This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, the success of ML projects is heavily dependent on the quality of data used to train models. Poor dataquality can lead to inaccurate predictions and poor model performance. Understanding the importance of data […] The post What is DataQuality in Machine Learning?
Learning data engineering ensures proficiency in designing robust data pipelines, optimizing data storage, and ensuring dataquality. This skill is essential for efficiently managing and extracting value from large volumes of data, enabling businesses to stay competitive and innovative in their industries.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. What is ETL? ETL stands for Extract, Transform, Load.
It offers both open-source and enterprise/paid versions and facilitates big data management. Key Features: Seamless integration with cloud and on-premise environments, extensive dataquality, and governance tools. Pros: Scalable, strong data governance features, support for big data.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
It offers both open-source and enterprise/paid versions and facilitates big data management. Key Features: Seamless integration with cloud and on-premise environments, extensive dataquality, and governance tools. Pros: Scalable, strong data governance features, support for big data. Visit Airbyte → 9.
To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark.
Summary: Data engineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024.
This setup uses the AWS SDK for Python (Boto3) to interact with AWS services. Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines.
You can use Amazon SageMaker geospatial capabilities to overlay mobility data on a base map and provide layered visualization to make collaboration easier. The GPU-powered interactive visualizer and Python notebooks provide a seamless way to explore millions of data points in a single window and share insights and results.
Looking for an effective and handy Python code repository in the form of Importing Data in Python Cheat Sheet? Your journey ends here where you will learn the essential handy tips quickly and efficiently with proper explanations which will make any type of data importing journey into the Python platform super easy.
You can use this notebook job step to easily run notebooks as jobs with just a few lines of code using the Amazon SageMaker Python SDK. Data scientists currently use SageMaker Studio to interactively develop their Jupyter notebooks and then use SageMaker notebook jobs to run these notebooks as scheduled jobs.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Warehousing: Amazon Redshift, Google BigQuery, etc.
It enables reporting and Data Analysis and provides a historical data record that can be used for decision-making. Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. ETL is vital for ensuring dataquality and integrity.
The project I did to land my business intelligence internship — CAR BRAND SEARCH ETL PROCESS WITH PYTHON, POSTGRESQL & POWER BI 1. Section 2: Explanation of the ETL diagram for the project. Section 3: The technical section for the project where Python and pgAdmin4 will be used. Figure 6: Project’s Dashboard 3.
For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes dataquality, privacy, and compliance. If you aren’t aware already, let’s introduce the concept of ETL. Redshift, S3, and so on.
Set specific, measurable targets Data science goals to “increase sales” lack the clarity needed to evaluate success and secure ongoing funding. Audit existing data assets Inventory internal datasets, ETL capabilities, past analytical initiatives, and available skill sets.
Scalability : A data pipeline is designed to handle large volumes of data, making it possible to process and analyze data in real-time, even as the data grows. Dataquality : A data pipeline can help improve the quality of data by automating the process of cleaning and transforming the data.
Business Requirements Analysis and Translation Working with business users to understand their data needs and translate them into technical specifications. DataQuality Assurance Implementing dataquality checks and processes to ensure data accuracy and reliability. What Are Key Skills for A BI Analyst?
Tools such as Python’s Pandas library, Apache Spark, or specialised data cleaning software streamline these processes, ensuring data integrity before further transformation. Step 3: Data Transformation Data transformation focuses on converting cleaned data into a format suitable for analysis and storage.
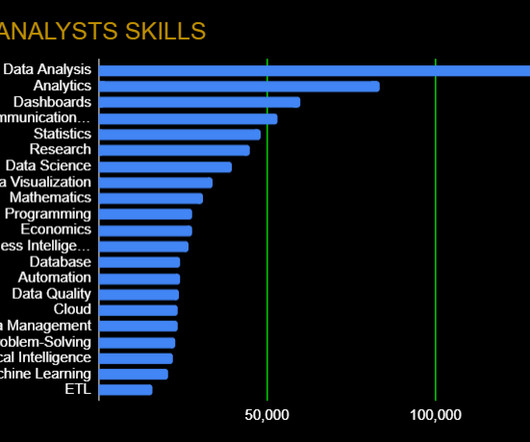
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: DataQuality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
Data Warehousing and ETL Processes What is a data warehouse, and why is it important? A data warehouse is a centralised repository that consolidates data from various sources for reporting and analysis. It is essential to provide a unified data view and enable business intelligence and analytics.
Schema-Free Learning: why we do not need schemas anymore in the data and learning capabilities to make the data “clean” This does not mean that dataquality is not important, data cleaning will still be very crucial, but data in a schema/table is no longer requirement or pre-requisite for any learning and analytics purposes.
A 2019 survey by McKinsey on global data transformation revealed that 30 percent of total time spent by enterprise IT teams was spent on non-value-added tasks related to poor dataquality and availability. It truly is an all-in-one data lake solution. It’s not a widely known programming language like Java, Python, or SQL.
Apache Spark A fast, in-memory data processing engine that provides support for various programming languages, including Python, Java, and Scala. Data Integration Tools Technologies such as Apache NiFi and Talend help in the seamless integration of data from various sources into a unified system for analysis.
At a high level, we are trying to make machine learning initiatives more human capital efficient by enabling teams to more easily get to production and maintain their model pipelines, ETLs, or workflows. You could almost think of Hamilton as DBT for Python functions. It gives a very opinionary way of writing Python. Stefan: Yep!
Airflow for workflow orchestration Airflow schedules and manages complex workflows, defining tasks and dependencies in Python code. An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content