
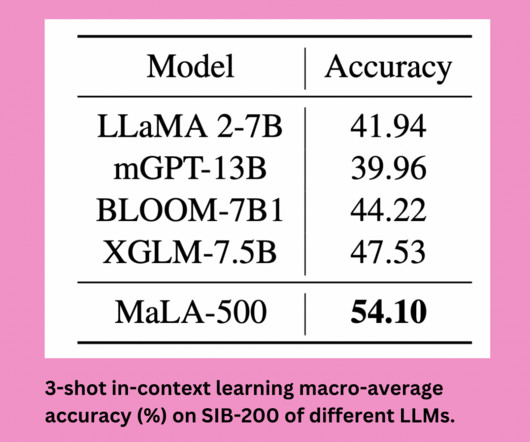
Meet MaLA-500: A Novel Large Language Model Designed to Cover an Extensive Range of 534 Languages
Marktechpost
JANUARY 29, 2024
With new releases and introductions in the field of Artificial Intelligence (AI), Large Language Models (LLMs) are advancing significantly. They are showcasing their incredible capability of generating and comprehending natural language. All credit for this research goes to the researchers of this project.























Let's personalize your content