This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Illumex enables organizations to deploy genAI analytics agents by translating scattered, cryptic data into meaningful, context-rich business language with built-in governance. By creating business terms, suggesting metrics, and identifying potential conflicts, Illumex ensures data governance at the highest standards.
. “Our AI engineers built a prompt evaluation pipeline that seamlessly considers cost, processing time, semantic similarity, and the likelihood of hallucinations,” Ros explained. It’s obviously an ambitious goal, but it’s important to our employees and it’s important to our clients,” explained Ros.
For now, we consider eight key dimensions of responsible AI: Fairness, explainability, privacy and security, safety, controllability, veracity and robustness, governance, and transparency. You define a denied topic by providing a natural language definition of the topic along with a few optional example phrases of the topic.
The SageMaker project template includes seed code corresponding to each step of the build and deploy pipelines (we discuss these steps in more detail later in this post) as well as the pipeline definition—the recipe for how the steps should be run. Workflow B corresponds to model quality drift checks.
It includes a built-in schema registry to validate event data from applications as expected, improving dataquality and reducing errors. This means they can be understood by people, are supported by code generation tools and are consistent with API definitions.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
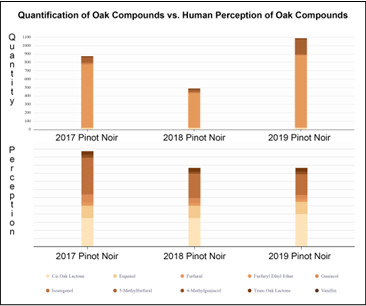
To explain this limitation, it is important to understand that the chemistry of sensory-based products is largely focused on quality control, i.e., how much of this analyte is in that mixture? Our descriptors are too vague, and our definitions vary based on individual biology and cultural experiences. For example, in the U.S.
Different definitions of safety exist, from risk reduction to minimizing harm from unwanted outcomes. Availability of training data: Deep learning’s efficacy relies heavily on dataquality, with simulation environments bridging the gap between real-world data scarcity and training requirements.
In this article, we will delve into the concept of data hygiene, its best practices, and key features, while also exploring the benefits it offers to businesses. It involves validating, cleaning, and enriching data to ensure its accuracy, completeness, and relevance. Large datasets may require significant processing time.
This article offers a measured exploration of AI agents, examining their definition, evolution, types, real-world applications, and technical architecture. Defining AI Agents At its simplest, an AI agent is an autonomous software entity capable of perceiving its surroundings, processing data, and taking action to achieve specified goals.
Definition says, machine learning is the ability of computers to learn without explicit programming. Instead of being told how to perform a task, they learn from data and improve their performance over time. It isn't easy to collect a good amount of qualitydata. Models […]
Taken together, this explains the poor market adoption of traditional MDM (Master Data Management) solutions. Tamr makes it easy to load new sources of data because its AI automatically maps new fields into a defined entity schema. What role do large language models (LLMs) play in Tamr’s dataquality and enrichment processes?
Summary: This blog explains how to build efficient data pipelines, detailing each step from data collection to final delivery. Introduction Data pipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
Few nonusers (2%) report that lack of data or dataquality is an issue, and only 1.3% AI users are definitely facing these problems: 7% report that dataquality has hindered further adoption, and 4% cite the difficulty of training a model on their data.
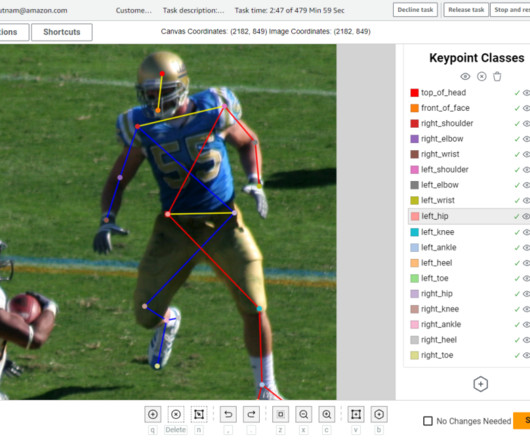
Labeling mistakes are important to identify and prevent because model performance for pose estimation models is heavily influenced by labeled dataquality and data volume. This custom workflow helps streamline the labeling process and minimize labeling errors, thereby reducing the cost of obtaining high-quality pose labels.
Challenges and Considerations Dataquality is a cornerstone of successful data mining. Incomplete data, or missing values, limits the effectiveness of data mining techniques, as it reduces the available information for analysis. Model complexity is another factor affecting interpretability.
The article also addresses challenges like dataquality and model complexity, highlighting the importance of ethical considerations in Machine Learning applications. Key steps involve problem definition, data preparation, and algorithm selection. Dataquality significantly impacts model performance.
Data should be designed to be easily accessed, discovered, and consumed by other teams or users without requiring significant support or intervention from the team that created it. Data should be created using standardized data models, definitions, and quality requirements. What is Data Mesh?
By visualizing data distributions, scatter plots, or heatmaps, data scientists can quickly identify outliers, clusters, or trends that might go unnoticed in raw data. This aids in detecting anomalies, understanding dataquality issues, and improving data cleaning processes.
It should be possible to locate where the data and models for an experiment came from, so your data scientists can explore the events of the experiment and the processes that led to them. This unlocks two significant benefits: Reproducibility : Ensuring every experiment your data scientists run is reproducible.
Alex Ratner, CEO and co-founder of Snorkel AI, presented a high-level introduction to data-centric AI at Snorkel’s Future of Data-Centric AI virtual conference in 2022. It’s a really historically exciting time—definitely in AI, but I venture across many different technology areas.
Alex Ratner, CEO and co-founder of Snorkel AI, presented a high-level introduction to data-centric AI at Snorkel’s Future of Data-Centric AI virtual conference in 2022. It’s a really historically exciting time—definitely in AI, but I venture across many different technology areas.
For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes dataquality, privacy, and compliance. But there is definitely room for improvement in our deployment as well.
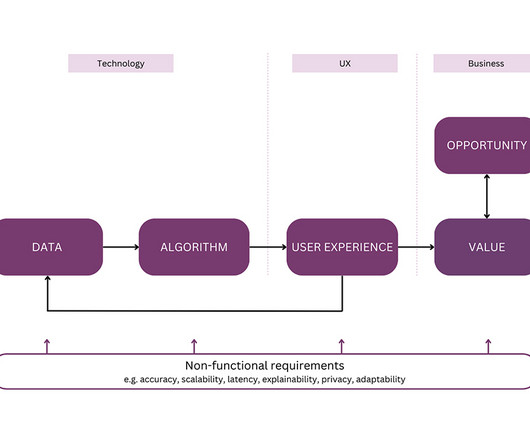
The model serves as a tool for the discussion, planning, and definition of AI products by cross-disciplinary AI and product teams, as well as for alignment with the business department. It aims to bring together the perspectives of product managers, UX designers, data scientists, engineers, and other team members.
Sabine: Right, so, Jason, to kind of warm you up a bit… In 1 minute, how would you explain conversational AI? You need to have a structured definition around what you’re trying to do so your data annotators can label information for you. How do you ensure dataquality when building NLP products?
But some of these queries are still recurrent and haven’t been explained well. Furthermore, Netflix’s Maestro platform uses DAGs to orchestrate and manage workflows within machine learning/data pipelines. How should the machine learning pipeline operate?
This article will explain what a semantic layer is, why businesses need one, and how it enables self-service business intelligence. A semantic layer is a key component in data management infrastructure. Businesses can avoid dataquality issues by integrating a robust semantic layer in their data operations.
Olalekan said that most of the random people they talked to initially wanted a platform to handle dataquality better, but after the survey, he found out that this was the fifth most crucial need. The user stories will explain how your data scientist will go about solving a company’s use case(s) to get to a good result.
Another fundamental challenge lies in the inconsistency of business definitions across different systems and departments. When you connect an AI agent or chatbot to these systems and begin asking questions, you'll get different answers because the datadefinitions aren't aligned.
In this article, we will delve into the world of AutoML, exploring its definition, inner workings, and its potential to reshape the future of machine learning. DataQuality: AutoML cannot compensate for poor dataquality. It relies on high-quality, relevant data to generate accurate models.
From the outset, AWS has prioritized responsible AI innovation and developed rigorous methodologies to build and operate our AI services with consideration for fairness, explainability, privacy and security, safety, controllability, veracity and robustness, governance, and transparency.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content