This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Snowflake is a cloud dataplatform solution with unique features. The post Getting Started With Snowflake DataPlatform appeared first on Analytics Vidhya.
Though building applications and choosing different Large Language Models has become easier, the data uploading part, where the data comes from various sources is still time-consuming for developers while developing LLM-powered applications as the developers […] The post Introduction to Embedchain – A DataPlatform Tailored for LLMs appeared (..)
Redis supports several data types, including strings, lists, sets, and hyperloglogs. Redis-py is one of the most used Redis Clients for python to access the Redis […] The post Introduction to Redis OM in Python appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Snowflake is a cloud dataplatform that comes with a lot of unique features when compared to traditional on-premise RDBMS systems. The post 5 Features Of Snowflake That Data Engineers Must Know appeared first on Analytics Vidhya.
Meet Briefer , a cool AI startup that offers a Notion-like interface that simplifies SQL and Python code execution, collaboration through comments and real-time editing, and direct connections to data sources. As users type, it suggests AI-powered code snippets, automating repetitive operations with scheduled Python block execution.
This allows the Masters to scale analytics and AI wherever their data resides, through open formats and integration with existing databases and tools. “Hole distances and pin positions vary from round to round and year to year; these factors are important as we stage the data.”
The solution harnesses the capabilities of generative AI, specifically Large Language Models (LLMs), to address the challenges posed by diverse sensor data and automatically generate Python functions based on various data formats. The solution only invokes the LLM for new device data file type (code has not yet been generated).
To pursue a data science career, you need a deep understanding and expansive knowledge of machine learning and AI. Your skill set should include the ability to write in the programming languages Python, SAS, R and Scala. And you should have experience working with big dataplatforms such as Hadoop or Apache Spark.
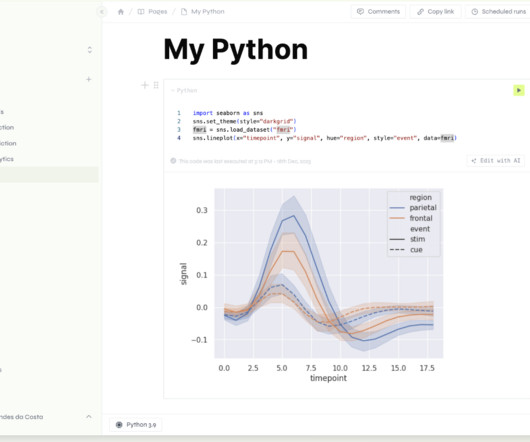
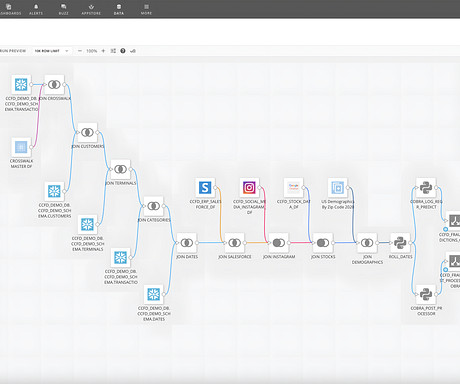
To start, get to know some key terms from the demo: Snowflake: The centralized source of truth for our initial data Magic ETL: Domo’s tool for combining and preparing data tables ERP: A supplemental data source from Salesforce Geographic: A supplemental data source (i.e., Instagram) used in the demo Why Snowflake?
Data engineering teams have grown up around the rise of data warehousing and business intelligence applications over the last decade and historically have operated in the world of SQL, structured databases and business analytics processes designed for data analysts and C-suite consumers.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
We’ll also discuss some of the benefits of using set union(), and we’ll see why it’s a popular tool for Python developers. How to Build a 5-Layer Data Stack Spinning up a dataplatform doesn’t have to be complicated. Here are the 5 must-have layers to drive data product adoption at scale.
ML data has unique requirements, like combining and extracting data from structured and unstructured sources, having metadata allowing for responsible data use, or describing ML usage characteristics like training, test, and validation sets. Taken as a whole, these enhancements significantly lessen the load of data development.
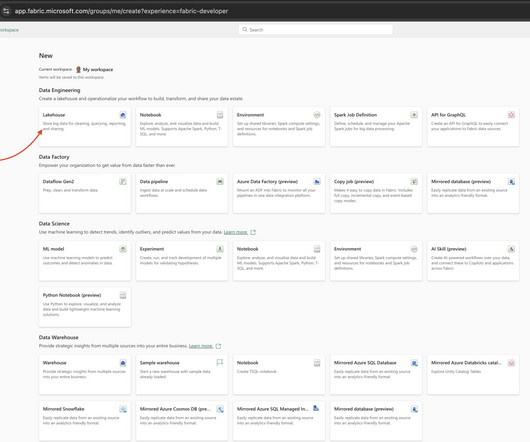
It provides a suite of tools for data engineering, data science, business intelligence, and analytics. Once the libraries are installed, proceed by importing the essential Python and Spark libraries into your notebook. In this section, we cover how-to run successfully John Snow Labs LLMs on Azure Fabric.
Keeping track of how exactly the incoming data (the feature pipeline’s input) has to be transformed and ensuring that each model receives the features precisely how it saw them during training is one of the hardest parts of architecting ML systems. All of them are written in Python. This is where feature stores come in.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities.
Key Features : Speed : Spark processes data in-memory, making it up to 100 times faster than Hadoop MapReduce in certain applications. Ease of Use : Supports multiple programming languages including Python, Java, and Scala. Key Features : Cost Efficiency : Pay only for the resources you use.
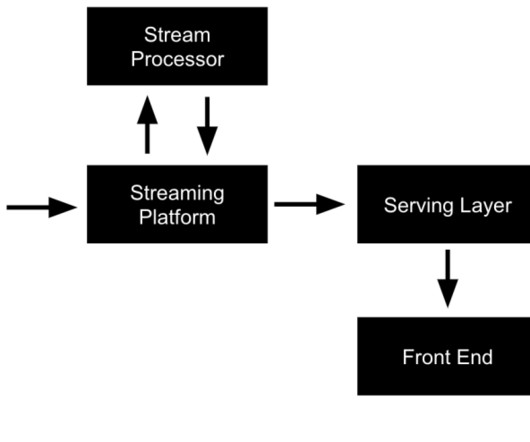
Streaming platform — Acts as the source of truth for event data and must therefore handle high volume and concurrency of data being produced and consumed. Stream processor — Reads events from the streaming dataplatform and then takes some action on that event. Front end — The thing that end users interact with.
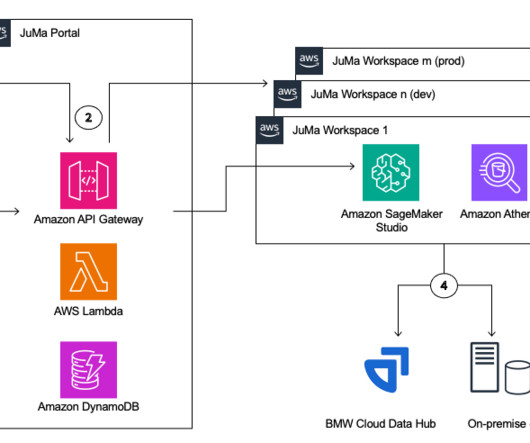
JuMa is a service of BMW Group’s AI platform for its data analysts, ML engineers, and data scientists that provides a user-friendly workspace with an integrated development environment (IDE). It is powered by Amazon SageMaker Studio and provides JupyterLab for Python and Posit Workbench for R.
The results of SUEWS are then visualized, in this case with Arup’s existing geospatial dataplatform. The GPU-powered interactive visualizer and Python notebooks provide a seamless way to explore millions of data points in a single window as well as collaborate on the insights and results.
Machine Learning AI Frameworks for Software Engineering Scikit-learn Scikit-learn is a popular open-source machine learning library in Python. It provides a range of supervised and unsupervised learning algorithms, along with tools for model fitting, data preprocessing, and evaluation.
Secure, Seamless, and Scalable ML Data Preparation and Experimentation Now DataRobot and Snowflake customers can maximize their return on investment in AI and their cloud dataplatform. You can seamlessly and securely connect to Snowflake with support for External OAuth authentication in addition to basic authentication.
Technical requirements for a Data Scientist High expertise in programming either in R or Python, or both. Familiarity with Databases; SQL for structured data, and NOSQL for unstructured data. Experience with cloud platforms like; AWS, AZURE, etc. Knowledge of big dataplatforms like; Hadoop and Apache Spark.
You may also like Building a Machine Learning Platform [Definitive Guide] Consideration for dataplatform Setting up the DataPlatform in the right way is key to the success of an ML Platform. In the following sections, we will discuss best practices while setting up a DataPlatform for Retail.
Industry, Opinion, Career Advice What Dagster Believes About DataPlatforms The beliefs that organizations adopt about the way their dataplatforms should function influence their outcomes. Enables Data Science Teams to Influence Mission-Critical Decisions Here, the author shares her thoughts on how Dash Enterprise 5.2
Describe a situation where you had to think creatively to solve a data-related challenge. I encountered a data quality issue where inconsistent data formats affected the analysis. Programming and Scripting Questions Which programming languages are you proficient in for data analysis? 10% group discount available.
Professionals can connect to various data sources, including databases, spreadsheets, and big dataplatforms. This helps in understanding the underlying patterns, trends, and relationships within the data. Tableau also supports advanced statistical modeling through integration with statistical tools like R and Python.
Snowflake is the preferred dataplatform, and it receives data from Step Functions state machine runs through Amazon CloudWatch logs. A series of filters screen for data pertinent to the business. The processing code is primarily written in Python using libraries that are periodically updated.
Dagster Supports end-to-end data management lifecycle. Its software-defined assets (announced through Rebundling the DataPlatform ) and built-in lineage make it an appealing tool for developers. Seamless integration with many data sources and destinations. Uses secure protocols for data security.
Here we provide a Python function that performs a POST call to our bookingapp. About the Author/AI Builders Summit Speaker on AI Agent Implementation: Valentina is a Data Science MSc graduate and Cloud Specialist at Microsoft, focusing on Analytics and AI workloads within the manufacturing and pharmaceutical industry since 2022.
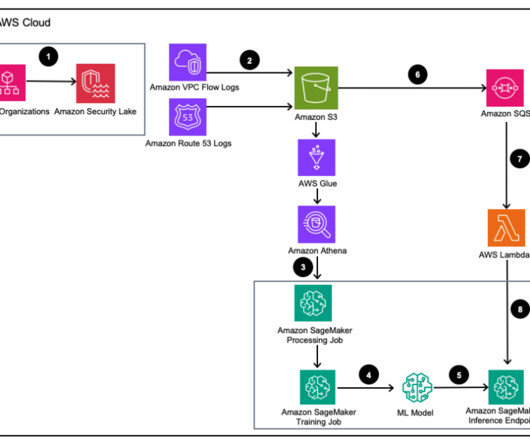
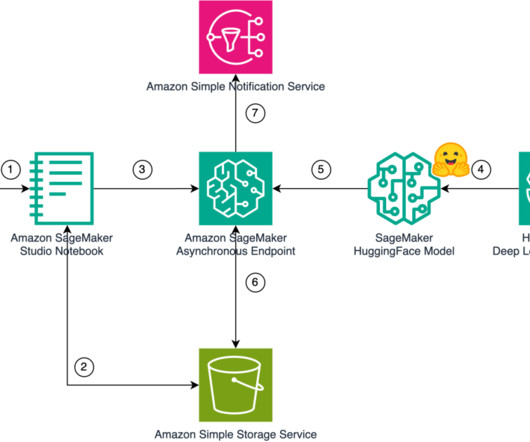
For Runtime , choose Python 3.10. Over the years, he has helped multiple customers on dataplatform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. The SAM template requires you provide the SQS ARN and the SageMaker endpoint name.
You’ll use MLRun, Langchain, and Milvus for this exercise and cover topics like the integration of AI/ML applications, leveraging Python SDKs, as well as building, testing, and tuning your work. In this session, we’ll demonstrate how you can fine-tune a Gen AI model, build a Gen AI application, and deploy it in 20 minutes.
Stefan is a software engineer, data scientist, and has been doing work as an ML engineer. He also ran the dataplatform in his previous company and is also co-creator of open-source framework, Hamilton. You could almost think of Hamilton as DBT for Python functions. It gives a very opinionary way of writing Python.
Implementing robust data validation processes. Clinical Research Acceleration Speeds up research processes and drug development Integrating diverse data sources. Implementing interoperable dataplatforms. 6,20000 Analytical skills, proficiency in Data Analysis tools (e.g., 12,00000 Programming (e.g.,
Arjuna Chala, associate vice president, HPCC Systems For those not familiar with the HPCC Systems data lake platform, can you describe your organization and the development history behind HPCC Systems? They were interested in creating a dataplatform capable of managing a sizable number of datasets.
Data Estate: This element represents the organizational data estate, potential data sources, and targets for a data science project. Data Engineers would be the primary owners of this element of the MLOps v2 lifecycle. The Azure dataplatforms in this diagram are neither exhaustive nor prescriptive.
She is passionate about helping customers innovate with Big Data and Artificial Intelligence technologies to tap business value and insights from data. She has experience in working on dataplatform and AI/ML projects in the healthcare and life sciences vertical.
Job Submission and Cluster Management: To take advantage of Hadoop, you generally use the Hadoop API to generate code in Java, Python, or other compatible languages. Aside from cluster management, responsibilities like data integration and data quality control can be difficult for organisations that use Hadoop systems.
If you are interested in learning more about MM-RAG and how to build multimodal applications with Python and AI orchestrators, join our upcoming talk at ODSC East 2024 ! In other words, it will enable more effective communication between AI systems and humans.
I actually did not pick up Python until about a year before I made the transition to a data scientist role. You see them all the time with a headline like: “data science, machine learning, Java, Python, SQL, or blockchain, computer vision.” The only decorator that comes to my mind is a Python decorator.
Allen Downey, PhD, Principal Data Scientist at PyMCLabs Allen is the author of several booksincluding Think Python, Think Bayes, and Probably Overthinking Itand a blog about data science and Bayesian statistics. in Ecology, he brings a unique perspective to statistics, spatial analysis, and real-world data applications.
FeatureByte empowers data science professionals by simplifying the whole process in feature engineering. With an intuitive Python SDK, it enables quick feature creation and extraction from XLarge Event and Item Tables. Notebooks facilitate experimentation, while feature sharing and reuse save time.
The model package contains a requirements.txt file that lists the necessary Python packages to be installed to serve the MusicGen model. He specializes in building dataplatforms and architecting seamless data ecosystems. The model package also contains an inference.py
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content