This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
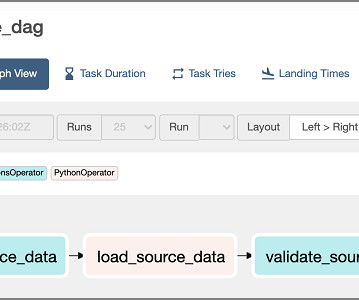
Axfood has a structure with multiple decentralized datascience teams with different areas of responsibility. Together with a central data platform team, the datascience teams bring innovation and digital transformation through AI and ML solutions to the organization.
Crucially, the insurance sector is a financially regulated industry where the transparency, explainability and auditability of algorithms is of key importance to the regulator. Usage risk—inaccuracy The performance of an AI system heavily depends on the data from which it learns.
This includes features for model explainability, fairness assessment, privacy preservation, and compliance tracking. With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale.
DataQuality Now that you’ve learned more about your data and cleaned it up, it’s time to ensure the quality of your data is up to par. With these data exploration tools, you can determine if your data is accurate, consistent, and reliable.
Networking Always a highlight and crowd-pleasure of ODSC conferences, the networking events Monday-Wednesday were well-deserved after long days of datascience training sessions. You can also get datascience training on-demand wherever you are with our Ai+ Training platform. Register now before ticket prices go up !
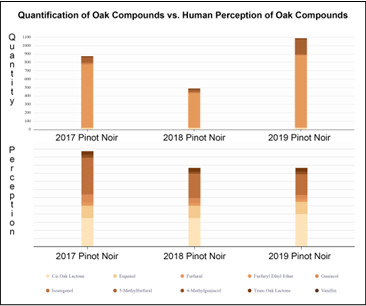
To explain this limitation, it is important to understand that the chemistry of sensory-based products is largely focused on quality control, i.e., how much of this analyte is in that mixture? When it comes to dataquality, we realized a valid training set could not be generated from existing commercial or crowd-sourced data.
MLOps practitioners have many options to establish an MLOps platform; one among them is cloud-based integrated platforms that scale with datascience teams. TWCo was looking to scale its ML operations with more transparency and less complexity to allow for more manageable ML workflows as their datascience team grew.
A high amount of effort is spent organizing data and creating reliable metrics the business can use to make better decisions. This creates a daunting backlog of dataquality improvements and, sometimes, a graveyard of unused dashboards that have not been updated in years. Let’s start with an example.
If the test or validation data distribution has too much deviance from the training data distribution, then we must go for retraining since it is a sign of population drift. Model Interpretability and Explainability Model interpretability and explainability describe how a machine learning model arrives at its predictions or decisions.
Transparency and explainability : Making sure that AI systems are transparent, explainable, and accountable. It includes processes for monitoring model performance, managing risks, ensuring dataquality, and maintaining transparency and accountability throughout the model’s lifecycle.
At Astronomer, he spearheads the creation of Apache Airflow features specifically designed for ML and AI teams and oversees the internal datascience team. Can you share some information about your journey in datascience and AI, and how it has shaped your approach to leading engineering and analytics teams?
Michael Dziedzic on Unsplash I am often asked by prospective clients to explain the artificial intelligence (AI) software process, and I have recently been asked by managers with extensive software development and datascience experience who wanted to implement MLOps. Join thousands of data leaders on the AI newsletter.
As organisations increasingly rely on data-driven insights, effective ETL processes ensure data integrity and quality, enabling informed decision-making. ETL facilitates Data Analytics by transforming raw data into meaningful insights, empowering businesses to uncover trends, track performance, and make strategic decisions.
With the advent of big data in the modern world, RTOS is becoming increasingly important. As software expert Tim Mangan explains, a purpose-built real-time OS is more suitable for apps that involve tons of data processing. The Big Data and RTOS connection IoT and embedded devices are among the biggest sources of big data.
In this article, we will delve into the concept of data hygiene, its best practices, and key features, while also exploring the benefits it offers to businesses. It involves validating, cleaning, and enriching data to ensure its accuracy, completeness, and relevance. Large datasets may require significant processing time.
Evaluate the computing resources and development environment that the datascience team will need. Large projects or those involving text, images, or streaming data may need specialized infrastructure. Data aggregation such as from hourly to daily or from daily to weekly time steps may also be required.
In this post, we show how to configure a new OAuth-based authentication feature for using Snowflake in Amazon SageMaker Data Wrangler. Snowflake is a cloud data platform that provides data solutions for data warehousing to datascience. Data Wrangler creates the report from the sampled data.
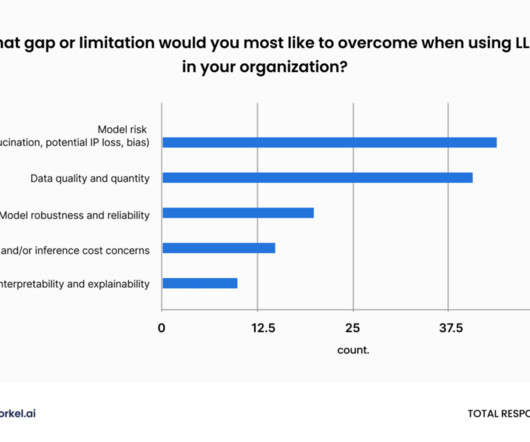
Addressing the Challenges of Generative AI: DataQuality, Governance, and Compliance One of the major hurdles businesses face when adopting generative AI is dataquality. Yves Mulkers stressed the need for clean, reliable data as a foundation for AI success.
Ensuring dataquality, governance, and security may slow down or stall ML projects. Data engineering – Identifies the data sources, sets up data ingestion and pipelines, and prepares data using Data Wrangler. Conduct exploratory analysis and data preparation.
To achieve the trust, quality, and reliability necessary for production applications, enterprise datascience teams must develop proprietary data for use with specialized models. Data scientists can best improve LLM performance on specific tasks by feeding them the right data prepared in the right way.
DataScience is the process in which collecting, analysing and interpreting large volumes of data helps solve complex business problems. A Data Scientist is responsible for analysing and interpreting the data, ensuring it provides valuable insights that help in decision-making.
This architecture design represents a multi-account strategy where ML models are built, trained, and registered in a central model registry within a datascience development account (which has more controls than a typical application development account). The following figure depicts a successful run of the training pipeline.
This blog discusses best practices, real-world use cases, security and privacy considerations, and how Data Scientists can use ChatGPT to their full potential. Machine Learning Models: How Data Scientists Use ChatGPT Data Scientists use ChatGPT as a powerful ally in the ever-evolving field of DataScience.
LLM distillation will become a much more common and important practice for datascience teams in 2024, according to a poll of attendees at Snorkel AI’s 2023 Enterprise LLM Virtual Summit. As datascience teams reorient around the enduring value of small, deployable models, they’re also learning how LLMs can accelerate data labeling.
The Tangent Information Modeler, Time Series Modeling Reinvented Philip Wauters | Customer Success Manager and Value Engineer | Tangent Works Existing techniques for modeling time series data face limitations in scalability, agility, explainability, and accuracy. LLMs in Data Analytics: Can They Match Human Precision?
If you want an overview of the Machine Learning Process, it can be categorized into 3 wide buckets: Collection of Data: Collection of Relevant data is key for building a Machine learning model. It isn't easy to collect a good amount of qualitydata. You need to know two basic terminologies here, Features and Labels.
Third-party FMs are expensive to use at scale, and funneling consumer financial data through an open-access foundation model raises serious privacy concerns. Hosting a foundation model or building one from scratch is also no small feat; their massive sizes necessitate enormous computing and datascience resources.
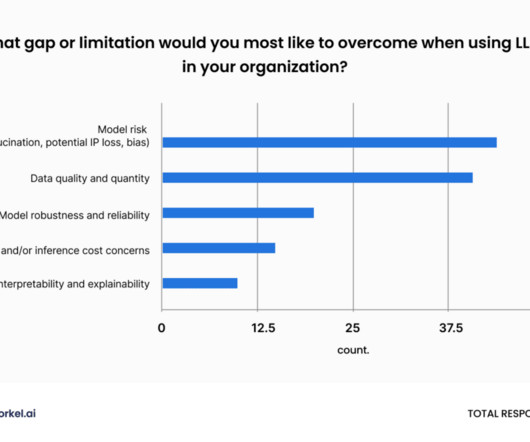
The following are some of the primary difficulties for deep learning in software development: DataQuality and Quantity Deep learning models need a lot of labeled and quality training data. To prevent biases and overfitting, it is also essential to ensure the data's diversity and representativeness.
By simplifying Time Series Forecasting models and accelerating the AI lifecycle, DataRobot can centralize collaboration across the business—especially datascience and IT teams—and maximize ROI. Prepare your data for Time Series Forecasting. The model training process is not a black box—it includes trust and explainability.
Chip Huyen began by explaining how AI engineering has emerged as a distinct discipline, evolving out of traditional machine learning engineering. This shift has made AI engineering more multidisciplinary, incorporating elements of datascience, software engineering, and systemdesign. Focus on dataquality over quantity.
LLM distillation will become a much more common and important practice for datascience teams in 2024, according to a poll of attendees at Snorkel AI’s 2023 Enterprise LLM Virtual Summit. As datascience teams reorient around the enduring value of small, deployable models, they’re also learning how LLMs can accelerate data labeling.
All models built within DataRobot MLOps support ethical AI through configurable bias monitoring and are fully explainable and transparent. The in-built, dataquality assessments and visualization tools result in equitable, fair models that minimize the potential for harm, along with world-class data drift, service help, and accuracy tracking.
Bioinformatics: A Haven for Data Scientists and Machine Learning Engineers: Bioinformatics offers an unparalleled opportunity for data scientists and machine learning engineers to apply their expertise in solving complex biological problems.
Third-party FMs are expensive to use at scale, and funneling consumer financial data through an open-access foundation model raises serious privacy concerns. Hosting a foundation model or building one from scratch is also no small feat; their massive sizes necessitate enormous computing and datascience resources.
If you’re an aspiring DataScience professional , Data Visualisation will be part of your job role in presenting the insights in a visually understandable format. However, if you’re a beginner in the field, you need to undertake a Data Visualisation course for a beginner.
To achieve the trust, quality, and reliability necessary for production applications, enterprise datascience teams must develop proprietary data for use with specialized models. Data scientists can best improve LLM performance on specific tasks by feeding them the right data prepared in the right way.
It also enables you to evaluate the models using advanced metrics as if you were a data scientist. We explain the metrics and show techniques to deal with data to obtain better model performance. Quick model is useful when iterating to more quickly understand the impact of data changes to your model accuracy.
Innovation and New Opportunities By analyzing data, organizations can uncover new opportunities for innovation and growth. Types of Analytics Descriptive Analytics with Example Explained Descriptive Analytics summarises and interprets historical data. It helps in gaining insights into past performance.
As you can imagine, datascience is a pretty loose term or big tent idea overall. Though just about every industry imaginable utilizes the skills of a data-focused professional, each has its own challenges, needs, and desired outcomes. What makes this job title unique is the “Swiss army knife” approach to data.
Revolutionizing Healthcare through DataScience and Machine Learning Image by Cai Fang on Unsplash Introduction In the digital transformation era, healthcare is experiencing a paradigm shift driven by integrating datascience, machine learning, and information technology.
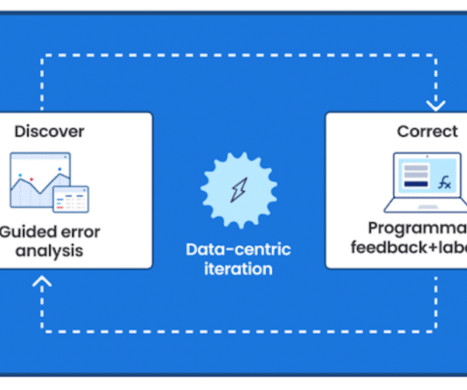
Snorkel AI provides a data-centric AI development platform for AI teams to unlock production-grade model quality and accelerate time-to-value for their investments. Seldon is a deployment solution that helps teams serve, monitor, explain, and manage their ML models in production.
Snorkel AI provides a data-centric AI development platform for AI teams to unlock production-grade model quality and accelerate time-to-value for their investments. Seldon is a deployment solution that helps teams serve, monitor, explain, and manage their ML models in production.
Q1: Which are the 2 high focuses of datascience? A1: The two high focuses of datascience are Velocity and Variety, which are characteristics of Big Data. Velocity refers to the increasing rate at which data is collected and obtained, while Variety refers to the different types and sources of data.
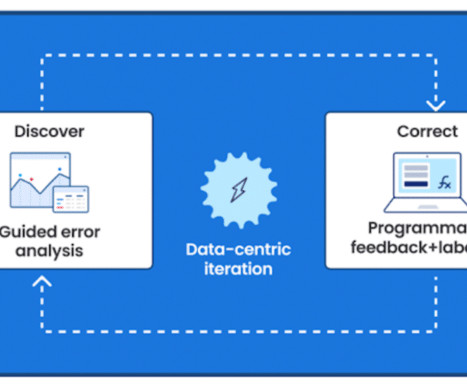
Suddenly, non-technical users witnessed the LLM-backed chatbot’s ability to regurgitate knowledge, explain jokes and write poems. When models are pretrained, data is the main means for customization and fine-tuning of the models,” Gartner® said. The data-centric philosophy goes well beyond the point of training a model.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content