This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Understanding data governance in healthcare The need for a strong data governance framework is undeniable in any highly-regulated industry, but the healthcare industry is unique because it collects and processes massive amounts of personal data to make informed decisions about patient care. The consequence?
This trust depends on an understanding of the data that inform risk models: where does it come from, where is it being used, and what are the ripple effects of a change? Banks and their employees place trust in their risk models to help ensure the bank maintains liquidity even in the worst of times.
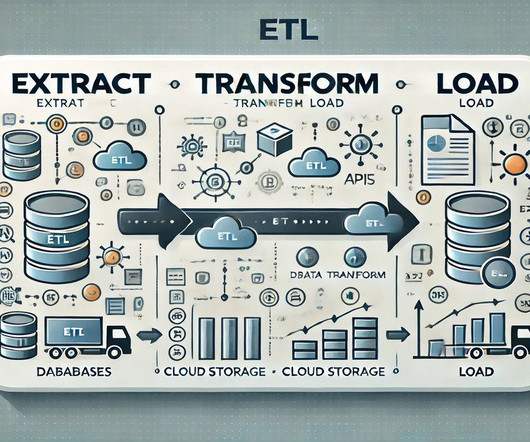
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. What is ETL?
Compiling data from these disparate systems into one unified location. This is where data integration comes in! Data integration is the process of combining information from multiple sources to create a consolidated dataset. Data integration tools consolidate this data, breaking down silos. The challenge?
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. After ingesting the data, you create an agent with specific instructions: agent_instruction = """You are the Amazon Bedrock Agent.
Summary: Selecting the right ETL platform is vital for efficient data integration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes.
Compiling data from these disparate systems into one unified location. This is where data integration comes in! Data integration is the process of combining information from multiple sources to create a consolidated dataset. Data integration tools consolidate this data, breaking down silos. The challenge?
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
Beyond Scale: DataQuality for AI Infrastructure The trajectory of AI over the past decade has been driven largely by the scale of data available for training and the ability to process it with increasingly powerful compute & experimental models. Author(s): Richie Bachala Originally published on Towards AI.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024.
In addition, organizations that rely on data must prioritize dataquality review. Data profiling is a crucial tool. For evaluating dataquality. Data profiling gives your company the tools to spot patterns, anticipate consumer actions, and create a solid data governance plan.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. The following elements serve as a backbone for a functional data warehouse.
Understanding Data Engineering Data engineering is collecting, storing, and organising data so businesses can use it effectively. It involves building systems that move and transform raw data into a usable format. Without data engineering , companies would struggle to analyse information and make informed decisions.
Your data strategy should incorporate databases designed with open and integrated components, allowing for seamless unification and access to data for advanced analytics and AI applications within a data platform. This enables your organization to extract valuable insights and drive informed decision-making.
Almost all organisations nowadays make informed decisions by leveraging data and analysing the market effectively. However, analysis of data may involve partiality or incorrect insights in case the dataquality is not adequate. What is Data Profiling in ETL? Z-score, interquartile range).
To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings. To utilize this data ethically, several steps need to be followed. It starts with the collection of data itself.
What is Data Mining? In today’s data-driven world, organizations collect vast amounts of data from various sources. Information like customer interactions, and sales transactions plays a pivotal role in decision-making. But, this data is often stored in disparate systems and formats. Wrapping It Up !!!
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Schema Enforcement: Data warehouses use a “schema-on-write” approach. Data must be transformed and structured before loading, ensuring data consistency and quality.
It involves developing data pipelines that efficiently transport data from various sources to storage solutions and analytical tools. The goal is to ensure that data is available, reliable, and accessible for analysis, ultimately driving insights and informed decision-making within organisations.
Summary: Understanding Business Intelligence Architecture is essential for organizations seeking to harness data effectively. This framework includes components like data sources, integration, storage, analysis, visualization, and information delivery.
Summary: Data ingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances dataquality, enables real-time insights, and supports informed decision-making. It supports both batch and real-time processing.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. AWS Glue AWS Glue is a fully managed ETL service provided by Amazon Web Services.
It covers best practices for ensuring scalability, reliability, and performance while addressing common challenges, enabling businesses to transform raw data into valuable, actionable insights for informed decision-making. As stated above, data pipelines represent the backbone of modern data architecture.
These technologies include the following: Data governance and management — It is crucial to have a solid data management system and governance practices to ensure data accuracy, consistency, and security. It is also important to establish dataquality standards and strict access controls.
This flexibility allows organizations to store vast amounts of raw data without the need for extensive preprocessing, providing a comprehensive view of information. Centralized Data Repository Data Lakes serve as a centralized repository, consolidating data from different sources within an organization.
Eight prominent concepts stand out: Customer Data Platforms (CDPs), Master Data Management (MDM), Data Lakes, Data Warehouses, Data Lakehouses, Data Marts, Feature Stores, and Enterprise Resource Planning (ERP). Pros: Data Consistency: Ensures consistent and accurate data across the organization.
There are various architectural design patterns in data engineering that are used to solve different data-related problems. This article discusses five commonly used architectural design patterns in data engineering and their use cases. Finally, the transformed data is loaded into the target system.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Warehousing: Amazon Redshift, Google BigQuery, etc.
For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes dataquality, privacy, and compliance. If you aren’t aware already, let’s introduce the concept of ETL. Redshift, S3, and so on.
This is what data processing pipelines do for you. Automating myriad steps associated with pipeline data processing, helps you convert the data from its raw shape and format to a meaningful set of information that is used to drive business decisions. This ensures that the data is accurate, consistent, and reliable.
This role is vital for data-driven organizations seeking competitive advantages. Introduction We are living in an era defined by data. From customer interactions to market trends, every aspect of business generates a wealth of information. Essentially, BI bridges the gap between raw data and actionable knowledge.
Additionally, it addresses common challenges and offers practical solutions to ensure that fact tables are structured for optimal dataquality and analytical performance. Introduction In today’s data-driven landscape, organisations are increasingly reliant on Data Analytics to inform decision-making and drive business strategies.
The project I did to land my business intelligence internship — CAR BRAND SEARCH ETL PROCESS WITH PYTHON, POSTGRESQL & POWER BI 1. Section 2: Explanation of the ETL diagram for the project. Section 4: Reporting data for the project insights. ETL ARCHITECTURE DIAGRAM ETL stands for Extract, Transform, Load.
Customer 360 initiatives are designed to bring together relevant information about individual consumers from different touch points, including but not limited to sales, marketing, customer service, and social media platforms. How Data Engineering Enhances Customer 360 Initiatives 1.
Improved Data Navigation Hierarchies provide a clear structure for users to navigate through data. This allows for intuitive querying and reporting, making it easier for users to find the information they need. Enhanced Data Analysis By allowing users to drill down into data, hierarchies enable more detailed analysis.
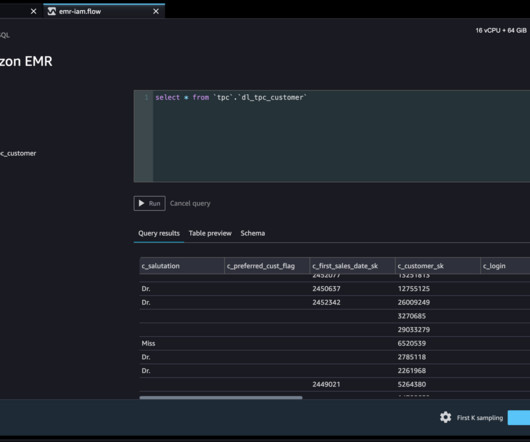
Solution overview We demonstrate this solution with an end-to-end use case using a sample dataset, the TPC data model. This data represents transaction data for products and includes information such as customer demographics, inventory, web sales, and promotions. Tina has access to information about sales.
This week, I will cover why I think data janitor work is dying and companies that are built in on top of data janitor work could be ripe for disruption through LLMs and what to do about it. A data janitor is a person who works to take big data and condense it into useful amounts of information. No, not really.
The blog also presents popular data analytics courses, emphasizing their curriculum, learning methods, certification opportunities, and benefits to help aspiring Data Analysts choose the proper training for their career advancement. Data Warehousing and ETL Processes What is a data warehouse, and why is it important?
Volume It refers to the sheer amount of data generated daily, which can range from terabytes to petabytes. Organisations must develop strategies to store and manage this vast amount of information effectively. Velocity It indicates the speed at which data is generated and processed, necessitating real-time analytics capabilities.
Importing Table Data Flat Files Table data flat files typically refer to structured data files where information is organized in rows and columns, resembling a table or spreadsheet.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content