This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Intelligent insights and recommendations Using its large knowledge base and advanced natural language processing (NLP) capabilities, the LLM provides intelligent insights and recommendations based on the analyzed patient-physician interaction. These data sources provide contextual information and serve as a knowledge base for the LLM.
The Role of Data Scientists and MLEngineers in Health Informatics At the heart of the Age of Health Informatics are data scientists and MLengineers who play a critical role in harnessing the power of data and developing intelligent algorithms.
Visualizing deep learning models can help us with several different objectives: Interpretability and explainability: The performance of deep learning models is, at times, staggering, even for seasoned data scientists and MLengineers. Data scientists and MLengineers: Creating and training deep learning models is no easy feat.
Among other topics, he highlighted how visual prompts and parameter-efficient models enable rapid iteration for improved dataquality and model performance. He also described a near future where large companies will augment the performance of their finance and tax professionals with large language models, co-pilots, and AI agents.
Among other topics, he highlighted how visual prompts and parameter-efficient models enable rapid iteration for improved dataquality and model performance. He also described a near future where large companies will augment the performance of their finance and tax professionals with large language models, co-pilots, and AI agents.
The center aimed to address recurring bottlenecks in their ML projects and improve collaborative workflows between data scientists and subject-matter experts. In this presentation, center NLPEngineer James Dunham shares takeaways from the half-dozen project teams who used Snorkel in the past year.
The center aimed to address recurring bottlenecks in their ML projects and improve collaborative workflows between data scientists and subject-matter experts. In this presentation, center NLPEngineer James Dunham shares takeaways from the half-dozen project teams who used Snorkel in the past year.
The center aimed to address recurring bottlenecks in their ML projects and improve collaborative workflows between data scientists and subject-matter experts. In this presentation, center NLPEngineer James Dunham shares takeaways from the half-dozen project teams who used Snorkel in the past year.
Instead of exclusively relying on a singular data development technique, leverage a variety of techniques such as promoting, RAG, and fine-tuning for the most optimal outcome. Focus on improving dataquality and transforming manual data development processes into programmatic operations to scale fine-tuning.
Organizations struggle in multiple aspects, especially in modern-day dataengineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. More features mean more data consumed upstream.
And even on the operation side of things, is there a separate operations team, and then you have your research or mlengineers doing these pipelines and stuff? How do you ensure dataquality when building NLP products? How would you ensure that your data is high-quality throughout the life cycle of the product?
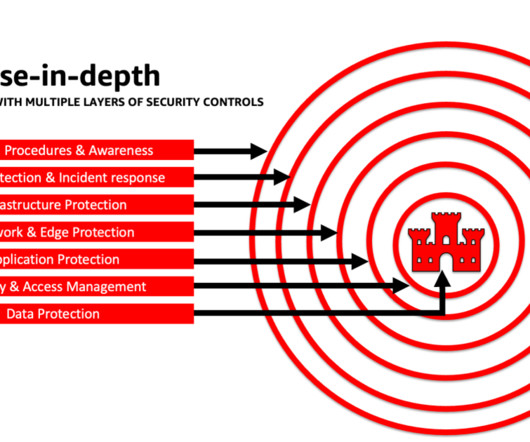
The goal of this post is to empower AI and machine learning (ML) engineers, data scientists, solutions architects, security teams, and other stakeholders to have a common mental model and framework to apply security best practices, allowing AI/ML teams to move fast without trading off security for speed.
Getting a workflow ready which takes your data from its raw form to predictions while maintaining responsiveness and flexibility is the real deal. At that point, the Data Scientists or MLEngineers become curious and start looking for such implementations. Both these areas often demand large-scale model training.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and MLengineers to build and deploy models at scale.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content