This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, the success of ML projects is heavily dependent on the quality of data used to train models. Poor dataquality can lead to inaccurate predictions and poor model performance. Understanding the importance of data […] The post What is DataQuality in Machine Learning?
Data analytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities. Flipping the paradigm: Using AI to enhance dataquality What if we could change the way we think about dataquality?
In the data-driven world […] The post Monitoring DataQuality for Your Big Data Pipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise. A single mistake, glitch, or slip-up could endanger the trip.
Introduction Ensuring dataquality is paramount for businesses relying on data-driven decision-making. As data volumes grow and sources diversify, manual quality checks become increasingly impractical and error-prone.
AI-powered marketing fail Let’s take a closer look at what AI-powered marketing with poor dataquality could look like. The culprit behind a disconnected and impersonal generative AI experience is dataquality — poor dataquality = poor customer experience. What results do you expect to achieve?
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. DataqualityDataquality is essentially the measure of data integrity.
Companies rely heavily on data and analytics to find and retain talent, drive engagement, improve productivity and more across enterprise talent management. However, analytics are only as good as the quality of the data, which must be error-free, trustworthy and transparent. What is dataquality? million each year.
However, analytics are only as good as the quality of the data, which aims to be error-free, trustworthy, and transparent. According to a Gartner report , poor dataquality costs organizations an average of USD $12.9 What is dataquality? Dataquality is critical for data governance.
Modern dataquality practices leverage advanced technologies, automation, and machine learning to handle diverse data sources, ensure real-time processing, and foster collaboration across stakeholders.
They must demonstrate tangible ROI from AI investments while navigating challenges around dataquality and regulatory uncertainty. After all, isnt ensuring strong data governance a core principle that the EU AI Act is built upon? To adapt, companies must prioritise strengthening their approach to dataquality.
To operate effectively, multimodal AI requires large amounts of high-qualitydata from multiple modalities, and inconsistent dataquality across modalities can affect the performance of these systems.
The best way to overcome this hurdle is to go back to data basics. Organisations need to build a strong data governance strategy from the ground up, with rigorous controls that enforce dataquality and integrity. The many obstacles holding companies back from rolling out AI tools can be overcome without too much trouble.
Its not a choice between better data or better models. The future of AI demands both, but it starts with the data. Why DataQuality Matters More Than Ever According to one survey, 48% of businesses use big data , but a much lower number manage to use it successfully. Why is this the case?
This is creating a major headache for corporate data science teams who have had to increasingly focus their limited resources on cleaning and organizing data. In a recent state of engineering report conducted by DBT , 57% of data science professionals cited poor dataquality as a predominant issue in their work.
Dataquality is another critical concern. AI systems are only as good as the data fed into them. If the input data is outdated, incomplete, or biased, the results will inevitably be subpar. Another important consideration is dataquality.
Introduction In the realm of machine learning, the veracity of data holds utmost significance in the triumph of models. Inadequate dataquality can give rise to erroneous predictions, unreliable insights, and overall performance.
These trends will elevate the role of data observability in ensuring that organizations can scale their AI initiatives while maintaining high standards for dataquality and governance. As organizations increasingly rely on AI to drive business decisions, the need for trustworthy, high-qualitydata becomes even more critical.
This article was published as a part of the Data Science Blogathon Overview Running data projects takes a lot of time. Poor data results in poor judgments. Running unit tests in data science and data engineering projects assures dataquality. You know your code does what you want it to do.
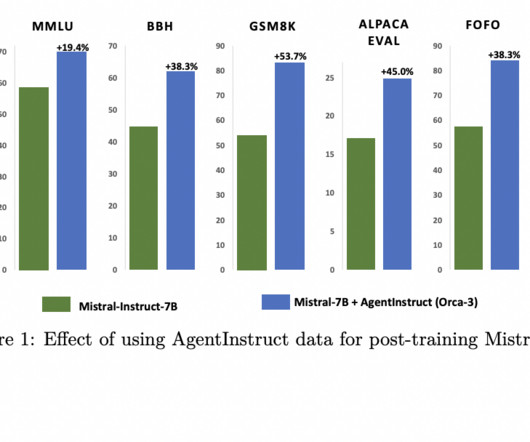
In conclusion, AgentInstruct represents a breakthrough in generating synthetic data for AI training. Automating the creation of diverse and high-qualitydata addresses the critical issues of manual curation and dataquality, leading to significant improvements in the performance and reliability of large language models.
Introduction Whether you’re a fresher or an experienced professional in the Data industry, did you know that ML models can experience up to a 20% performance drop in their first year? Monitoring these models is crucial, yet it poses challenges such as data changes, concept alterations, and dataquality issues.
Phi-2’s achievements are underpinned by two key aspects: Training dataquality: Microsoft emphasises the critical role of training dataquality in model performance. Phi-2 leverages “textbook-quality” data, focusing on synthetic datasets designed to impart common sense reasoning and general knowledge.
The process begins with data ingestion and preprocessing, where prescriptive AI gathers information from different sources, such as IoT sensors, databases, and customer feedback. It organizes it by filtering out irrelevant details and ensuring dataquality.
This innovative technique aims to generate diverse and high-quality instruction data, addressing challenges associated with duplicate data and limited control over dataquality in existing methods.
DataQuality: The Foundational Strength of Business-driven AI The success of AI-powered transformation depends on high-quality, well-structured data. Organizations must, therefore, design their AI strategies around their core business objectives, ensuring their data ecosystems support AI-driven decision-making.
Challenges of Using AI in Healthcare Physicians, doctors, nurses, and other healthcare providers face many challenges integrating AI into their workflows, from displacement of human labor to dataquality issues. Interoperability Problems and DataQuality Issues Data from different sources can often fail to integrate seamlessly.
Your organization must also make certain other strategic considerations in order to preserve security and dataquality. Its essential to invest in high-quality, secure data infrastructureand ensure that they are trained on accurate and diverse datasets.
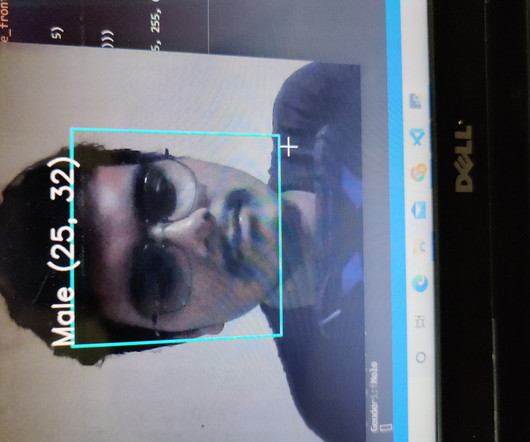
This article was published as a part of the Data Science Blogathon. Introduction In machine learning, the data is an essential part of the training of machine learning algorithms. The amount of data and the dataquality highly affect the results from the machine learning algorithms.
It necessitates having access to the right data — data that provides rich context on actual business spend patterns, supplier performance, market dynamics, and real-world constraints. Inadequate access to data means life or death for AI innovation within the enterprise.
Teams with varied backgrounds are better at spotting blind spots in data and designing systems that work for a broader range of users. The Bottom Line AI has incredible potential, but its effectiveness depends on its dataquality. Inclusive teams lead to better outcomes, making AI brighter and fairer.
Choosing the best appropriate activation function can help one get better results with even reduced dataquality; hence, […]. Introduction In deep learning, the activation functions are one of the essential parameters in training and building a deep learning model that makes accurate predictions.
Let us look at how Allen AI built this model: Stage 1: Strategic Data Selection The team knew that model quality starts with dataquality. But here is the key insight: they did not just aggregate data – they created targeted datasets for specific skills like mathematical reasoning and coding proficiency.
Introduction Managing databases often means dealing with duplicate records that can complicate data analysis and operations. Whether you’re cleaning up customer lists, transaction logs, or other datasets, removing duplicate rows is vital for maintaining dataquality.
Enterprise-wide AI adoption faces barriers like dataquality, infrastructure constraints, and high costs. While Cirrascale does not offer DataQuality type services, we do partner with companies that can assist with Data issues. How does Cirrascale address these challenges for businesses scaling AI initiatives?
AI has the opportunity to significantly improve the experience for patients and providers and create systemic change that will truly improve healthcare, but making this a reality will rely on large amounts of high-qualitydata used to train the models. Why is data so critical for AI development in the healthcare industry?
Addressing this gap will require a multi-faceted approach including grappling with issues related to dataquality and ensuring that AI systems are built on reliable, unbiased, and representative datasets. Companies have struggled with dataquality and data hygiene.
First is clear alignment of the data strategy with the business goals, making sure the technology teams are working on what matters the most to the business. Second, is dataquality and accessibility, the quality of the data is critical. Poor dataquality will lead to inaccurate insights.
From technical limitations to dataquality and ethical concerns, it’s clear that the journey ahead is still full of obstacles. Additionally, as dataquality improves and companies develop more robust data-sharing practices, AI systems will become better equipped to make groundbreaking discoveries.
Simply put, data governance is the process of establishing policies, procedures, and standards for managing data within an organization. It involves defining roles and responsibilities, setting standards for dataquality, and ensuring that data is being used in a way that is consistent with the organization’s goals and values.
“Managing dynamic dataquality, testing and detecting for bias and inaccuracies, ensuring high standards of data privacy, and ethical use of AI systems all require human oversight,” he said.
Add in common issues like poor dataquality, scalability limits, and integration headaches, and its easy to see why so many GenAI PoCs fail to move forward. Beyond the Hype: The Reality of GenAI PoCs GenAI adoption is clearly on the rise, but the true success rate of PoCs remains unclear.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content