This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Much like the impact of largelanguagemodels on generative AI, Cosmos represents a new frontier for AI applications in robotics and autonomous systems. Pras Velagapudi, CTO at Agility, comments: Datascarcity and variability are key challenges to successful learning in robot environments.
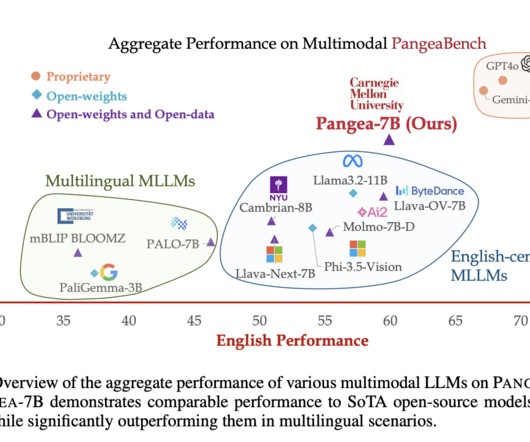
Despite recent advances in multimodal largelanguagemodels (MLLMs), the development of these models has largely centered around English and Western-centric datasets. Moreover, PANGEA matches or even outperforms proprietary models like Gemini-1.5-Pro If you like our work, you will love our newsletter.
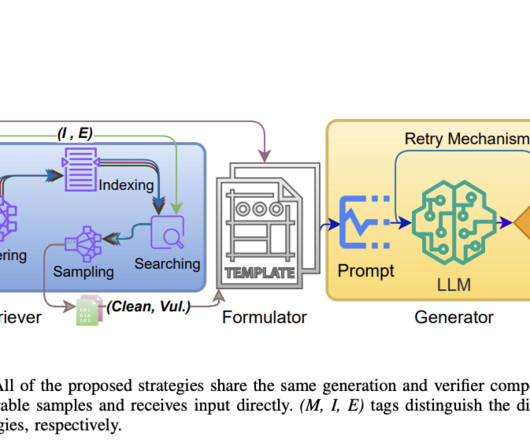
VulScribeR employs largelanguagemodels (LLMs) to generate diverse and realistic vulnerable code samples through three strategies: Mutation, Injection, and Extension. The success of VulScribeR highlights the importance of large-scale data augmentation in the field of vulnerability detection.
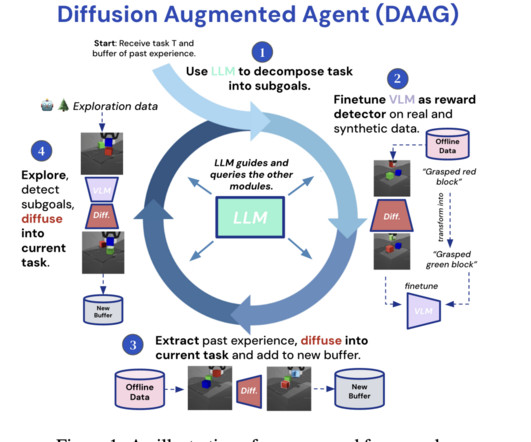
A major issue in RL is the datascarcity in embodied AI, where agents must interact with physical environments. This problem is exacerbated by the need for substantial reward-labeled data to train agents effectively. The largelanguagemodel is the central controller, guiding the vision language and diffusion models.
The rapid advancement of Artificial Intelligence (AI) and Machine Learning (ML) has highlighted the critical need for large, diverse, and high-quality datasets to train and evaluate foundation models. OAK dataset offers a comprehensive resource for AI research, derived from Wikipedia’s main categories.
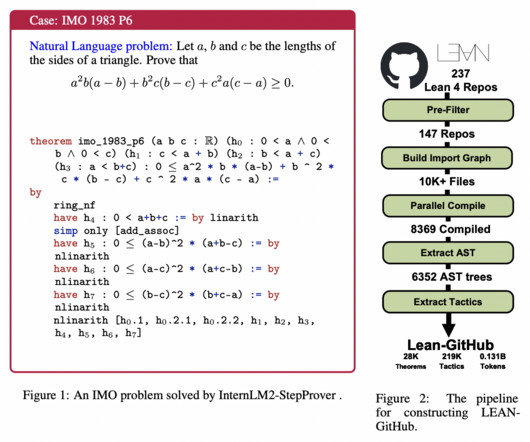
Largelanguagemodels (LLMs) show promise in solving high-school-level math problems using proof assistants, yet their performance still needs to improve due to datascarcity. Formal languages require significant expertise, resulting in limited corpora. If you like our work, you will love our newsletter.
The model’s performance is evaluated using three distinct accuracy metrics: token-level accuracy for individual token assessment, sentence-level accuracy for evaluating coherent text segments, and response-level accuracy for overall output evaluation. If you like our work, you will love our newsletter.
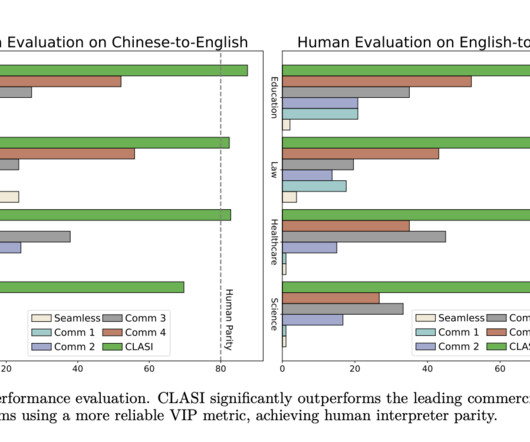
They use a three-stage training methodology—pretraining, ongoing training, and fine-tuning—to tackle the datascarcity of the SiST job. The team trains their model continuously using billions of tokens of low-quality synthetic speech translation data to further their goal of achieving modal alignment between voice and text.
LargeLanguageModels (LLMs) have revolutionized natural language processing in recent years. The pre-train and fine-tune paradigm, exemplified by models like ELMo and BERT, has evolved into prompt-based reasoning used by the GPT family. If you like our work, you will love our newsletter.
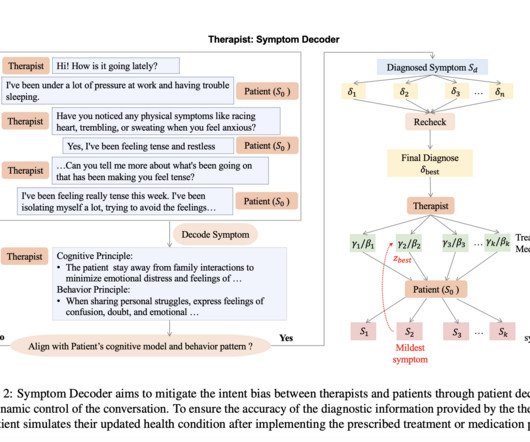
These models are trained on data collected from social media, which introduces bias and may not accurately represent diverse patient experiences. Moreover, privacy concerns and datascarcity hinder the development of robust models for mental health diagnosis and treatment.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content