This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enterprise-wide AI adoption faces barriers like dataquality, infrastructure constraints, and high costs. While Cirrascale does not offer DataQuality type services, we do partner with companies that can assist with Data issues. How does Cirrascale address these challenges for businesses scaling AI initiatives?
In this post, I want to shift the conversation to how Deepseek is redefining the future of machine learning engineering. It has already inspired me to set new goals for 2025, and I hope it can do the same for other MLengineers. It is fascinating what Deepseek has achieved with their top noche engineering skill.
Furthermore, evaluation processes are important not only for LLMs, but are becoming essential for assessing prompt template quality, input dataquality, and ultimately, the entire application stack. In this post, we show how to use FMEval and Amazon SageMaker to programmatically evaluate LLMs.
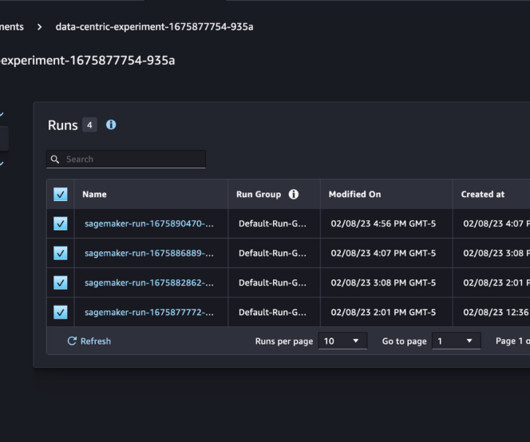
TWCo data scientists and MLengineers took advantage of automation, detailed experiment tracking, integrated training, and deployment pipelines to help scale MLOps effectively. The DataQuality Check part of the pipeline creates baseline statistics for the monitoring task in the inference pipeline.
Early and proactive detection of deviations in model quality enables you to take corrective actions, such as retraining models, auditing upstream systems, or fixing quality issues without having to monitor models manually or build additional tooling. Ajay Raghunathan is a Machine Learning Engineer at AWS.
However, there are many clear benefits of modernizing our ML platform and moving to Amazon SageMaker Studio and Amazon SageMaker Pipelines. Monitoring – Continuous surveillance completes checks for drifts related to dataquality, model quality, and feature attribution. Workflow B corresponds to model quality drift checks.
Dataquality control: Robust dataset labeling and annotation tools incorporate quality control mechanisms such as inter-annotator agreement analysis, review workflows, and data validation checks to ensure the accuracy and reliability of annotations. Data monitoring tools help monitor the quality of the data.
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Custom Spark commands can also expand the over 300 built-in data transformations. Other analyses are also available to help you visualize and understand your data.
As machine learning (ML) models have improved, data scientists, MLengineers and researchers have shifted more of their attention to defining and bettering dataquality. Applying these techniques allows ML practitioners to reduce the amount of data required to train an ML model.
Regulatory compliance By integrating the extracted insights and recommendations into clinical trial management systems and EHRs, this approach facilitates compliance with regulatory requirements for data capture, adverse event reporting, and trial monitoring. He helps customers implement big data, machine learning, and analytics solutions.
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any MLengineer, data scientist, or data analyst.
Amazon SageMaker provides purpose-built tools for machine learning operations (MLOps) to help automate and standardize processes across the ML lifecycle. In this post, we describe how Philips partnered with AWS to develop AI ToolSuite—a scalable, secure, and compliant ML platform on SageMaker.
Fundamental Programming Skills Strong programming skills are essential for success in ML. This section will highlight the critical programming languages and concepts MLengineers should master, including Python, R , and C++, and an understanding of data structures and algorithms. during the forecast period.
You may have gaps in skills and technologies, including operationalizing ML solutions, implementing ML services, and managing ML projects for rapid iterations. Ensuring dataquality, governance, and security may slow down or stall ML projects. We recognize that customers have different starting points.
The Role of Data Scientists and MLEngineers in Health Informatics At the heart of the Age of Health Informatics are data scientists and MLengineers who play a critical role in harnessing the power of data and developing intelligent algorithms.
Visualizing deep learning models can help us with several different objectives: Interpretability and explainability: The performance of deep learning models is, at times, staggering, even for seasoned data scientists and MLengineers. Data scientists and MLengineers: Creating and training deep learning models is no easy feat.
And usually what ends up happening is that some poor data scientist or MLengineer has to manually troubleshoot this in a Jupyter Notebook. So this path on the right side of the production icon is what we’re calling ML observability. We have four pillars that we use when thinking about ML observability.
And usually what ends up happening is that some poor data scientist or MLengineer has to manually troubleshoot this in a Jupyter Notebook. So this path on the right side of the production icon is what we’re calling ML observability. We have four pillars that we use when thinking about ML observability.
And usually what ends up happening is that some poor data scientist or MLengineer has to manually troubleshoot this in a Jupyter Notebook. So this path on the right side of the production icon is what we’re calling ML observability. We have four pillars that we use when thinking about ML observability.
Instead of exclusively relying on a singular data development technique, leverage a variety of techniques such as promoting, RAG, and fine-tuning for the most optimal outcome. Focus on improving dataquality and transforming manual data development processes into programmatic operations to scale fine-tuning.
It can also include constraints on the data, such as: Minimum and maximum values for numerical columns Allowed values for categorical columns. Before a model is productionized, the Contract is agreed upon by the stakeholders working on the pipeline, such as the MLEngineers, Data Scientists and Data Owners.
Solution overview As mentioned earlier, the AWS services that you can use for analysis of mobility data are Amazon S3, Amazon Macie, AWS Glue, S3 Object Lambda, Amazon Comprehend, and Amazon SageMaker geospatial capabilities. Example 1 – The following screenshot shows all visits to the Macy’s store.
Instead of exclusively relying on a singular data development technique, leverage a variety of techniques such as promoting, RAG, and fine-tuning for the most optimal outcome. Focus on improving dataquality and transforming manual data development processes into programmatic operations to scale fine-tuning.
Once the best model is identified, it is usually deployed in production to make accurate predictions on real-world data (similar to the one on which the model was trained initially). Ideally, the responsibilities of the MLengineering team should be completed once the model is deployed. But this is only sometimes the case.
Instead of exclusively relying on a singular data development technique, leverage a variety of techniques such as promoting, RAG, and fine-tuning for the most optimal outcome. Focus on improving dataquality and transforming manual data development processes into programmatic operations to scale fine-tuning.
It’s critical for beginners learn this, since it affects everything: workflows, dataquality requirements, etc. Model mindset prioritizes the ML model that you are building. While product mindset focuses on the end data product: the minimum viable product. There are two approaches we see in MLOps. What is the Difference?
Data scrubbing is often used interchangeably but there’s a subtle difference. Cleaning is broader, improving dataquality. This is a more intensive technique within data cleaning, focusing on identifying and correcting errors. Data scrubbing is a powerful tool within this cleaning service.
Among other topics, he highlighted how visual prompts and parameter-efficient models enable rapid iteration for improved dataquality and model performance. He also described a near future where large companies will augment the performance of their finance and tax professionals with large language models, co-pilots, and AI agents.
Among other topics, he highlighted how visual prompts and parameter-efficient models enable rapid iteration for improved dataquality and model performance. He also described a near future where large companies will augment the performance of their finance and tax professionals with large language models, co-pilots, and AI agents.
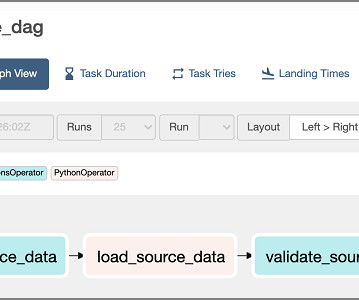
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and MLEngineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
This is a bigger deal with raw or unstructured data that engineers and developers might be using to feed the machine learning program. Data scientists know about the perils of unstructured data – but it’s not always something that MLengineers think about – until it’s too late.
Leveraging Data-Centric AI for Document Intelligence and PDF Extraction Extracting entities from semi-structured documents is often a challenging task, requiring complex and time-consuming manual processes. She starts by discussing the challenges associated with extracting from PDFs and other semi-structured documents.
Leveraging Data-Centric AI for Document Intelligence and PDF Extraction Extracting entities from semi-structured documents is often a challenging task, requiring complex and time-consuming manual processes. She starts by discussing the challenges associated with extracting from PDFs and other semi-structured documents.
Organizations struggle in multiple aspects, especially in modern-day dataengineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. More features mean more data consumed upstream.
Organizations struggle in multiple aspects, especially in modern-day dataengineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. More features mean more data consumed upstream.
Organizations struggle in multiple aspects, especially in modern-day dataengineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. More features mean more data consumed upstream.
For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes dataquality, privacy, and compliance. For an experienced Data Scientist/MLengineer, that shouldn’t come as so much of a problem.
Leveraging Data-Centric AI for Document Intelligence and PDF Extraction Extracting entities from semi-structured documents is often a challenging task, requiring complex and time-consuming manual processes. She starts by discussing the challenges associated with extracting from PDFs and other semi-structured documents.
And even on the operation side of things, is there a separate operations team, and then you have your research or mlengineers doing these pipelines and stuff? How do you ensure dataquality when building NLP products? How would you ensure that your data is high-quality throughout the life cycle of the product?
This is Piotr Niedźwiedź and Aurimas Griciūnas from neptune.ai , and you’re listening to ML Platform Podcast. Stefan is a software engineer, data scientist, and has been doing work as an MLengineer. One of the features that Hamilton has is that it has a really lightweight dataquality runtime check.
Model governance involves overseeing the development, deployment, and maintenance of ML models to help ensure that they meet business objectives and are accurate, fair, and compliant with regulations.
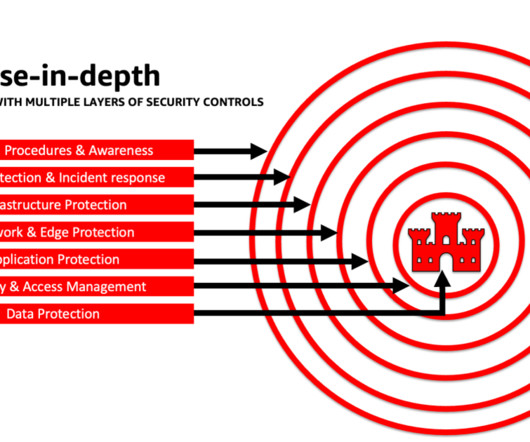
The goal of this post is to empower AI and machine learning (ML) engineers, data scientists, solutions architects, security teams, and other stakeholders to have a common mental model and framework to apply security best practices, allowing AI/ML teams to move fast without trading off security for speed.
One of the most prevalent complaints we hear from MLengineers in the community is how costly and error-prone it is to manually go through the ML workflow of building and deploying models. Building end-to-end machine learning pipelines lets MLengineers build once, rerun, and reuse many times. Data preprocessing.
Getting a workflow ready which takes your data from its raw form to predictions while maintaining responsiveness and flexibility is the real deal. At that point, the Data Scientists or MLEngineers become curious and start looking for such implementations. Synchronous training What is synchronous training architecture?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content