This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataplatform architecture has an interesting history. A read-optimized platform that can integrate data from multiple applications emerged. In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different dataplatform solution.
When building machine learning (ML) models using preexisting datasets, experts in the field must first familiarize themselves with the data, decipher its structure, and determine which subset to use as features. So much so that a basic barrier, the great range of data formats, is slowing advancement in ML.
Solution overview By combining the powerful vector search capabilities of OpenSearch Service with the access control features provided by Amazon Cognito , this solution enables organizations to manage access controls based on custom user attributes and document metadata. If you don’t already have an AWS account, you can create one.
A data lakehouse architecture combines the performance of data warehouses with the flexibility of data lakes, to address the challenges of today’s complex data landscape and scale AI. New insights and relationships are found in this combination. All of this supports the use of AI.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. foundation models to help users discover, augment, and enrich data with natural language. IBM watsonx.ai Later this year, it will leverage watsonx.ai
This includes watermarking, content moderation, and C2PA support (available in Amazon Nova Canvas) to add metadata by default to generated images. Amazon Nova Canvas and Amazon Nova Reel come with controls to support safety, security, and IP needs with responsible AI.
And eCommerce companies have a ton of use cases where ML can help. The problem is, with more ML models and systems in production, you need to set up more infrastructure to reliably manage everything. And because of that, many companies decide to centralize this effort in an internal MLplatform. But how to build it?
Open is creating a foundation for storing, managing, integrating and accessing data built on open and interoperable capabilities that span hybrid cloud deployments, data storage, data formats, query engines, governance and metadata.
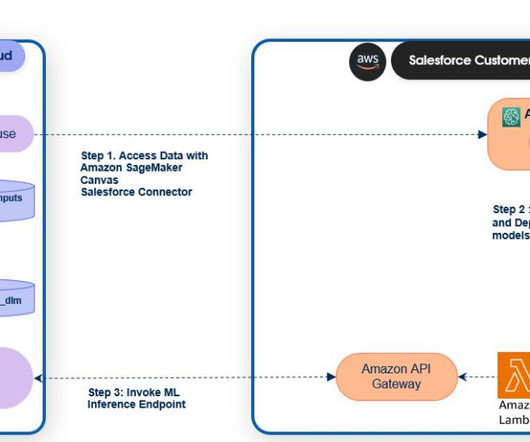
If you are a returning user to SageMaker Studio, in order to ensure Salesforce Data Cloud is enabled, upgrade to the latest Jupyter and SageMaker Data Wrangler kernels. This completes the setup to enable data access from Salesforce Data Cloud to SageMaker Studio to build AI and machine learning (ML) models.
Luckily, we have tried and trusted tools and architectural patterns that provide a blueprint for reliable ML systems. In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. But what is an ML pipeline?
Why model-driven AI falls short of delivering value Teams that just focus model performance using model-centric and data-centric ML risk missing the big picture business context. DataRobot AI Platform Delivers on Value-Driven AI In our new 9.0 What Do AI Teams Need to Realize Value from AI?
A document is a collection of information that consists of a title, the content (or the body), metadata (data about the document), and access control list (ACL) information to make sure answers are provided from documents that the user has access to. These field mappings allow you to map Box field names to Amazon Q index field names.
Combining accurate transcripts with Genesys CTR files, Principal could properly identify the speakers, categorize the calls into groups, analyze agent performance, identify upsell opportunities, and conduct additional machine learning (ML)-powered analytics.
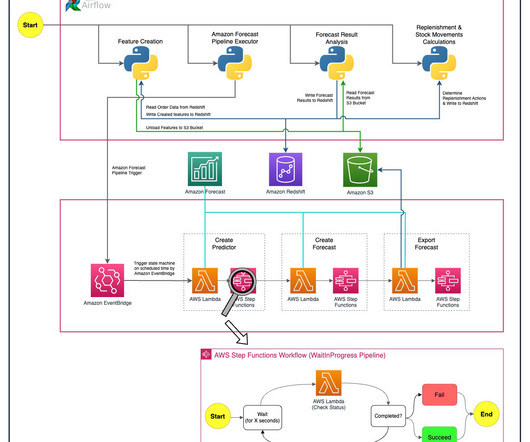
Getir used Amazon Forecast , a fully managed service that uses machine learning (ML) algorithms to deliver highly accurate time series forecasts, to increase revenue by four percent and reduce waste cost by 50 percent. Deep/neural network algorithms also perform very well on sparse data set and in cold-start (new item introduction) scenarios.
This article was originally an episode of the MLPlatform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with MLplatform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best MLplatform professionals.
This article was originally an episode of the MLPlatform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with MLplatform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best MLplatform professionals.
The examples focus on questions on chunk-wise business knowledge while ignoring irrelevant metadata that might be contained in a chunk. He has touched on most aspects of these projects, from infrastructure and DevOps to software development and AI/ML. Rahul Jani is a Data Architect with AWS Professional Service.
Uber runs one of the most sophisticated data and machine learning(ML) infrastructures in the planet. It’s Michelangelo platform has been used as the reference architecture for many MLOps platforms over the last few years. Uber innvoations in ML and data span across all categories of the stack.
This data source may be related to the sales sector, the manufacturing industry, finance, health, and R&D… Briefly, I am talking about a field-specific data source. The domain of the data. Regardless, the data fabric must be consistent for all its components. Data fabric needs metadata management maturity.
Machine Learning Integration Opportunities Organizations harness machine learning (ML) algorithms to make forecasts on the data. ML models, in turn, require significant volumes of adequate data to ensure accuracy. Moreover, each experiment must be supported with copies of entire data sets. Superior data protection.
Media Analytics, where we analyze all the broadcast content, as well as live content, that we’re distributing to extract additional metadata from this data and make it available to other systems to create new interactive experiences, or for further insights into how customers are using our streaming services.
Media Analytics, where we analyze all the broadcast content, as well as live content, that we’re distributing to extract additional metadata from this data and make it available to other systems to create new interactive experiences, or for further insights into how customers are using our streaming services.
Cloud-based data storage solutions, such as Amazon S3 (Simple Storage Service) and Google Cloud Storage, provide highly durable and scalable repositories for storing large volumes of data. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and ML engineers to build and deploy models at scale.
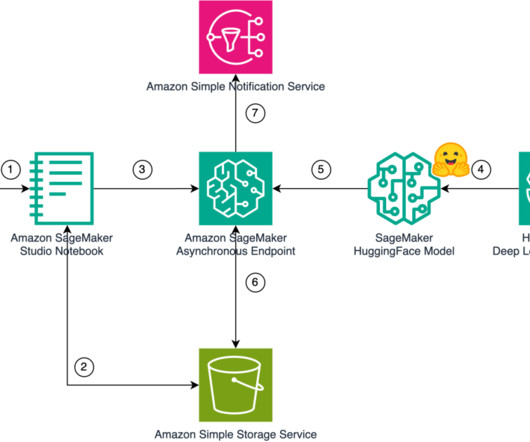
Asynchronous music generation As soon as the response metadata is sent to the client, the asynchronous inference begins the music generation. He is specialized in architecting AI/ML and generative AI services at AWS. He specializes in building dataplatforms and architecting seamless data ecosystems.
These are subject-specific subsets of the data warehouse, catering to the specific needs of departments like marketing or sales. They offer a focused selection of data, allowing for faster analysis tailored to departmental goals. Metadata This acts like the data dictionary, providing crucial information about the data itself.
SageMaker endpoints can be registered to the Salesforce Data Cloud to activate predictions in Salesforce. SageMaker Canvas provides a no-code experience to access data from Salesforce Data Cloud and build, test, and deploy models using just a few clicks. Einstein Studio is a gateway to AI tools on Salesforce Data Cloud.
It’s often described as a way to simply increase data access, but the transition is about far more than that. When effectively implemented, a data democracy simplifies the data stack, eliminates data gatekeepers, and makes the company’s comprehensive dataplatform easily accessible by different teams via a user-friendly dashboard.
The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context. Solution overview The solution integrates with your existing data catalogs and repositories, creating a unified, scalable semantic layer across the entire data landscape.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content