This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It automatically identifies vulnerable individual data points and introduces “noise” to obscure their specific information. Although adding noise slightly reduces output accuracy (this is the “cost” of differential privacy), it does not compromise utility or dataquality compared to traditional data masking techniques.
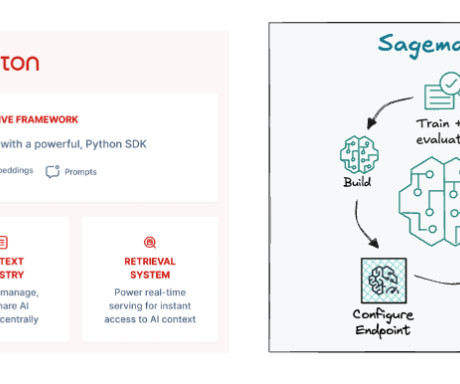
This framework creates a central hub for feature management and governance with enterprise feature store capabilities, making it straightforward to observe the data lineage for each feature pipeline, monitor dataquality , and reuse features across multiple models and teams. You can also find Tecton at AWS re:Invent.
Bisheng also addresses the issue of uneven dataquality within enterprises by providing comprehensive unstructured data governance capabilities, which have been honed over years of experience. These capabilities are accessible in the demo environment and are offered without limitations.
The following sections further explain the main components of the solution: ETL pipelines to transform the log data, agentic RAG implementation, and the chat application. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
Automated data preparation and cleansing : AI-powered data preparation tools will automate data cleaning, transformation and normalization, reducing the time and effort required for manual data preparation and improving dataquality.
It includes a built-in schema registry to validate event data from applications as expected, improving dataquality and reducing errors. Flexible and customizable Kafka configurations can be automated by using a simple user interface.
They classify their analyses into four categories: Data statistics (e.g., Dataquality (e.g., WIMBD provides practical insights for curating higher-quality corpora, as well as retroactive documentation and anchoring of model behaviour to their training data. number of tokens and domain distribution).
This is the first one, where we look at some functions for dataquality checks, which are the initial steps I take in EDA. We will use this table to demo and test our custom functions. Let’s get started. 🤠 🔗 All code and config are available on GitHub. The three functions below are created for this purpose. .")
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
Data engineering is crucial in today’s digital landscape as organizations increasingly rely on data-driven insights for decision-making. Learning data engineering ensures proficiency in designing robust data pipelines, optimizing data storage, and ensuring dataquality.
Building a demo is one thing; scaling it to production is an entirely different beast. New Standard of Dataquality Deepseek has made significant strides in understanding the role of training dataquality in AI model development. Everything changed when Deepseek burst onto the scene a month ago.
” – James Tu, Research Scientist at Waabi Play with this project live For more: Dive into documentation Get in touch if you’d like to go through a custom demo with your team Comet ML Comet ML is a cloud-based experiment tracking and optimization platform. Data monitoring tools help monitor the quality of the data.
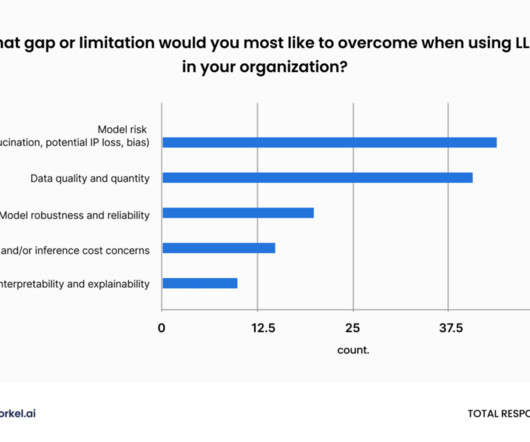
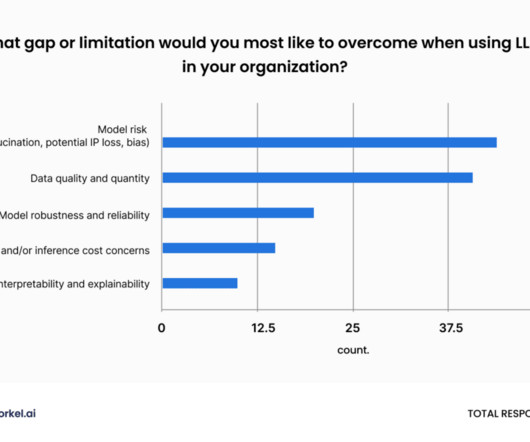
Some of the issues make perfect sense as they relate to dataquality, with common issues being bad/unclean data and data bias. What are the biggest challenges in machine learning? select all that apply) Related to the previous question, these are a few issues faced in machine learning.
Add a new Amazon DocumentDB connection by choosing Import data , then choose Tabular for Dataset type. On the Import data page, for Data Source , choose DocumentDB and Add Connection. Enter a connection name such as demo and choose your desired Amazon DocumentDB cluster. Enter a user name, password, and database name.
We couldn’t be more excited to announce our first group of partners for ODSC East 2023’s AI Expo and Demo Hall. These organizations are shaping the future of the AI and data science industries with their innovative products and services. Check them out below.
This allows customers to further pre-train selected models using their own proprietary data to tailor model responses to their business context. The quality of the custom model depends on multiple factors including the training dataquality and hyperparameters used to customize the model. Virginia) AWS Region (us-east-1).
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Custom Spark commands can also expand the over 300 built-in data transformations. Other analyses are also available to help you visualize and understand your data.
At the AI Expo and Demo Hall as part of ODSC West next week, you’ll have the opportunity to meet one-on-one with representatives from industry-leading organizations like Plot.ly, Google, Snowflake, Microsoft, and plenty more. Delphina Demo: AI-powered Data Scientist Jeremy Hermann | Co-founder at Delphina | Delphina.Ai
See the following code: # Configure the DataQuality Baseline Job # Configure the transient compute environment check_job_config = CheckJobConfig( role=role_arn, instance_count=1, instance_type="ml.c5.xlarge", These are key files calculated from raw data used as a baseline.
As Yoav Shoham, co-founder of AI21 Labs, put it at our Future of Data-Centric AI event in June : “If you’re brilliant 90% of the time and nonsensical or just wrong 10% of the time, that’s a non-starter. While companies have—so far—done very little model distillation, it seems that data scientists and data science leaders see its potential.
Few nonusers (2%) report that lack of data or dataquality is an issue, and only 1.3% AI users are definitely facing these problems: 7% report that dataquality has hindered further adoption, and 4% cite the difficulty of training a model on their data.
As Yoav Shoham, co-founder of AI21 Labs, put it at our Future of Data-Centric AI event in June : “If you’re brilliant 90% of the time and nonsensical or just wrong 10% of the time, that’s a non-starter. While companies have—so far—done very little model distillation, it seems that data scientists and data science leaders see its potential.
At the AI Expo and Demo Hall as part of ODSC West in a few weeks, you’ll have the opportunity to meet one-on-one with representatives from industry-leading organizations like Microsoft Azure, Hewlett Packard, Iguazio, neo4j, Tangent Works, Qwak, Cloudera, and others.
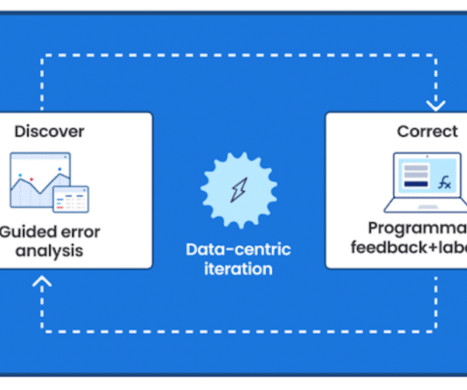
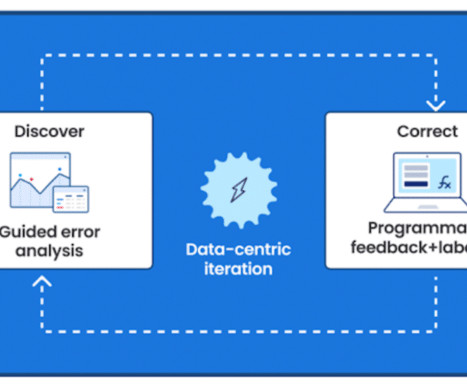
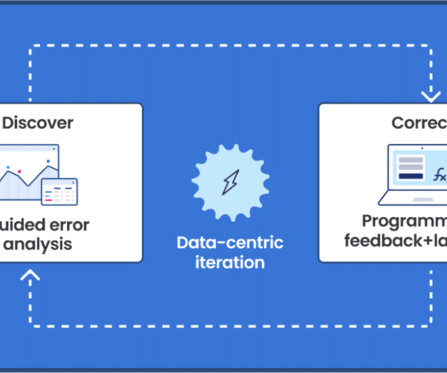
As users integrate more sources of knowledge, the platform enables them to rapidly improve training dataquality and model performance using integrated error analysis tools. Learn more See what Snorkel can do to accelerate your data science and machine learning teams. Book a demo today.
As users integrate more sources of knowledge, the platform enables them to rapidly improve training dataquality and model performance using integrated error analysis tools. Learn more See what Snorkel can do to accelerate your data science and machine learning teams. Book a demo today.
Bitter Lessons Learned While Building Production-quality RAG Systems for Professional Users of Academic Data Jeremy Miller | Product Manager, Academic AI Platform | Clarivate The gap between a RAG Demo and a Production-Quality RAG System remains stubbornly difficult to cross.
Instead of exclusively relying on a singular data development technique, leverage a variety of techniques such as promoting, RAG, and fine-tuning for the most optimal outcome. Focus on improving dataquality and transforming manual data development processes into programmatic operations to scale fine-tuning.
Snorkel’s data-centric approach and user-friendly platform can vastly simplify the training and deployment of credit-scoring models. Snorkel makes it easy to improve training dataquality, build custom AI apps, and distill their predictive power into production-ready mini-models. Book a demo today.
Users are able to rapidly improve training dataquality and model performance using integrated error analysis and model-guided feedback to develop highly accurate and adaptable AI applications. If this sounds interesting, please reach out to request a demo with a member of our team.
Users are able to rapidly improve training dataquality and model performance using integrated error analysis and model-guided feedback to develop highly accurate and adaptable AI applications. If this sounds interesting, please reach out to request a demo with a member of our team.
In particular, you’ll explore the criticality of dataquality and availability, making data accessible through APIs, and techniques for making data GenAI-ready.
If your dataset is not in time order (time consistency is required for accurate Time Series projects), DataRobot can fix those gaps using the DataRobot Data Prep tool , a no-code tool that will get your data ready for Time Series forecasting. Prepare your data for Time Series Forecasting.
First, even though both are intended to provide instruction after generalization, they discover that dataquality is considerably more essential than dataset size, with a 9k sample dataset (OASST1) outperforming a 450k sample dataset (FLAN v2, subsampled) on chatbot performance. Check out the Paper , Code , and Colab.
Data science and machine learning teams use Snorkel Flow’s programmatic labeling to intelligently capture knowledge from various sources—such as previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and even the latest foundation models —and then scale this knowledge to label large quantities of data.
Data science and machine learning teams use Snorkel Flow’s programmatic labeling to intelligently capture knowledge from various sources—such as previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and even the latest foundation models —and then scale this knowledge to label large quantities of data.
Data science and machine learning teams use Snorkel Flow’s programmatic labeling to intelligently capture knowledge from various sources such as previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and even the latest foundation models, then scale this knowledge to label large quantities of data.
Data science and machine learning teams use Snorkel Flow’s programmatic labeling to intelligently capture knowledge from various sources such as previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and even the latest foundation models, then scale this knowledge to label large quantities of data.
Representation models encode meaningful features from raw data for use in classification, clustering, or information retrieval tasks. Trung walked the audience through techniques and best practices for fine-tuning representation models, emphasizing the importance of dataquality and augmentation. Book a demo today.
Click here to know more about how one can unleash the power of AI and ML for scaling operations and dataquality. Back Testing Strategies: Use past data to evaluate and refine your AI-driven trading strategy. Start with a Demo: To get experience without risking real money, start with a demo account on AI platforms.
Instead of exclusively relying on a singular data development technique, leverage a variety of techniques such as promoting, RAG, and fine-tuning for the most optimal outcome. Focus on improving dataquality and transforming manual data development processes into programmatic operations to scale fine-tuning.
Snorkel’s data-centric approach and user-friendly platform can vastly simplify the training and deployment of credit-scoring models. Snorkel makes it easy to improve training dataquality, build custom AI apps, and distill their predictive power into production-ready mini-models. Book a demo today.
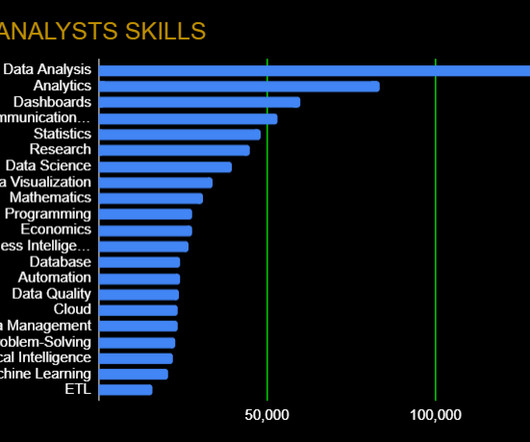
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: DataQuality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Dataquality is essential for the success of any AI project but banks are often limited in their ability to find or label sufficient data. Book a demo today. See what Snorkel option is right for you.
To learn more about enterprise-grade AI, book a demo with our team of experts to discuss Viso Suite. Verifying and validating annotations to maintain high dataquality and reliability. Good understanding of spatial data, 2D and 3D geometry, and coordinate systems. To learn more, book a demo with our team of experts.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content