This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
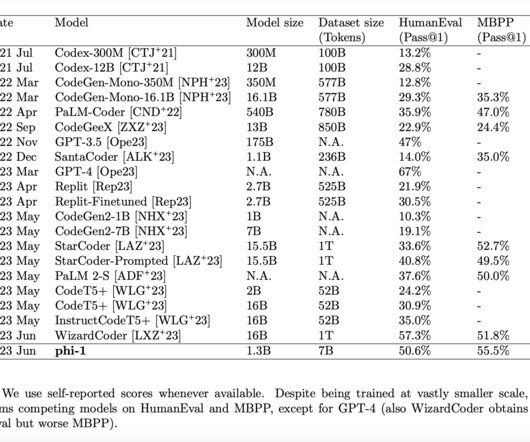
Recurrent neuralnetworks (RNNs) have been foundational in machine learning for addressing various sequence-based problems, including time series forecasting and natural language processing. indicating strong results across varying levels of dataquality. while the minGRU scored 79.4, Let’s collaborate!
LLMs are deep neuralnetworks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code. They are huge, complex, and data-hungry. They also need a lot of data to learn from, which can raise dataquality, privacy, and ethics issues.
Summary: Artificial NeuralNetwork (ANNs) are computational models inspired by the human brain, enabling machines to learn from data. Introduction Artificial NeuralNetwork (ANNs) have emerged as a cornerstone of Artificial Intelligence and Machine Learning , revolutionising how computers process information and learn from data.
Choosing the best appropriate activation function can help one get better results with even reduced dataquality; hence, […]. Introduction In deep learning, the activation functions are one of the essential parameters in training and building a deep learning model that makes accurate predictions.
In the quest to uncover the fundamental particles and forces of nature, one of the critical challenges facing high-energy experiments at the Large Hadron Collider (LHC) is ensuring the quality of the vast amounts of data collected. Autoencoders, a specialised type of neuralnetwork, are designed for unsupervised learning tasks.
Enhancing video tokenization for more compact processing, incorporating additional modalities like audio, and improving video dataquality and quantity are critical next steps. Despite its significant achievements, the work acknowledges limitations and areas ripe for future exploration.
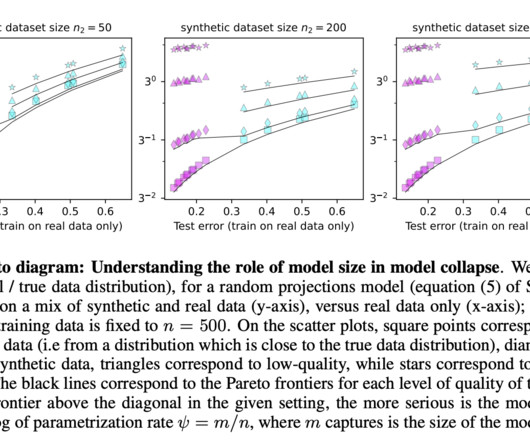
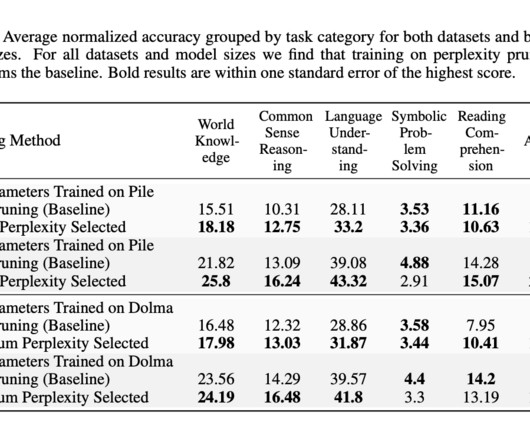
Beyond Scale: DataQuality for AI Infrastructure The trajectory of AI over the past decade has been driven largely by the scale of data available for training and the ability to process it with increasingly powerful compute & experimental models. Scale matters, but quality matters more. The key insight?
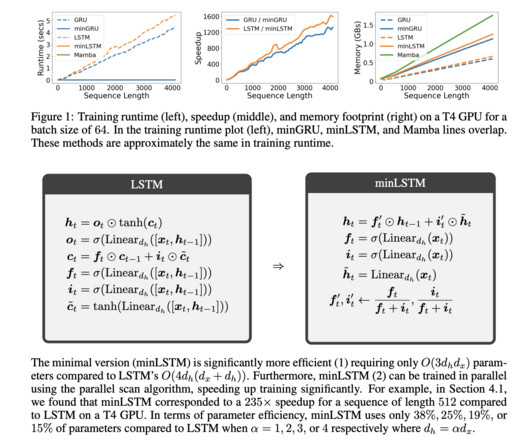
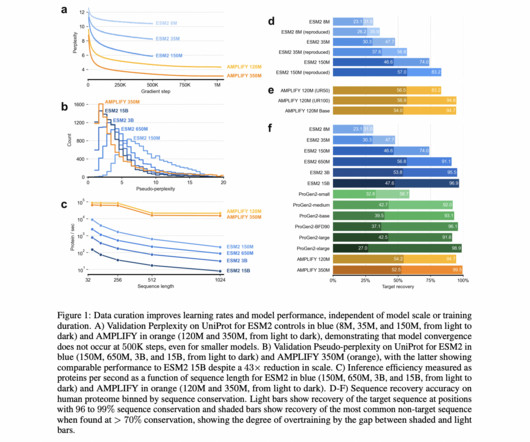
Unlike large-scale models like ESM2 and ProGen2, AMPLIFY focuses on improving dataquality rather than model size, achieving superior performance with 43 times fewer parameters. The team evaluated three strategies—dataquality, quantity, and training steps—finding that improving dataquality alone can create state-of-the-art models.
Summary: Autoencoders are powerful neuralnetworks used for deep learning. They compress input data into lower-dimensional representations while preserving essential features. These powerful neuralnetworks learn to compress data into smaller representations and then reconstruct it back to its original form.
In this guide, we’ll talk about Convolutional NeuralNetworks, how to train a CNN, what applications CNNs can be used for, and best practices for using CNNs. What Are Convolutional NeuralNetworks CNN? CNNs are artificial neuralnetworks built to handle data having a grid-like architecture, such as photos or movies.
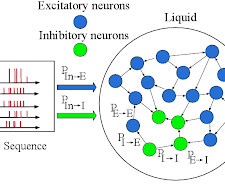
Liquid NeuralNetworks: Research focuses on developing networks that can adapt continuously to changing data environments without catastrophic forgetting. These networks excel at processing time series data, making them suitable for applications like financial forecasting and climate modeling.
Since the discovery of the Transformer design, the art of training massive artificial neuralnetworks has advanced enormously, but the science underlying this accomplishment is still in its infancy. In this paper, they investigate how the dataquality might be improved along a different axis.
It automatically identifies vulnerable individual data points and introduces “noise” to obscure their specific information. Although adding noise slightly reduces output accuracy (this is the “cost” of differential privacy), it does not compromise utility or dataquality compared to traditional data masking techniques.
Existing methods to address cold start in recommendation systems depend on heuristics to boost item rankings or use additional information to compensate for the lack of interaction data. Next, non-stationary distribution shifts are managed through periodic model retraining, which is costly and unstable due to varying dataquality.
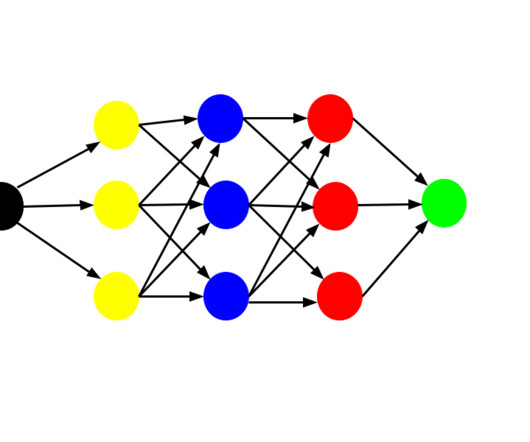
One of the core areas of development within machine learning is neuralnetworks, which are especially critical for tasks such as image recognition, language processing, and autonomous decision-making. These models are governed by scaling laws, suggesting that increasing model size and the amount of training data enhances performance.
Photo by david clarke on Unsplash The most recent breakthroughs in language models have been the use of neuralnetwork architectures to represent text. 2013 Word2Vec is a neuralnetwork model that uses n-grams by training on context windows of words. The more hidden layers an architecture has, the deeper the network.)
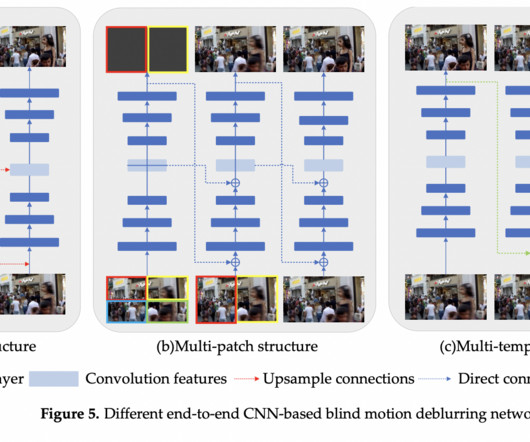
The researchers present a categorization system that uses backbone networks to organize these methods. Most picture deblurring methods use paired images to train their neuralnetworks. The initial step is using a neuralnetwork to estimate the blur kernel. Two steps comprised the process of deblurring images.
In this framework, an agent, like a self-driving car, navigates an environment based on observed sensory data, taking actions to maximize cumulative future rewards. DRL models, such as Deep Q-Networks (DQN), estimate optimal action policies by training neuralnetworks to approximate the maximum expected future rewards.
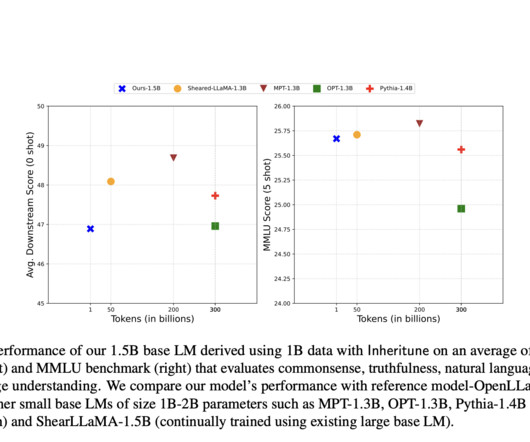
In contrast, the Inheritune, efficiently trains small base LMs by inheriting transformer blocks from larger models and training on a small subset of data, achieving comparable performance with significantly fewer computational resources. In the experiments, the researchers use a 1 billion token subset of the Redpajama v1 dataset to train a 1.5
However, there are also challenges that businesses must address to maximise the various benefits of data-driven and AI-driven approaches. Dataquality : Both approaches’ success depends on the data’s accuracy and completeness. What are the Three Biggest Challenges of These Approaches?
Traditional data pruning methods include simple rules-based filtering and basic classifiers to identify high-quality samples. Advanced techniques have emerged, utilizing neuralnetwork-based heuristics to assess dataquality based on various metrics such as feature similarity or sample difficulty.
The core of Distilabel’s framework revolves around the GAN architecture, which includes two primary neuralnetworks: a generator and a discriminator. The competitive dynamic between the two networks allows for continuous refinement of the synthetic data.
Reinforcement Learning Techniques: Deep Q Network (DQN): DQN combines Q-learning with deep neuralnetworks to handle high-dimensional state spaces. The human-agent joint learning system provides a practical approach to reducing human workload while maintaining dataquality, which is crucial for robot manipulation tasks.
The necessary hardware, software, and data storage costs were very high. It all started in 2012 with AlexNet, a deep learning model that showed the true potential of neuralnetworks. AI can also increase biases if trained on biased data, leading to unfair outcomes. But things have changed a lot since then.
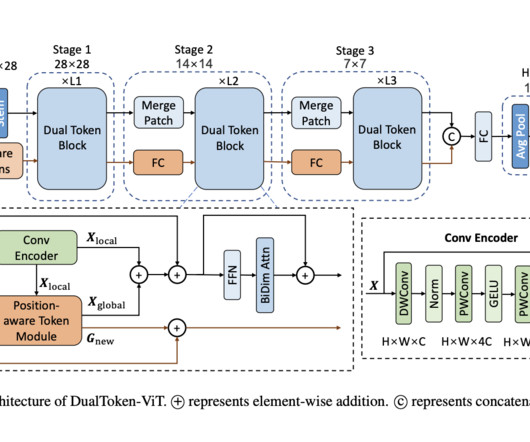
This is because, whereas the size of the convolutional kernel constrains convolutional neuralnetworks (CNNs) and can only extract local information, self-attention can remove global information from the picture, delivering adequate and meaningful visual characteristics.
Example of a deep learning visualization: small convolutional neuralnetwork CNN, notice how the thickness of the colorful lines indicates the weight of the neural pathways | Source How is deep learning visualization different from traditional ML visualization? Let’s take a computer vision model as an example.
It consists of two separate neuralnetworks: one for encoding user features and the other for encoding item features. While these systems enhance user engagement and drive revenue, they also present challenges like dataquality and privacy concerns.
The underpinnings of LLMs like OpenAI's GPT-3 or its successor GPT-4 lie in deep learning, a subset of AI, which leverages neuralnetworks with three or more layers. Training Data : The essence of a language model lies in its training data.
If you want an overview of the Machine Learning Process, it can be categorized into 3 wide buckets: Collection of Data: Collection of Relevant data is key for building a Machine learning model. It isn't easy to collect a good amount of qualitydata. You need to know two basic terminologies here, Features and Labels.
Tools like layer-wise relevance propagation can help visualize the elements of a neuralnetwork that contribute to specific outcomes, providing the necessary transparency. This includes considering patient population, disease conditions, and scanning quality.
While such studies are still missing a full view of the landscape, they suggest that focusing on the dataquality might be way more beneficial than prioritizing scalability when fine-tuning LLMs. Unraveling the exact scaling laws that govern the balance between demonstration data and RLHF or similar techniques (e.g.
One more embellishment is to use a graph neuralnetwork (GNN) trained on the documents. A generalized, unbundled workflow A more accountable approach to GraphRAG is to unbundle the process of knowledge graph construction, paying special attention to dataquality.
Despite these technologies, challenges still need to be addressed, including limited breakthroughs in identifying new drug targets and dataquality issues. VirtuDockDL’s integration of ligand- and structure-based screening provides efficient and accurate virtual screening.
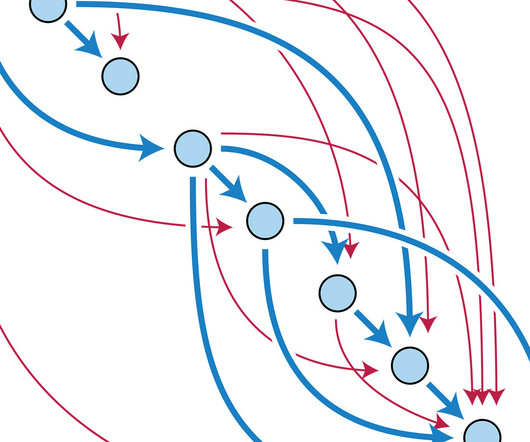
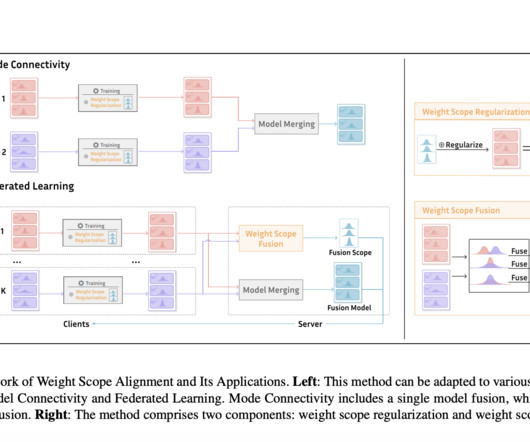
One intriguing potential benefit of model interpolation is its potential to enhance researchers’ understanding of the features of neuralnetworks’ mode connectivity. The method of choice for model fusing in deep neuralnetworks is coordinate-based parameter averaging.
Dataquality control: Robust dataset labeling and annotation tools incorporate quality control mechanisms such as inter-annotator agreement analysis, review workflows, and data validation checks to ensure the accuracy and reliability of annotations. Data monitoring tools help monitor the quality of the data.
To minimize computational demands, they introduced innovations such as multi-query attention mechanisms and gated feed-forward neuralnetworks (FFNs). At the same time, the gated FFN structure allows the model to route information through the network, improving efficiency dynamically.
Scikit-learn: A simple and efficient tool for data mining and data analysis, particularly for building and evaluating machine learning models. At the same time, Keras is a high-level neuralnetwork API that runs on top of TensorFlow and simplifies the process of building and training deep learning models.
To augment the dataquality, the Mini-Gemini framework collects and produces more data based on public resources, including task-oriented instructions, generation-related data, and high-resolution responses, with the increased amount and enhanced quality improving the overall performance and capabilities of the model.
Deep learning is a branch of machine learning that makes use of neuralnetworks with numerous layers to discover intricate data patterns. Deep learning models use artificial neuralnetworks to learn from data. Deep learning models use artificial neuralnetworks to learn from data.
Summary : Deep Learning engineers specialise in designing, developing, and implementing neuralnetworks to solve complex problems. They work on complex problems that require advanced neuralnetworks to analyse vast amounts of data.
Data Management and Preprocessing for Accurate Predictions DataQuality is Paramount: The foundation of robust ML in demand forecasting lies in high-qualitydata. Retailers must ensure data is clean, consistent, and free from anomalies. Consistently review and purify data to uphold its accuracy.
Though high-quality training datasets are vital to continued advancement in the field of ML, much of the data on which the field relies today is nearly a decade old (e.g., Despite the importance of data, ML research to date has been dominated by a focus on models. LAION or The Pile ).
On Thursday, Chelsea Finn, PhD, Assistant Professor at Stanford University discussed how sometimes neuralnetworks can hallucinate and be quite incorrect, the repercussions, and how can we address these issues.
While LLMs offer potential advantages in terms of scalability and cost-efficiency, they also present meaningful challenges, especially concerning dataquality, biases, and ethical considerations. They use neuralnetworks that are inspired by the structure and function of the human brain. How Do Large Language Models Work?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content