This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Furthermore, evaluation processes are important not only for LLMs, but are becoming essential for assessing prompt template quality, input dataquality, and ultimately, the entire application stack. ModelRunner definition For BedrockModelRunner , we need to find the model content_template.
However, there are many clear benefits of modernizing our ML platform and moving to Amazon SageMaker Studio and Amazon SageMaker Pipelines. Monitoring – Continuous surveillance completes checks for drifts related to dataquality, model quality, and feature attribution. Workflow B corresponds to model quality drift checks.
Organizations struggle in multiple aspects, especially in modern-day dataengineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. More features mean more data consumed upstream. That is definitely a problem.
Organizations struggle in multiple aspects, especially in modern-day dataengineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. More features mean more data consumed upstream. That is definitely a problem.
Organizations struggle in multiple aspects, especially in modern-day dataengineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. More features mean more data consumed upstream. That is definitely a problem.
Leveraging Data-Centric AI for Document Intelligence and PDF Extraction Extracting entities from semi-structured documents is often a challenging task, requiring complex and time-consuming manual processes. She starts by discussing the challenges associated with extracting from PDFs and other semi-structured documents.
This is Piotr Niedźwiedź and Aurimas Griciūnas from neptune.ai , and you’re listening to ML Platform Podcast. Stefan is a software engineer, data scientist, and has been doing work as an MLengineer. To a junior data scientist, it doesn’t matter if you’re using Airflow, Prefect , Dexter.
Leveraging Data-Centric AI for Document Intelligence and PDF Extraction Extracting entities from semi-structured documents is often a challenging task, requiring complex and time-consuming manual processes. She starts by discussing the challenges associated with extracting from PDFs and other semi-structured documents.
Leveraging Data-Centric AI for Document Intelligence and PDF Extraction Extracting entities from semi-structured documents is often a challenging task, requiring complex and time-consuming manual processes. She starts by discussing the challenges associated with extracting from PDFs and other semi-structured documents.
For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes dataquality, privacy, and compliance. For an experienced Data Scientist/MLengineer, that shouldn’t come as so much of a problem.
You need to have a structured definition around what you’re trying to do so your data annotators can label information for you. In our early days, we definitely landed on the notion that there are really two critical pieces to all meeting notes. How do you ensure dataquality when building NLP products?
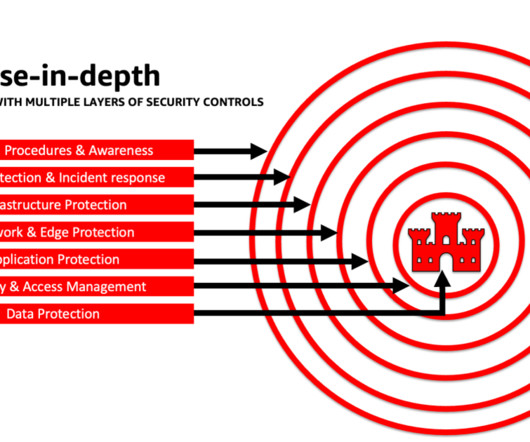
The goal of this post is to empower AI and machine learning (ML) engineers, data scientists, solutions architects, security teams, and other stakeholders to have a common mental model and framework to apply security best practices, allowing AI/ML teams to move fast without trading off security for speed.
Getting a workflow ready which takes your data from its raw form to predictions while maintaining responsiveness and flexibility is the real deal. At that point, the Data Scientists or MLEngineers become curious and start looking for such implementations. Synchronous training What is synchronous training architecture?
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and MLengineers to build and deploy models at scale.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content