This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It became apparent to both Razi and me that we had the opportunity to make a significant impact by radically simplifying the feature engineering process and providing data scientists and MLengineers with the right tools and user experience for seamless feature experimentation and feature serving.
Deployment times stretched for months and required a team of three system engineers and four MLengineers to keep everything running smoothly. With just one part-time MLengineer for support, our average issue backlog with the vendor is practically non-existent.
Integrating model deployment into the service development process was a key initiative to enable data scientists and MLengineers to deploy and maintain those models. The MLplatform empowers the building and evolution of ML systems.
Data scientists search and pull features from the central feature store catalog, build models through experiments, and select the best model for promotion. Data scientists create and share new features into the central feature store catalog for reuse.
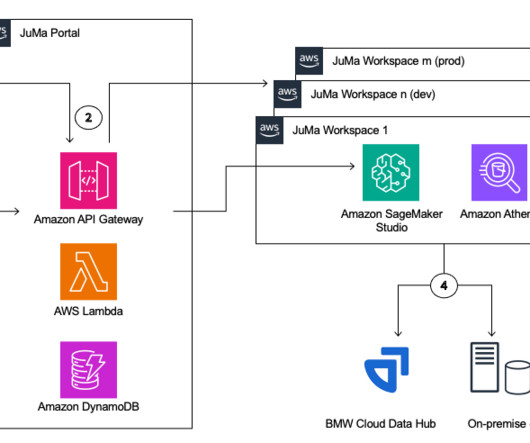
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and MLengineers require capable tooling and sufficient compute for their work. JuMa is now available to all data scientists, MLengineers, and data analysts at BMW Group.
Abi Aryan, Founder at AbideAI Abi is a seasoned MLengineer and author of LLMOps. Shes currently writing her second book on GPU engineering and scaling AI infrastructure.
How to Add Domain-Specific Knowledge to an LLM Based on Your Data In this article, we will explore one of several strategies and techniques to infuse domain knowledge into LLMs, allowing them to perform at their best within specific professional contexts by adding chunks of documentation into an LLM as context when injecting the query.
Axfood has a structure with multiple decentralized data science teams with different areas of responsibility. Together with a central dataplatform team, the data science teams bring innovation and digital transformation through AI and ML solutions to the organization.
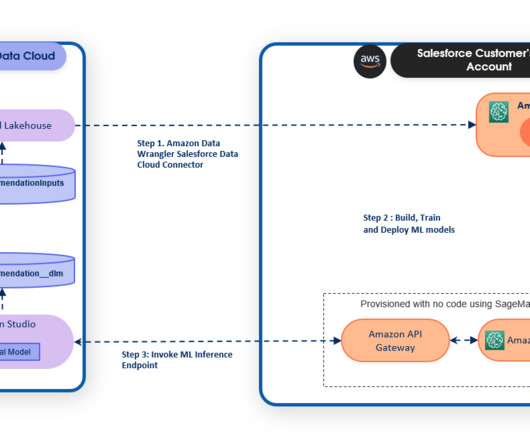
As a result, businesses can accelerate time to market while maintaining data integrity and security, and reduce the operational burden of moving data from one location to another. With Einstein Studio, a gateway to AI tools on the dataplatform, admins and data scientists can effortlessly create models with a few clicks or using code.
We’ll see how this architecture applies to different classes of ML systems, discuss MLOps and testing aspects, and look at some example implementations. Understanding machine learning pipelines Machine learning (ML) pipelines are a key component of ML systems. But what is an ML pipeline? What is a feature store?
In fact, 96 percent of all AI/ML unicorns—and 90 percent of the 2024 Forbes AI 50—are AWS customers. We’re empowering data scientists, MLengineers, and other builders with new capabilities that make generative AI development faster, easier, more secure, and less costly.
Machine Learning Operations (MLOps) can significantly accelerate how data scientists and MLengineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and MLengineers to build and deploy models at scale.
Snorkel AI wrapped the second day of our The Future of Data-Centric AI virtual conference by showcasing how Snorkel’s data-centric platform has enabled customers to succeed, taking a deep look at Snorkel Flow’s capabilities, and announcing two new solutions.
Snorkel AI wrapped the second day of our The Future of Data-Centric AI virtual conference by showcasing how Snorkel’s data-centric platform has enabled customers to succeed, taking a deep look at Snorkel Flow’s capabilities, and announcing two new solutions.
The data scientists will start with experimentation, and then once they find some insights and the experiment is successful, then they hand over the baton to dataengineers and MLengineers that help them put these models into production. And so that’s where we got started as a cloud data warehouse.
The data scientists will start with experimentation, and then once they find some insights and the experiment is successful, then they hand over the baton to dataengineers and MLengineers that help them put these models into production. And so that’s where we got started as a cloud data warehouse.
Stefan is a software engineer, data scientist, and has been doing work as an MLengineer. He also ran the dataplatform in his previous company and is also co-creator of open-source framework, Hamilton. As you’ve been running the MLdataplatform team, how do you do that?
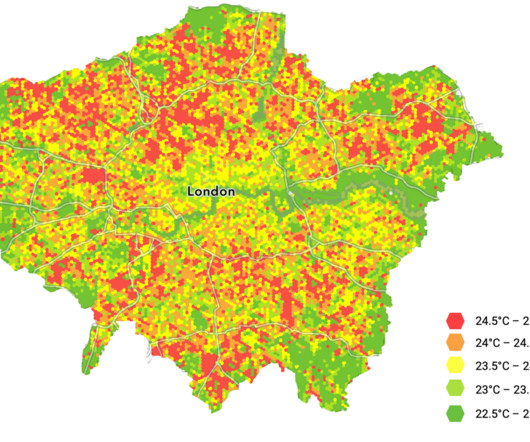
SageMaker geospatial capabilities make it easy for data scientists and machine learning (ML) engineers to build, train, and deploy models using geospatial data. The results of SUEWS are then visualized, in this case with Arup’s existing geospatial dataplatform.
I see so many of these job seekers, especially on the MLOps side or the MLengineer side. You see them all the time with a headline like: “data science, machine learning, Java, Python, SQL, or blockchain, computer vision.” They were kind of close to an MLengineering role, but not really. It’s two things.
His mission is to enable customers achieve their business goals and create value with data and AI. He helps architect solutions across AI/ML applications, enterprise dataplatforms, data governance, and unified search in enterprises.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content