This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AI algorithms learn from data; they identify patterns, make decisions, and generate predictions based on the information they're fed. Consequently, the quality of this training data is paramount. AI's Role in Improving DataQuality While the problem of dataquality may seem daunting, there is hope.
“Managing dynamic dataquality, testing and detecting for bias and inaccuracies, ensuring high standards of data privacy, and ethical use of AI systems all require human oversight,” he said. Want to learn more about AI and big data from industry leaders?
Illumex enables organizations to deploy genAI analytics agents by translating scattered, cryptic data into meaningful, context-rich business language with built-in governance. By creating business terms, suggesting metrics, and identifying potential conflicts, Illumex ensures data governance at the highest standards.
Simply put, data governance is the process of establishing policies, procedures, and standards for managing data within an organization. It involves defining roles and responsibilities, setting standards for dataquality, and ensuring that data is being used in a way that is consistent with the organization’s goals and values.
We began by preprocessing the images to enhance dataquality. There are different types of connectivity, primarily 4-connectivity and 8-connectivity: 4-Connectivity: Definition: In 4-connectivity, a pixel (of interest) is considered connected to another pixel if they share an edge.
Access to high-qualitydata can help organizations start successful products, defend against digital attacks, understand failures and pivot toward success. Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good dataquality.
Technical debt, in the simplest definition, is the accrual of poor quality code during the creation of a piece of software. When it comes to AI, just over 72 % of leaders want to adopt AI to improve employee productivity, yet the top concern around implementing AI is dataquality and control. What Is Technical Debt?
Furthermore, evaluation processes are important not only for LLMs, but are becoming essential for assessing prompt template quality, input dataquality, and ultimately, the entire application stack. ModelRunner definition For BedrockModelRunner , we need to find the model content_template.
Definition and Types of Hallucinations Hallucinations in LLMs are typically categorized into two main types: factuality hallucination and faithfulness hallucination. Mitigation Strategies Various strategies have been developed to address hallucinations, improve dataquality, enhance training processes, and refine decoding methods.
We discuss the important components of fine-tuning, including use case definition, data preparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Additionally, the clips were rated both by GPT-4o, and six human annotators, following LLaVA-Hound ‘s definition of ‘hallucination' (i.e., The researchers compared the quality of the captions to the Qwen2-VL-72B collection, obtaining a slightly improved score. the capacity of a model to invent spurious content).
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
It includes a built-in schema registry to validate event data from applications as expected, improving dataquality and reducing errors. This means they can be understood by people, are supported by code generation tools and are consistent with API definitions.
According to Oracle , best practices for the planning process include five categories of information: Project definition: This is the blueprint that will include relevant information for an implementation project. During this phase, the platform is configured to meet specific business requirements and core data migration begins.
The SageMaker project template includes seed code corresponding to each step of the build and deploy pipelines (we discuss these steps in more detail later in this post) as well as the pipeline definition—the recipe for how the steps should be run. Workflow B corresponds to model quality drift checks.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. From our experience definitely, we have seen that it is advisable to have the model fine-tuned and deployed locally and that is dedicated to your scenario instead of relying on APIs.
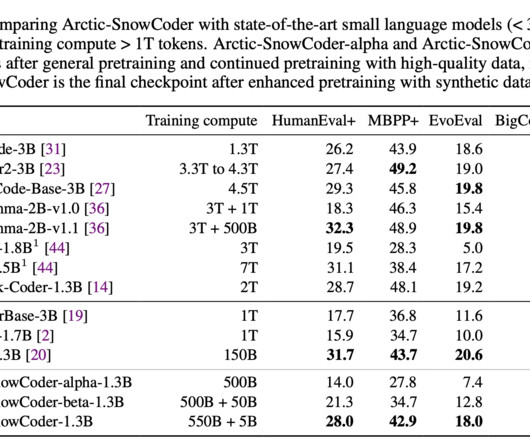
In code-related applications, well-structured, annotated, and clean data ensures that models can generate accurate, efficient, and reliable outputs for real-world programming tasks. A significant issue in code model development is the lack of precise definitions of “high-quality” data. compared to StarCoder2-3B’s 27.4.
Go to Definition: This feature lets users right-click on any Python variable or function to access its definition. This facilitates seamless navigation through the codebase, allowing users to locate and understand variable or function definitions quickly. This visual aid helps developers quickly identify and correct mistakes.
Our descriptors are too vague, and our definitions vary based on individual biology and cultural experiences. When it comes to dataquality, we realized a valid training set could not be generated from existing commercial or crowd-sourced data. For example, in the U.S. We would have to create our own, in-house.
The right data architecture to link and gain insight across silos requires the communication and coordination of a strategic data governance program. Inconsistent or lacking business terminology, master data, hierarchies Raw data without clear business definitions and rules is ripe for misinterpretation and confusion.
Simple Random Sampling Definition and Overview Simple random sampling is a technique in which each member of the population has an equal chance of being selected to form the sample. Analyze the obtained sample data. Analyze the obtained sample data. Collect data from individuals within the selected clusters.
They must meet strict standards for accuracy, security, and dataquality, with ongoing human oversight. Definition Scope and Applicability Broad Scope and Horizontal Application The Act is quite expansive in nature, and it applies horizontally to AI activities across various sectors.
Different definitions of safety exist, from risk reduction to minimizing harm from unwanted outcomes. Availability of training data: Deep learning’s efficacy relies heavily on dataquality, with simulation environments bridging the gap between real-world data scarcity and training requirements.
Gartner predicts that 30% of generative AI projects will be abandoned after proof of concept by 2025, often due to unclear business value, inadequate risk controls, or poor dataquality. Moreover, a separate recent survey found that a quarter of IT leaders already regret their hasty AI investments.
Prolific was created by researchers for researchers, aiming to offer a superior method for obtaining high-quality human data and input for cutting-edge research. Today, over 35,000 researchers from academia and industry rely on Prolific AI to collect definitive human data and feedback.
This article offers a measured exploration of AI agents, examining their definition, evolution, types, real-world applications, and technical architecture. Defining AI Agents At its simplest, an AI agent is an autonomous software entity capable of perceiving its surroundings, processing data, and taking action to achieve specified goals.
Additionally, supervised data in chat format was used to align the model with human preferences on instruct-following, truthfulness, honesty, and helpfulness. The focus on dataquality was paramount. A lot of time is spent on gathering and cleaning the training data for LLMs, yet the end result is often still raw/dirty.
Definition says, machine learning is the ability of computers to learn without explicit programming. Instead of being told how to perform a task, they learn from data and improve their performance over time. It isn't easy to collect a good amount of qualitydata.
Additionally, it addresses common challenges and offers practical solutions to ensure that fact tables are structured for optimal dataquality and analytical performance. Introduction In today’s data-driven landscape, organisations are increasingly reliant on Data Analytics to inform decision-making and drive business strategies.
You define a denied topic by providing a natural language definition of the topic along with a few optional example phrases of the topic. This includes handling unexpected inputs, adversarial manipulations, and varying dataquality without significant degradation in performance.
With this definition of model risk, how do we ensure the models we build are technically correct? The first step would be to make sure that the data used at the beginning of the model development process is thoroughly vetted, so that it is appropriate for the use case at hand. To reference SR 11-7: .
Understanding Data Lakes A data lake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
Summary: This article provides a comprehensive overview of data migration, including its definition, importance, processes, common challenges, and popular tools. By understanding these aspects, organisations can effectively manage data transfers and enhance their data management strategies for improved operational efficiency.
Tamr makes it easy to load new sources of data because its AI automatically maps new fields into a defined entity schema. This means that regardless of what a new data source calls a particular field (example: cust_name) it gets mapped to the right central definition of that entity (example: “customer name”).
Informatica DataQuality Pros: Robust data profiling and standardization capabilities. Comprehensive data cleansing and enrichment options. Scalable for handling enterprise-level data. Integration with Informatica’s broader suite of data management tools. Offers dataquality monitoring and reporting.
Few nonusers (2%) report that lack of data or dataquality is an issue, and only 1.3% AI users are definitely facing these problems: 7% report that dataquality has hindered further adoption, and 4% cite the difficulty of training a model on their data.
These pipelines automate collecting, transforming, and delivering data, crucial for informed decision-making and operational efficiency across industries. Efficient integration ensures data consistency and availability, which is essential for deriving accurate business insights. What are the Critical Steps in Building a Data Pipeline?
Data governance and security Like a fortress protecting its treasures, data governance, and security form the stronghold of practical Data Intelligence. Think of data governance as the rules and regulations governing the kingdom of information. It ensures dataquality , integrity, and compliance.
This crucial stage involves data cleaning, normalisation, transformation, and integration. By addressing issues like missing values, duplicates, and inconsistencies, preprocessing enhances dataquality and reliability for subsequent analysis. Data Cleaning Data cleaning is crucial for data integrity.
A data janitor is a person who works to take big data and condense it into useful amounts of information. Also known as a "data wrangler", a data janitor sifts through data for companies in the information technology industry. This could even mean the traditional One LLM to rule them All?: No, not really.
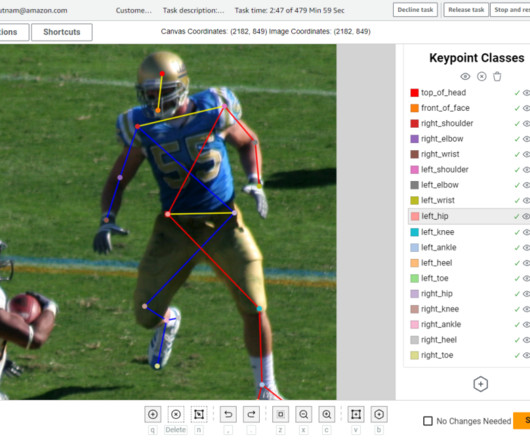
Labeling mistakes are important to identify and prevent because model performance for pose estimation models is heavily influenced by labeled dataquality and data volume. This custom workflow helps streamline the labeling process and minimize labeling errors, thereby reducing the cost of obtaining high-quality pose labels.
The complexity of developing a bespoke classification machine learning model varies depending on a variety of aspects such as dataquality, algorithm, scalability, and domain knowledge, to mention a few.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content