This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As emerging DevOps trends redefine softwaredevelopment, companies leverage advanced capabilities to speed up their AI adoption. When unstructured data surfaces during AI development, the DevOps process plays a crucial role in data cleansing, ultimately enhancing the overall model quality.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Deep learning is a branch of machine learning that makes use of neural networks with numerous layers to discover intricate data patterns. Deep learning models use artificial neural networks to learn from data. Online Learning : Incremental training of the model on new data as it arrives.
SageMaker JumpStart is a machine learning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account. It’s serverless so you don’t have to manage the infrastructure.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines. He specializes in designing, building, and optimizing large-scale data solutions.
As industries begin adopting processes dependent on machine learning (ML) technologies, it is critical to establish machine learning operations (MLOps) that scale to support growth and utilization of this technology. There were noticeable challenges when running ML workflows in the cloud.
In addition to traditional custom-tailored deep learning models, SageMaker Ground Truth also supports generative AI use cases, enabling the generation of high-quality training data for artificial intelligence and machine learning (AI/ML) models. To learn more, see Use Amazon SageMaker Ground Truth Plus to Label Data.
Michael Dziedzic on Unsplash I am often asked by prospective clients to explain the artificial intelligence (AI) software process, and I have recently been asked by managers with extensive softwaredevelopment and data science experience who wanted to implement MLOps.
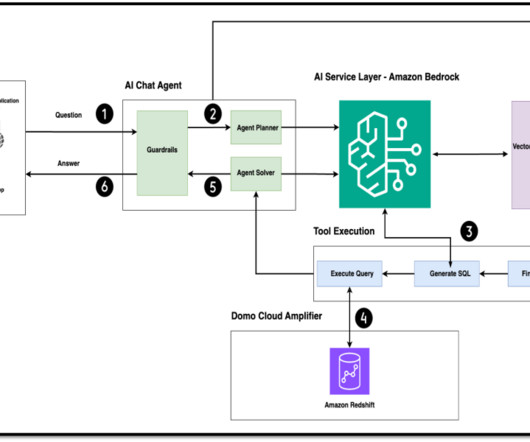
Recognizing this challenge as an opportunity for innovation, F1 partnered with Amazon Web Services (AWS) to develop an AI-driven solution using Amazon Bedrock to streamline issue resolution. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
Steven Hillion is the Senior Vice President of Data and AI at Astronomer , where he leverages his extensive academic background in research mathematics and over 15 years of experience in Silicon Valley's machine learning platform development. Can you elaborate on the use of synthetic data to fine-tune smaller models for accuracy?
LLMs in comparison with traditional ML models Unlike traditional machine learning models, which often require extensive feature engineering and domain-specific adjustments, LLMs can generalize from vast datasets without the need for such tailored configurations. This makes them versatile and highly adaptable across different use cases.
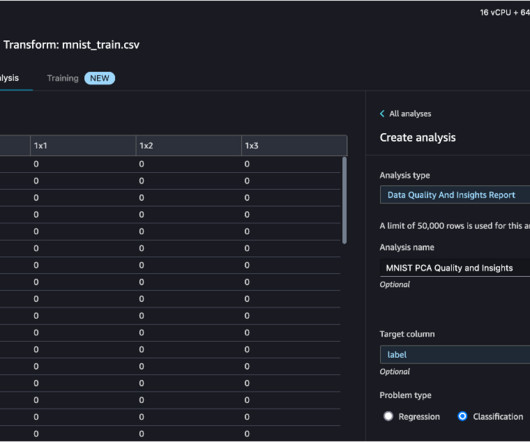
In the world of machine learning (ML), the quality of the dataset is of significant importance to model predictability. Although more data is usually better, large datasets with a high number of features can sometimes lead to non-optimal model performance due to the curse of dimensionality. For Target column , choose label.
As machine learning (ML) models have improved, data scientists, ML engineers and researchers have shifted more of their attention to defining and bettering dataquality. Applying these techniques allows ML practitioners to reduce the amount of data required to train an ML model.
Amazon SageMaker provides purpose-built tools for machine learning operations (MLOps) to help automate and standardize processes across the ML lifecycle. In this post, we describe how Philips partnered with AWS to develop AI ToolSuite—a scalable, secure, and compliant ML platform on SageMaker.
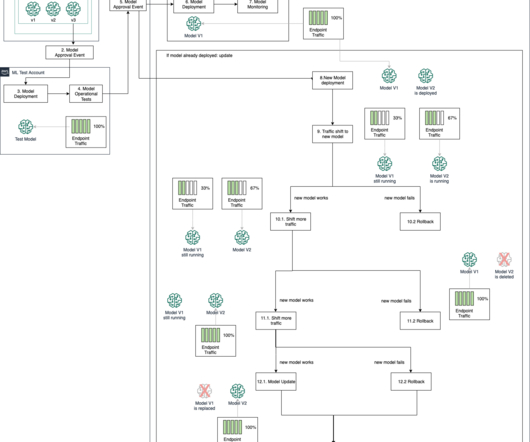
After you build, train, and evaluate your machine learning (ML) model to ensure it’s solving the intended business problem proposed, you want to deploy that model to enable decision-making in business operations. SageMaker deployment guardrails Guardrails are an essential part of softwaredevelopment.
Therefore, when the Principal team started tackling this project, they knew that ensuring the highest standard of data security such as regulatory compliance, data privacy, and dataquality would be a non-negotiable, key requirement.
Few nonusers (2%) report that lack of data or dataquality is an issue, and only 1.3% AI users are definitely facing these problems: 7% report that dataquality has hindered further adoption, and 4% cite the difficulty of training a model on their data. Deploying and managing AI products isn’t simple.
Although machine learning (ML) can provide valuable insights, ML experts were needed to build customer churn prediction models until the introduction of Amazon SageMaker Canvas. Additional key topics Advanced metrics are not the only important tools available to you for evaluating and improving ML model performance.
This is the common belief that if you just build cool software, people will line up to buy it. This never works, and the solution is a robust marketing process connected with your softwaredevelopment process. Bad data for them could mean a provider gets more shifts than they can handle, leading to burnout.
Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. Introduction Machine Learning ( ML ) is revolutionising industries, from healthcare and finance to retail and manufacturing. Fundamental Programming Skills Strong programming skills are essential for success in ML.
As an MLOps engineer on your team, you are often tasked with improving the workflow of your data scientists by adding capabilities to your ML platform or by building standalone tools for them to use. And since you are reading this article, the data scientists you support have probably reached out for help.
Compilation or integration to optimized runtime ML compilers, such as Amazon SageMaker Neo , apply techniques such as operator fusion, memory planning, graph optimizations, and automatic integration to optimized inference libraries. Rohith Nallamaddi is a SoftwareDevelopment Engineer at AWS.
It provides a detailed overview of each library’s unique contributions and explains how they can be combined to create a functional system that can detect and correct linguistic errors in text data. Training dataquality and bias: ML-based grammar checkers heavily rely on training data to learn patterns and make predictions.
This includes the tools and techniques we used to streamline the ML model development and deployment processes, as well as the measures taken to monitor and maintain models in a production environment. Costs: Oftentimes, cost is the most important aspect of any ML model deployment. I would say the same happened in our case.
His presentation also highlights the ways that Snorkel’s platform, Snorkel Flow, enables users to rapidly and programmatically label and develop datasets and then use them to train ML models. So all of this points to the pain or pessimistic bottleneck “takes” around data.
His presentation also highlights the ways that Snorkel’s platform, Snorkel Flow, enables users to rapidly and programmatically label and develop datasets and then use them to train ML models. So all of this points to the pain or pessimistic bottleneck “takes” around data.
YData By enhancing the caliber of training datasets, YData offers a data-centric platform that speeds up the creation and raises the return on investment of AI solutions. Data scientists can now enhance datasets using cutting-edge synthetic data generation and automated dataquality profiling.
According to Gartner, demand forecasting is the most widely used ML application in supply chain planning. We started with data loading and preprocessing, fixing optimization issues to allow the model to process years of historical across all 8,000 stores. Several breakthroughs enabled us to fix dataquality issues within the dataset.
There are also a variety of capabilities that can be very useful for ML/Data Science Practitioners for data related or feature related tasks. Data Tasks ChatGPT can handle a wide range of data-related tasks by writing and executing Python code behind the scenes, without users needing coding expertise.
Once the data is loaded into the data warehouse, it can be queried by business analysts and data scientists to perform various analyses such as customer segmentation, product recommendations, and trend analysis.
While each of them offers exciting perspectives for research, a real-life product needs to combine the data, the model, and the human-machine interaction into a coherent system. AI development is a highly collaborative enterprise. Train your ML model from scratch.
Automation eliminates potential mistakes and enhances the dataquality of the system. Step 3: Comprehensive Strategy Development While the two previous steps shape the background for your automation path, at this stage, you should start creating a strategy relying on the collected information.
This article was originally an episode of the MLOps Live , an interactive Q&A session where ML practitioners answer questions from other ML practitioners. Every episode is focused on one specific ML topic, and during this one, we talked to Jason Falks about deploying conversational AI products to production. Stephen: Great.
Many customers are looking for guidance on how to manage security, privacy, and compliance as they develop generative AI applications. Build organizational resiliency around generative AI Organizations can start adopting ways to build their capacity and capabilities for AI/ML and generative AI security within their organizations.
Techniques such as distillation, RAG, quantization, and, of course, dataquality curation have been developed to empower smaller and more efficient models. WATCH VIDEOS 🔎 ML Research Who is Harry Potter? Anysphere raised $8 million to build an AI native softwaredevelopment environment.
He joined the company as a softwaredeveloper in 2004 after studying computer science with a heavy focus on databases, distributed systems, softwaredevelopment processes, and genetic algorithms. By 2005, he was responsible for the Database Optimizer team and in 2007 he became Head of Research & Development.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and ML engineers to build and deploy models at scale.
Generative artificial intelligence (AI) has revolutionized this by allowing users to interact with data through natural language queries, providing instant insights and visualizations without needing technical expertise. This can democratize data access and speed up analysis.
LLMs have revolutionized softwaredevelopment by automating coding tasks and bridging the natural language and programming gap. This limitation arises from the scarcity of high-quality parallel code data in pre-training datasets and the inherent complexity of parallel programming. parameters.
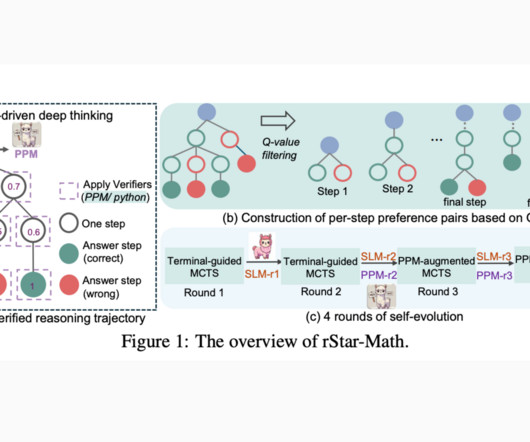
Technical Innovations and Benefits rStar-Maths success is underpinned by three core innovations: Code-Augmented CoT Data Synthesis: The system uses MCTS rollouts to generate step-by-step verified reasoning trajectories. Dont Forget to join our 60k+ ML SubReddit. Check out the Paper.
The benefits of this solution are: You can flexibly achieve data cleaning, sanitizing, and dataquality management in addition to chunking and embedding. You can build and manage an incremental data pipeline to update embeddings on Vectorstore at scale. You can choose a wide variety of embedding models.
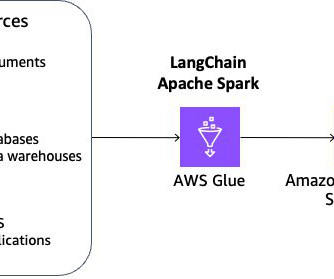
There are various technologies that help operationalize and optimize the process of field trials, including data management and analytics, IoT, remote sensing, robotics, machine learning (ML), and now generative AI. Multi-source data is initially received and stored in an Amazon Simple Storage Service (Amazon S3) data lake.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content