This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Illumex enables organizations to deploy genAI analytics agents by translating scattered, cryptic data into meaningful, context-rich business language with built-in governance. By creating business terms, suggesting metrics, and identifying potential conflicts, Illumex ensures data governance at the highest standards.
Access to high-qualitydata can help organizations start successful products, defend against digital attacks, understand failures and pivot toward success. Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good dataquality.
Furthermore, evaluation processes are important not only for LLMs, but are becoming essential for assessing prompt template quality, input dataquality, and ultimately, the entire application stack. ModelRunner definition For BedrockModelRunner , we need to find the model content_template.
Understanding Data Lakes A data lake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
With this definition of model risk, how do we ensure the models we build are technically correct? The first step would be to make sure that the data used at the beginning of the model development process is thoroughly vetted, so that it is appropriate for the use case at hand. To reference SR 11-7: .
Data should be designed to be easily accessed, discovered, and consumed by other teams or users without requiring significant support or intervention from the team that created it. Data should be created using standardized data models, definitions, and quality requirements. The domain of the data.
Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Introduction In today’s business landscape, data integration is vital.
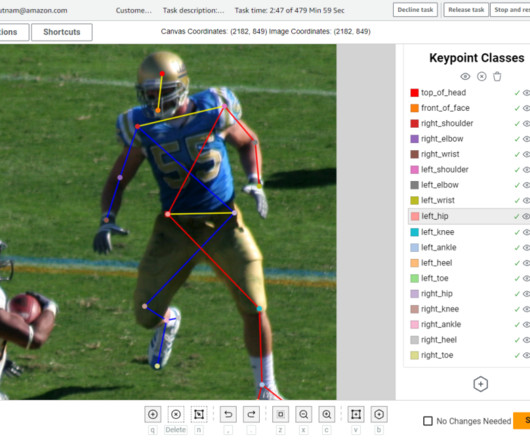
Labeling mistakes are important to identify and prevent because model performance for pose estimation models is heavily influenced by labeled dataquality and data volume. This custom workflow helps streamline the labeling process and minimize labeling errors, thereby reducing the cost of obtaining high-quality pose labels.
Building a tool for managing experiments can help your data scientists; 1 Keep track of experiments across different projects, 2 Save experiment-related metadata, 3 Reproduce and compare results over time, 4 Share results with teammates, 5 Or push experiment outputs to downstream systems.
Organizations struggle in multiple aspects, especially in modern-day data engineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. The second is that it can be really hard to classify and catalog data assets for discovery.
Organizations struggle in multiple aspects, especially in modern-day data engineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. The second is that it can be really hard to classify and catalog data assets for discovery.
Organizations struggle in multiple aspects, especially in modern-day data engineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. The second is that it can be really hard to classify and catalog data assets for discovery.
Human-written examples are more expensive to obtain but are more high quality. Dataquality: Was any filtering done to improve the quality of the generated data? In most cases, filtering is based on simple heuristics or a pre-trained model, which can result in noisy data. Improving dataquality. To
With the exponential growth of data and increasing complexities of the ecosystem, organizations face the challenge of ensuring data security and compliance with regulations. Data Processes and Organizational Structure Data Governance access controls enable the end-users to see how data processing works inside an organization.
Things to Keep in Mind Ensure dataquality by preprocessing it before determining the optimal chunk size. Examples include removing HTML tags or eliminating specific elements that contribute noise, particularly when data is sourced from the web. A word embedding is a vector representation of words. Precise Similarity Search.
And then, we’re trying to boot out features of the platform and the open-source to be able to take Hamilton data flow definitions and help you auto-generate the Airflow tasks. To a junior data scientist, it doesn’t matter if you’re using Airflow, Prefect , Dexter. I term it as a feature definition store.
Cost and resource requirements There are several cost-related constraints we had to consider when we ventured into the ML model deployment journey Data storage costs: Storing the data used to train and test the model, as well as any new data used for prediction, can add to the cost of deployment. S3 buckets.
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets (Kreutzer et al.). It conducts a careful audit of large-scale multilingual datasets covering 70 languages and identifies many dataquality issues that have previously gone unnoticed. I wrote about this paper when it first came out.
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. Your ML platform must have versioning in-built because code and data mostly make up the ML system.
They offer a focused selection of data, allowing for faster analysis tailored to departmental goals. Metadata This acts like the data dictionary, providing crucial information about the data itself. Metadata details the source of the data, its definition, and how it relates to other data points within the warehouse.
To strike a fine balance of democratizing data and AI access while maintaining strict compliance and regulatory standards, Amazon SageMaker Data and AI Governance is built into SageMaker Unified Studio. The table metadata is managed by Data Catalog. This is a SageMaker Lakehouse managed catalog backed by RMS storage.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content