This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Machinelearning has become an essential tool for organizations of all sizes to gain insights and make data-driven decisions. However, the success of ML projects is heavily dependent on the quality of data used to train models. appeared first on Analytics Vidhya.
Data analytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities. Flipping the paradigm: Using AI to enhance dataquality What if we could change the way we think about dataquality?
Introduction In the realm of machinelearning, the veracity of data holds utmost significance in the triumph of models. Inadequate dataquality can give rise to erroneous predictions, unreliable insights, and overall performance.
This article was published as a part of the Data Science Blogathon. Introduction In machinelearning, the data is an essential part of the training of machinelearning algorithms. The amount of data and the dataquality highly affect the results from the machinelearning algorithms.
Introduction Ensuring dataquality is paramount for businesses relying on data-driven decision-making. As data volumes grow and sources diversify, manual quality checks become increasingly impractical and error-prone.
Machinelearning (ML) is a powerful technology that can solve complex problems and deliver customer value. This is why MachineLearning Operations (MLOps) has emerged as a paradigm to offer scalable and measurable values to Artificial Intelligence (AI) driven businesses. They are huge, complex, and data-hungry.
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. DataqualityDataquality is essentially the measure of data integrity.
To operate effectively, multimodal AI requires large amounts of high-qualitydata from multiple modalities, and inconsistent dataquality across modalities can affect the performance of these systems.
Prescriptive AI uses machinelearning and optimization models to evaluate various scenarios, assess outcomes, and find the best path forward. This capability is essential for fast-paced industries, helping businesses make quick, data-driven decisions, often with automation.
Here are four best practices to help future-proof your data strategy: 1. Building a Data Foundation for the Future According to a recent KPMG survey , 67% of business leaders expect AI to fundamentally transform their businesses within the next two years, and 85% feel like dataquality will be the biggest bottleneck to progress.
Modern dataquality practices leverage advanced technologies, automation, and machinelearning to handle diverse data sources, ensure real-time processing, and foster collaboration across stakeholders.
As multi-cloud environments become more complex, observability must adapt to handle diverse data sources and infrastructures. Over the next few years, we anticipate AI and machinelearning playing a key role in advancing observability capabilities, particularly through predictive analytics and automated anomaly detection.
Algorithms, which are the foundation for AI, were first developed in the 1940s, laying the groundwork for machinelearning and data analysis. In the 1990s, data-driven approaches and machinelearning were already commonplace in business.
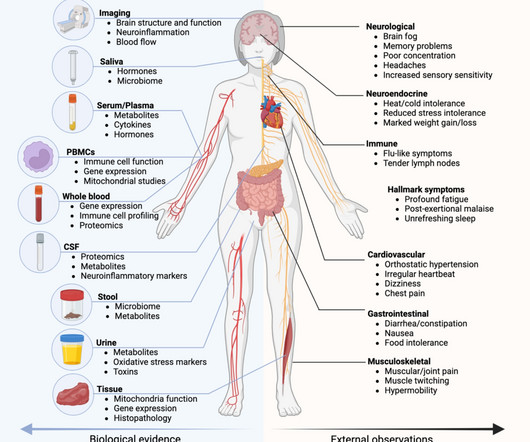
In this review, we explore how machinelearning and multi-omics (genomics, transcriptomics, proteomics, and metabolomics) can transform precision medicine in ME/CFS research and healthcare.
Summary: MachineLearning’s key features include automation, which reduces human involvement, and scalability, which handles massive data. It uses predictive modelling to forecast future events and adaptiveness to improve with new data, plus generalization to analyse fresh data. What is MachineLearning?
Summary: Adaptive MachineLearning is a cutting-edge technology that allows systems to learn and adapt in real-time by processing new data continuously. This capability is particularly important in today’s fast-paced environments, where data changes rapidly and requires systems that can learn and adapt in real time.
Its not a choice between better data or better models. The future of AI demands both, but it starts with the data. Why DataQuality Matters More Than Ever According to one survey, 48% of businesses use big data , but a much lower number manage to use it successfully. Why is this the case?
Machinelearning presents transformative opportunities for businesses and organizations across various industries. From improving customer experiences to optimizing operations and driving innovation, the applications of machinelearning are vast. However, adopting machinelearning solutions is not without challenges.
Machinelearning models can be used to detect suspicious patterns based on a series of datasets that are in constant evolution. Your organization must also make certain other strategic considerations in order to preserve security and dataquality. AI presents a new way of screening for financial crime risk.
With daily advancements in machinelearning , natural language processing , and automation, many of these companies identify as “cutting-edge,” but struggle to stand out. As of 2024, there are approximately 70,000 AI companies worldwide, contributing to a global AI market value of nearly $200 billion.
AI has the opportunity to significantly improve the experience for patients and providers and create systemic change that will truly improve healthcare, but making this a reality will rely on large amounts of high-qualitydata used to train the models. Why is data so critical for AI development in the healthcare industry?
Alix Melchy is the VP of AI at Jumio, where he leads teams of machinelearning engineers across the globe with a focus on computer vision, natural language processing and statistical modeling. Jumio provides AI-powered identity verification, eKYC, and compliance solutions to help businesses protect against fraud and financial crime.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machinelearning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. Workflow B corresponds to model quality drift checks.
In just about any organization, the state of information quality is at the same low level – Olson, DataQualityData is everywhere! As data scientists and machinelearning engineers, we spend the majority of our time working with data. It is important that we master it!
In this post, we’ll show you the datasets you can use to build your machinelearning projects. After you create a free account, you’ll have access to the best machinelearning datasets. Importance and Role of Datasets in MachineLearningData is king.
True dataquality simplification requires transformation of both code and data, because the two are inextricably linked. Code sprawl and data siloing both imply bad habits that should be the exception, rather than the norm.
Presented by BMC Poor dataquality costs organizations an average $12.9 Organizations are beginning to recognize that not only does it have a direct impact on revenue over the long term, but poor dataquality also increases the complexity of data ecosystems, and directly impacts the … million a year.
As climate change continuously threatens our planet and the existence of life on it, integrating machinelearning (ML) and artificial intelligence (AI) into this arena offers promising solutions to predict and mitigate its impacts effectively.
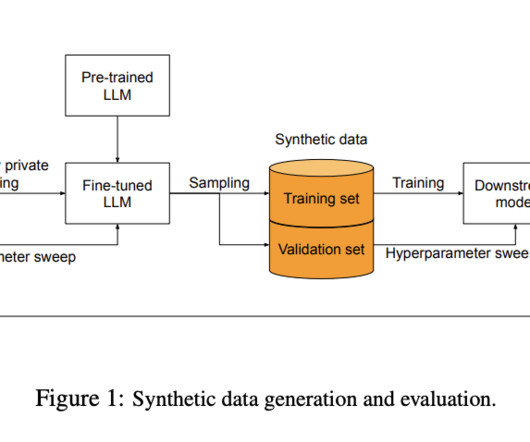
Google AI researchers describe their novel approach to addressing the challenge of generating high-quality synthetic datasets that preserve user privacy, which are essential for training predictive models without compromising sensitive information. Check out the Paper and Blog. Also, don’t forget to follow us on Twitter.
Challenges of Using AI in Healthcare Physicians, doctors, nurses, and other healthcare providers face many challenges integrating AI into their workflows, from displacement of human labor to dataquality issues. Interoperability Problems and DataQuality Issues Data from different sources can often fail to integrate seamlessly.
Data Engineers: We look into Data Engineering, which combines three core practices around Data Management, Software Engineering, and I&O. This focuses …
Machinelearning (ML) models are fundamentally shaped by data, and building inclusive ML systems requires significant considerations around how to design representative datasets.
Source: Author Introduction Machinelearning model monitoring tracks the performance and behavior of a machinelearning model over time. Organizations can ensure that their machine-learning models remain robust and trustworthy over time by implementing effective model monitoring practices.
However, with the emergence of MachineLearning algorithms, the retail industry has seen a revolutionary shift in demand forecasting capabilities. This technology allows computers to learn from historical data, identify patterns, and make data-driven decisions without explicit programming.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machinelearning (ML) solutions without writing code. Analyze data using generative AI. Prepare data for machinelearning.
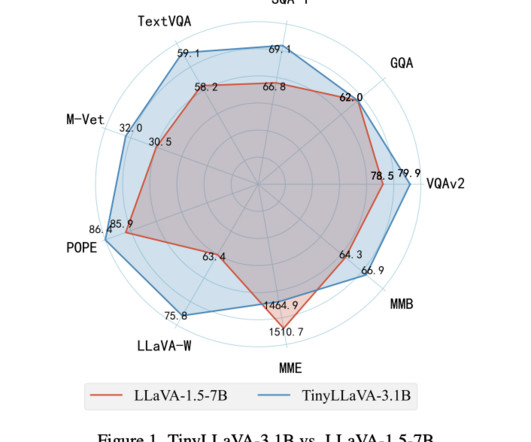
The training data consists of two different datasets, LLaVA-1.5 and ShareGPT4V, used to study the impact of dataquality on LMM performance. It also provides a unified analysis of model selections, training recipes, and data contributions to the performance of small-scale LMMs.
research scientist with over 16 years of professional experience in the fields of speech/audio processing and machinelearning in the context of Automatic Speech Recognition (ASR), with a particular focus and hands-on experience in recent years on deep learning techniques for streaming end-to-end speech recognition.
This post is co-written with Travis Bronson, and Brian L Wilkerson from Duke Energy Machinelearning (ML) is transforming every industry, process, and business, but the path to success is not always straightforward. There are only 0.12% of anomalous images in the entire data set (i.e., anomalies out of 1000 images).
“Managing dynamic dataquality, testing and detecting for bias and inaccuracies, ensuring high standards of data privacy, and ethical use of AI systems all require human oversight,” he said.
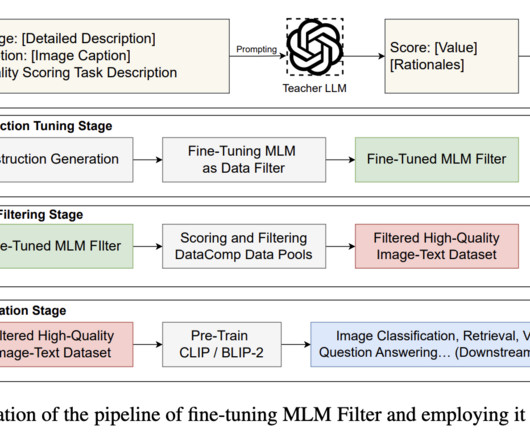
Their solution focuses on filtering image-text data, a novel approach that introduces a nuanced scoring system for dataquality evaluation, offering a more refined assessment than its predecessors. The research introduces a comprehensive scoring system that evaluates the quality of image-text pairs across four distinct metrics.
Beginner’s Guide to ML-001: Introducing the Wonderful World of MachineLearning: An Introduction Everyone is using mobile or web applications which are based on one or other machinelearning algorithms. You might be using machinelearning algorithms from everything you see on OTT or everything you shop online.
In our ever-evolving world, the significance of sequential decision-making (SDM) in machinelearning cannot be overstated. Much like how foundation models in language, such as BERT and GPT, have transformed natural language processing by leveraging vast textual data, pretrained foundation models hold similar promise for SDM.
In the quest to uncover the fundamental particles and forces of nature, one of the critical challenges facing high-energy experiments at the Large Hadron Collider (LHC) is ensuring the quality of the vast amounts of data collected. The new system was deployed in the barrel of the ECAL in 2022 and in the endcaps in 2023.
Yet, deal slippage, inaccurate billing, poor dataquality, manual errors, and unbilled services all undermine revenue growth. At Clari, advanced AI and machinelearning models sit at the core, built specifically for revenue and trained on a decade of real-world data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content