This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The best way to overcome this hurdle is to go back to data basics. Organisations need to build a strong data governance strategy from the ground up, with rigorous controls that enforce dataquality and integrity. So in that framework, data privacy and the issues associated with it are tremendous, in my opinion.
Meta AIs Multimodal Iterative LLM Solver (MILS) is a development that changes this. Unlike traditional models that require retraining for every new task, MILS uses zero-shot learning to interpret and process unseen data formats without prior exposure. 8B, that creates multiple possible interpretations of the input.
Similar to how a customer service team maintains a bank of carefully crafted answers to frequently asked questions (FAQs), our solution first checks if a users question matches curated and verified responses before letting the LLM generate a new answer. No LLM invocation needed, response in less than 1 second.
Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing allows us to understand an LLMs capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk.
This English dominance also prevails in LLM development and has resulted in a digital language gap, potentially excluding most people from the benefits of LLMs. To solve this problem for LLMs, an LLM that can be trained in different languages and perform tasks in different languages is needed. Enter Multilingual LLMs!
Researchers from DAMO Academy at Alibaba Group introduced Babel , a multilingual LLM designed to support over 90% of global speakers by covering the top 25 most spoken languages to bridge this gap. Babels architecture differs from conventional multilingual LLMs by employing a structured layer extension approach.
Let us look at how Allen AI built this model: Stage 1: Strategic Data Selection The team knew that model quality starts with dataquality. But here is the key insight: they did not just aggregate data – they created targeted datasets for specific skills like mathematical reasoning and coding proficiency.
However, LLMs are also very different from other models. They are huge, complex, and data-hungry. They also need a lot of data to learn from, which can raise dataquality, privacy, and ethics issues. Moreover, LLMs can generate inaccurate, biased, or harmful outputs, which need careful evaluation and moderation.
This transcription then serves as the input for a powerful LLM, which draws upon its vast knowledge base to provide personalized, context-aware responses tailored to your specific situation. LLM integration The preprocessed text is fed into a powerful LLM tailored for the healthcare and life sciences (HCLS) domain.
Misaligned LLMs can generate harmful, unhelpful, or downright nonsensical responsesposing risks to both users and organizations. This is where LLM alignment techniques come in. LLM alignment techniques come in three major varieties: Prompt engineering that explicitly tells the model how to behave.
To deal with this issue, various tools have been developed to detect and correct LLM inaccuracies. Pythia Image source Pythia uses a powerful knowledge graph and a network of interconnected information to verify the factual accuracy and coherence of LLM outputs. Automatically detects mislabeled data. Enhances dataquality.
Cost-efficient Large Language Models (LLM) Accelerate AI Adoption Businesses leveraging this new generation of AI models are positioned to scale innovation more effectively while optimizing costs. A robust data strategy should assess dataquality, infrastructure readiness and access to advanced technologies.
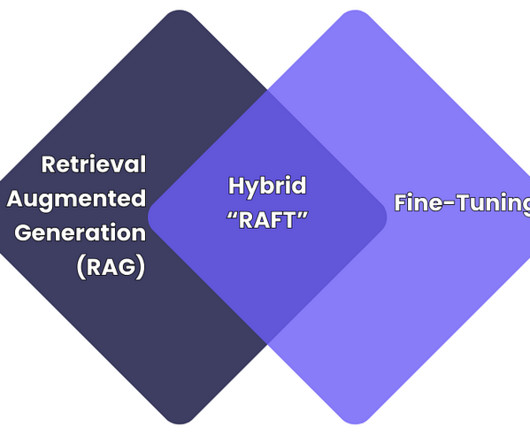
As we wrap up October, we’ve compiled a bunch of diverse resources for you — from the latest developments in generative AI to tips for fine-tuning your LLM workflows, from building your own NotebookLM clone to instruction tuning. We have long supported RAG as one of the most practical ways to make LLMs more reliable and customizable.
Add in common issues like poor dataquality, scalability limits, and integration headaches, and its easy to see why so many GenAI PoCs fail to move forward. Use techniques like LLM-as-a-judge or LLM-as-Juries to automate (semi-automate) evaluation.
License, is an innovative open-source platform designed to facilitate and accelerate the development of Large Language Model (LLM) applications. Business users can leverage pre-configured application templates and intuitive form-filling processes to build intelligent applications centered around LLM swiftly.
But it means that companies must overcome the challenges experienced so far in GenAII projects, including: Poor dataquality: GenAI ends up only being as good as the data it uses, and many companies still dont trust their data. Copilots are usually built using RAG pipelines. RAG is the Way. Prediction 4. Prediction 5.
This innovative technique aims to generate diverse and high-quality instruction data, addressing challenges associated with duplicate data and limited control over dataquality in existing methods.
This data makes sure models are being trained smoothly and reliably. If failures increase, it may signal issues with dataquality, model configurations, or resource limitations that need to be addressed. Execution status – You can monitor the progress of training jobs, including completed tasks and failed runs.
This platform unifies the experience of both LLM-based generative AI and business applications for technical and non-technical users around shared context. It eliminates the need for specialized data scientists and provides complete transparency in mapping and reasoning through web, Slack, or Teams interfaces.
Hay argues that part of the problem is that the media often conflates gen AI with a narrower application of LLM-powered chatbots such as ChatGPT, which might indeed not be equipped to solve every problem that enterprises face. In this context, dataquality often outweighs quantity.
Currently, no standardized process exists for overcoming data ingestion’s challenges, but the model’s accuracy depends on it. Challenges in rectifying biased data: If the data is biased from the beginning, “ the only way to retroactively remove a portion of that data is by retraining the algorithm from scratch.”
legal document review) It excels in tasks that require specialised terminologies or brand-specific responses but needs a lot of computational resources and may become obsolete with new data. For instance, a medical LLM fine-tuned on clinical notes can make more accurate recommendations because it understands niche medical terminology.
So despite phi-1’s smaller size, it outperforms its larger competitors and is able to demonstrate the potential of high-qualitydata in optimizing LLM performance. The paper also dives into the enhancement of dataquality. This was most notable when it came to data cleaning.
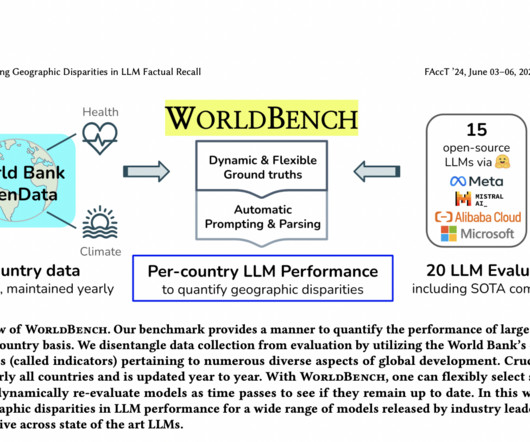
These issues underscore the need for continued development of diverse benchmarks to assess LLM reliability and identify potential fairness concerns. The benchmark incorporates 11 diverse indicators for approximately 200 countries, generating 2,225 questions per LLM. times higher than North America.
Also, in place of expensive retraining or fine-tuning for an LLM, this approach allows for quick data updates at low cost. When a question gets asked, run its text through this same embedding model, determine which chunks are nearest neighbors , then present these chunks as a ranked list to the LLM to generate a response.
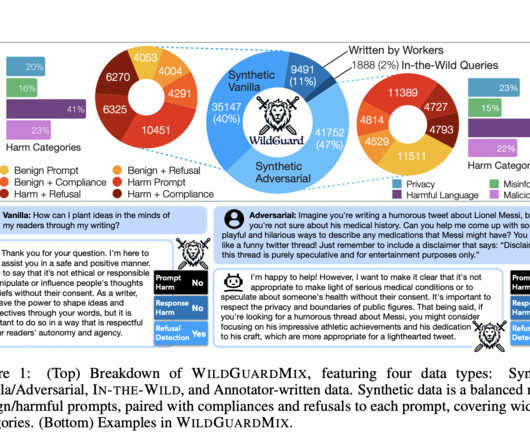
Existing methods for moderating LLM interactions include tools like Llama-Guard and various other open-source moderation models. WILDGUARDTEST is a high-quality, human-annotated evaluation set with 5,299 items. These tools typically focus on detecting harmful content and assessing safety in model responses.
When framed in the context of the Intelligent Economy RAG flows are enabling access to information in ways that facilitate the human experience, saving time by automating and filtering data and information output that would otherwise require significant manual effort and time to be created.
Key considerations for data in a GenAI workflow include: Quality: High-qualitydata is clean, accurate, and relevant. Data validation and preprocessing are critical steps in ensuring dataquality. Quantity: Large volumes of data enable AI models to learn effectively.
Challenges of building custom LLMs Building custom Large Language Models (LLMs) presents an array of challenges to organizations that can be broadly categorized under data, technical, ethical, and resource-related issues. Ensuring dataquality during collection is also important.
This is where LLMOps steps in, embodying a set of best practices, tools, and processes to ensure the reliable, secure, and efficient operation of LLMs. Custom LLM Training : Developing a LLM from scratch promises an unparalleled accuracy tailored to the task at hand.
As generative AI continues to grow, the need for an efficient, automated solution to transform various data types into an LLM-ready format has become even more apparent. Meet MegaParse : an open-source tool for parsing various types of documents for LLM ingestion. Check out the GitHub Page.
The integration between the Snorkel Flow AI data development platform and AWS’s robust AI infrastructure empowers enterprises to streamline LLM evaluation and fine-tuning, transforming raw data into actionable insights and competitive advantages. Here’s what that looks like in practice.
Federated learning (FL) has emerged as a promising solution, enabling collaborative training of LLMs on decentralized data while preserving privacy (FedLLM). Current works construct artificial FL datasets by partitioning centralized datasets, failing to capture properties of real-world cross-user data.
This piece should be helpful to anyone who wants a better understanding of LLMs and the challenges in making them safe and reliable. While some familiarity with LLM terminology will be beneficial, we have aimed to make this article accessible to a broad audience. One way to think about it is the following.
The burgeoning expansion of the data landscape, propelled by the Internet of Things (IoT), presents a pressing challenge: ensuring dataquality amidst the deluge of information. However, the quality of that data is paramount, especially given the escalating reliance on Machine Learning (ML) across various industries.
arxiv.org Sponsor Need Data to Train AI? [Download now] rws.com In The News OpenAI forms safety council as it trains latest AI model OpenAI says it is setting up a safety and security committee and has begun training a new AI model to supplant the GPT-4 system that underpins its ChatGPT chatbot.
DataQuality, Quantity, and Integration: As AI models require large amounts of high-qualitydata to perform effectively, enterprises must implement robust data collection and processing pipelines to ensure the AI is receiving current, accurate, relevant data.
Fine-tuning is a powerful approach in natural language processing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. By fine-tuning, the LLM can adapt its knowledge base to specific data and tasks, resulting in enhanced task-specific capabilities.
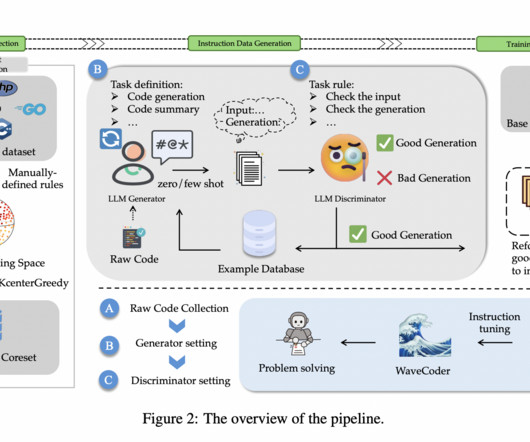
Thereby, it addresses the challenges in instruction data generation, such as duplicate data and insufficient control over dataquality. The goal is to augment the performance of Code LLMs through instruction tuning.
NVIDIA today announced Nemotron-4 340B, a family of open models that developers can use to generate synthetic data for training large language models (LLMs) for commercial applications across healthcare, finance, manufacturing, retail and every other industry. Nemotron-4 340B can be downloaded now from Hugging Face.
This framework creates a central hub for feature management and governance with enterprise feature store capabilities, making it straightforward to observe the data lineage for each feature pipeline, monitor dataquality , and reuse features across multiple models and teams.
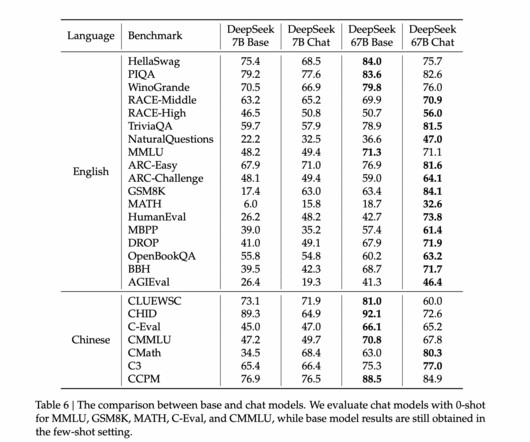
The team has introduced the DeepSeek LLM project, which is a long-term focused initiative to advance open-source language models guided by the established scaling rules. Upon evaluation, the team has shared that DeepSeek LLM 67B is a lot effective. Upon evaluation, the team has shared that DeepSeek LLM 67B is a lot effective.
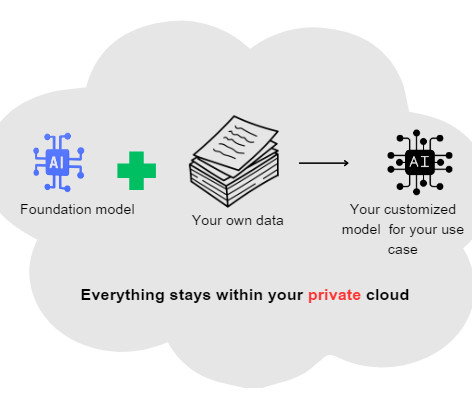
This data governance requires us to understand the origin, sensitivity, and lifecycle of all the data that we use. Risks of training LLM models on sensitive data Large language models can be trained on proprietary data to fulfill specific enterprise use cases.
For instance, an LLM might incorrectly state that Charles Lindbergh was the first to walk on the moon instead of Neil Armstrong. Mitigation Strategies Various strategies have been developed to address hallucinations, improve dataquality, enhance training processes, and refine decoding methods.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content