

MLOps Landscape in 2023: Top Tools and Platforms
The MLOps Blog
JUNE 27, 2023
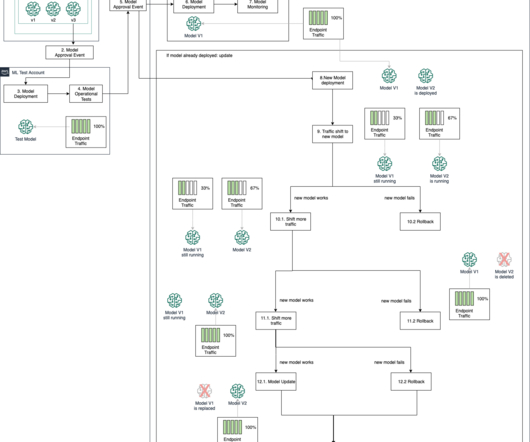
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for data science teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy data science projects.











Let's personalize your content