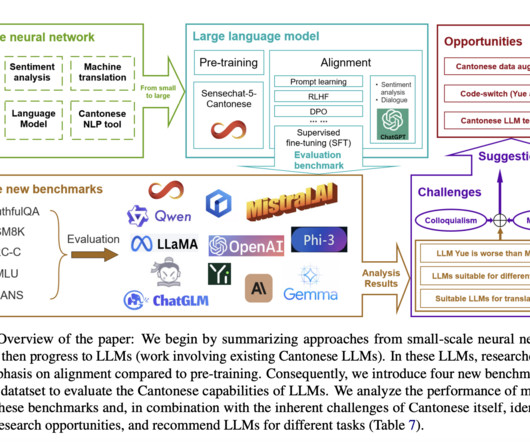
The development of Cantonese-specific LLMs faces significant challenges due to limited research and resources. Most existing Cantonese LLM technology remains closed-source, hindering widespread progress in the field. The scarcity of training data and benchmarks for Cantonese LLMs further complicates development efforts.
Supervised fine-tuning, reinforcement learning techniques like PPO, and alternative methods like DPO and IPO have been explored for refining LLM outputs based on user preferences. The approach generates over a million structured synthetic preferences to address datascarcity.
We review UC Berkeley’s Gorilla LLM which is fine-tuned for tool learning and the Microsoft TaskWeaver framework. AlphaGeometry combines a geometry symbolic model with an LLM used mostly for exploring possible solutions to a given problem. Can we expand the AlphaGeometry approach to mainstream use cases?
Strategy and Data: Non-top-performers highlight strategizing (24%), talent availability (21%), and datascarcity (18%) as their leading challenges. Large language models (LLMs) are a powerful new technology with the potential to revolutionize many industries. Unstructured.IO
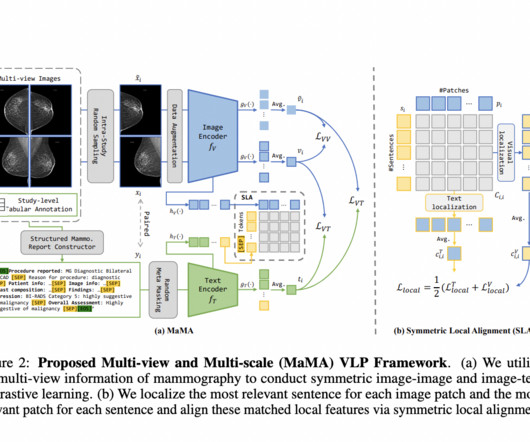
It also uses a symmetric local alignment module to focus on detailed features and a parameter-efficient fine-tuning approach to enhance pre-trained LLMs with medical knowledge. This allows the framework to overcome datascarcity and perform better on mammography tasks.
While deep learning’s scaling effects have driven advancements in AI, particularly in LLMs like GPT, further scaling during training faces limitations due to datascarcity and computational constraints. Also,dont forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
2) Next, we use the LLM to generate a short narrative based on the sentence form commonsense knowledge. Madeleine and coach) using the LLM. (3) 3) Finally, with the conversation participants and narrative as input, we prompt the LLM to generate a full, multi-turn conversation. Madeleine moves a step closer to the goal.” (2)
Bottom) REFLEX adds a “rational” layer above the LLM layer, in which a belief graph is constructed (by iteratively querying the LLM, up/down arrows), containing relevant model-believed facts (white/grey = believed T/F) and their inferential relationships.
Here are some notable examples: Legal Domain Law LLM Assistant SaulLM-7B Equall.ai Codex-Med : Exploring GPT-3 for Healthcare QA While not introducing a new LLM, the Codex-Med study explored the effectiveness of GPT-3.5 models, specifically Codex and InstructGPT, in answering and reasoning about real-world medical questions.
About the NVIDIA Nemotron model family At the forefront of the NVIDIA Nemotron model family is Nemotron-4, as stated by NVIDIA, it is a powerful multilingual large language model (LLM) trained on an impressive 8 trillion text tokens, specifically optimized for English, multilingual, and coding tasks.
This surprising trend highlights the continued relevance of SLMs and raises important questions about their role in the LLM era, a topic previously overlooked in research. This study examines the role of SMs in the LLM era from two perspectives: collaboration with LLMs and competition against them.
With a vision to build a large language model (LLM) trained on Italian data, Fastweb embarked on a journey to make this powerful AI capability available to third parties. To achieve this, the team built an extensive Italian language dataset by combining public sources and acquiring licensed data from publishers and media companies.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content