This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Though building applications and choosing different Large Language Models has become easier, the data uploading part, where the data comes from various sources is still time-consuming for developers while developing LLM-powered applications as the developers […] The post Introduction to Embedchain – A DataPlatform Tailored for LLMs appeared (..)
Developing this data for AI usage is often overlooked — but it is one of the most powerful ways to build an AI moat. If you are interested in accelerating the data backbone of your AI strategy with Snorkel’s Foundation Model DataPlatform, please connect with our team here. Footnotes (1) Brants et al.
Developing this data for AI usage is often overlooked — but it is one of the most powerful ways to build an AI moat. If you are interested in accelerating the data backbone of your AI strategy with Snorkel’s Foundation Model DataPlatform, please connect with our team here. Footnotes (1) Brants et al.
Prompt injections are a type of attack where hackers disguise malicious content as benign user input and feed it to an LLM application. The hacker’s prompt is written to override the LLM’s system instructions, turning the app into the attacker’s tool. Breaking down how the remoteli.io For example, the remoteli.io
Proprietary LLMs are owned by a company and can only be used by customers that purchase a license. The license may restrict how the LLM can be used. On the other hand, open source LLMs are free and available for anyone to access, use for any purpose, modify and distribute. What are the benefits of open source LLMs?
During TechXchange , IBM’s premier technical learning event in Las Vegas last week, IBM Partner Plus members including our Strategic Partners, resellers, software vendors, distributors and service partners showed up in full force, joining us on stage to share how they are embracing watsonx , our enterprise-ready AI and dataplatform.
When framed in the context of the Intelligent Economy RAG flows are enabling access to information in ways that facilitate the human experience, saving time by automating and filtering data and information output that would otherwise require significant manual effort and time to be created.
Thankfully, retrieval-augmented generation (RAG) has emerged as a promising solution to ground large language models (LLMs) on the most accurate, up-to-date information. IBM unveiled its new AI and dataplatform, watsonx™, which offers RAG, back in May 2023.
In the year since we unveiled IBM’s enterprise generative AI (gen AI) and dataplatform, we’ve collaborated with numerous software companies to embed IBM watsonx™ into their apps, offerings and solutions. IBM’s established expertise and industry trust make it an ideal integration partner.”
Cloudera got its start in the Big Data era and is now moving quickly into the era of Big AI with large language models (LLMs). Today, Cloudera announced its strategy and tools for helping enterprises integrate the power of LLMs and generative AI into the company’s Cloudera DataPlatform (CDP). …
Pre-filtered documents that relate to the user query are included in the prompt of the large language model (LLM) that summarizes the answer. Then, Lambda replies back to the web interface with the LLM completion (reply). He helps customers and partners build big dataplatform and generative AI applications.
Used alongside other techniques such as prompt engineering, RAG, and contextual grounding checks, Automated Reasoning checks add a more rigorous and verifiable approach to enhancing the accuracy of LLM-generated outputs. Amazon Bedrock Evaluations addresses this by helping you evaluate, compare, and select the best FMs for your use case.
IBM watsonx Assistant connects to watsonx, IBM’s enterprise-ready AI and dataplatform for training, deploying and managing foundation models, to enable business users to automate accurate, conversational question-answering with customized watsonx large language models.
An AI and dataplatform, such as watsonx, can help empower businesses to leverage foundation models and accelerate the pace of generative AI adoption across their organization. The latest open-source LLM model we added this month includes Meta’s 70 billion parameter model Llama 2-chat inside the watsonx.ai
This approach makes sure that the LLM operates within specified ethical and legal parameters, much like how a constitution governs a nations laws and actions. client(service_name="bedrock-runtime", region_name="us-east-1") llm = ChatBedrock(client=bedrock_runtime, model_id="anthropic.claude-3-haiku-20240307-v1:0") .
In todays fast-paced AI landscape, seamless integration between dataplatforms and AI development tools is critical. At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform.
Dozens of NVIDIA dataplatform partners are working with NeMo Retriever NIM microservices to boost their AI models’ accuracy and throughput. NetApp is collaborating with NVIDIA to connect NeMo Retriever microservices to exabytes of data on its intelligent data infrastructure.
This allows the Masters to scale analytics and AI wherever their data resides, through open formats and integration with existing databases and tools. “Hole distances and pin positions vary from round to round and year to year; these factors are important as we stage the data.”
To scale ground truth generation and curation, you can apply a risk-based approach in conjunction with a prompt-based strategy using LLMs. Its important to note that LLM-generated ground truth isnt a substitute for use case SME involvement. To convert the source document excerpt into ground truth, we provide a base LLM prompt template.
Recommendation agent Analyzes the aggregated data to provide tailored recommendations for precise input applications, product placement, and strategies for pest and disease control. This experience was instrumental in her professional growth.
Airflow provides the workflow management capabilities that are integral to modern cloud-native dataplatforms. Dataplatform architects leverage Airflow to automate the movement and processing of data through and across diverse systems, managing complex data flows and providing flexible scheduling, monitoring, and alerting.
Just last month, Salesforce made a major acquisition to power its Agentforce platform—just one in a number of recent investments in unstructured data management providers. “Most data being generated every day is unstructured and presents the biggest new opportunity.”
Index is multimodal : Supports multimodal AI, managing data in the form of images, videos, audio, text, documents and more. Index is not limited to a single form of data like many LLM tools today. As AI applications grow in complexity, the need for efficient and scalable data management solutions will only increase.
A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. The platform comprises three powerful products: The watsonx.ai
Cost-effective – The solution should only invoke LLM to generate reusable code on an as-needed basis instead of manipulating the data directly to be as cost-effective as possible. If yes, the solution retrieves and executes the previously-generated python codes (Step 2) and the transformed data is stored in S3 (Step 10).
John Snow Labs’ Medical Language Models library is an excellent choice for leveraging the power of large language models (LLM) and natural language processing (NLP) in Azure Fabric due to its seamless integration, scalability, and state-of-the-art accuracy on medical tasks.
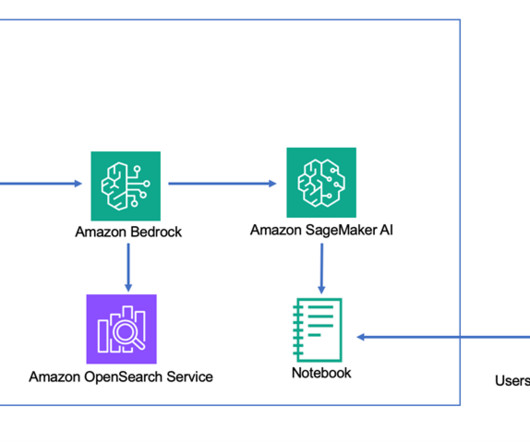
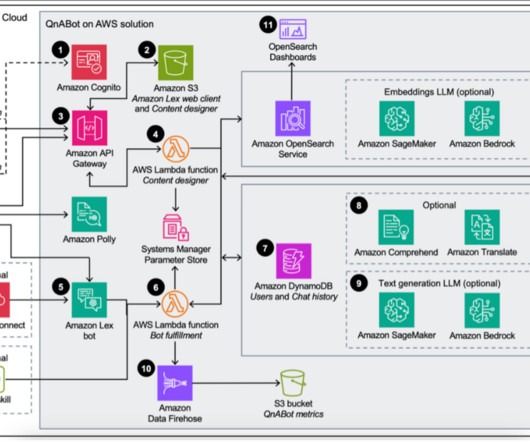
If using text embeddings , these requests first pass through a LLM model hosted on Amazon Bedrock or Amazon SageMaker to generate embeddings before being saved into the question bank on OpenSearch Service. The text generation LLM can optionally be used to create the search query and synthesize a response from the returned document excerpts.
While these large language model (LLM) technologies might seem like it sometimes, it’s important to understand that they are not the thinking machines promised by science fiction. Achieving these feats is accomplished through a combination of sophisticated algorithms, natural language processing (NLP) and computer science principles.
We demonstrate BYO LLM integration by using Anthropic’s Claude model on Amazon Bedrock to summarize a list of open service cases and opportunities on an account record page, as shown in the following figure. Solution overview With the Salesforce Einstein Model Builder BYO LLM feature, you can invoke Amazon Bedrock models in your AWS account.
With the recent launch of watsonx, IBM’s next-generation AI and dataplatform, AI is being taken to the next level with three powerful components: watsonx.ai, watsonx.data and watsonx.governance. The LLM solution has resulted in an 80% reduction in manual effort and in 90% accuracy of automated tasks. Watsonx.ai
How to Add Domain-Specific Knowledge to an LLM Based on Your Data In this article, we will explore one of several strategies and techniques to infuse domain knowledge into LLMs, allowing them to perform at their best within specific professional contexts by adding chunks of documentation into an LLM as context when injecting the query.
Search-R1 In the paper "Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning" researchers from the University of Illinois at Urbana-Champaign introduce SEARCH-R1, a novel reinforcement learning framework that enables large language models to interleave self-reasoning with real-time search engine interactions.
RAG is a methodology to improve the accuracy of LLM responses answering a user query by retrieving and inserting relevant domain knowledge into the language model prompt. Tuning chunking and indexing in the retriever makes sure the correct content is available in the LLM prompt for generation.
In todays fast-paced AI landscape, seamless integration between dataplatforms and AI development tools is critical. At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform.
EICopilot is an LLM-based chatbot that utilizes a novel data preprocessing pipeline that optimizes database queries. They obtained data from Baidus internal dataplatform and processed it rigorously to construct a dataset involving a query and graph database query pair.
We discuss Google Research’s paper about REALM, the original retrieval-augmented foundation model and the new version of the Ray platform that includes support for LLMs. Edge 302: We deep dive into MPT-7B, an open source LLM that supports 65k tokens. Training dataplatform Refuel AI announced $5 million in new funding.
With the advent of Generative AI and Large Language Models (LLMs), we witnessed a paradigm shift in Application development, paving the way for a new wave of LLM-powered applications. Furthermore, the system message can also shape the planning pattern, specifying the way the LLM should decide upon the available tools.
Industry, Opinion, Career Advice What Dagster Believes About DataPlatforms The beliefs that organizations adopt about the way their dataplatforms should function influence their outcomes. Enables Data Science Teams to Influence Mission-Critical Decisions Here, the author shares her thoughts on how Dash Enterprise 5.2
TL;DR LLMOps involves managing the entire lifecycle of Large Language Models (LLMs), including data and prompt management, model fine-tuning and evaluation, pipeline orchestration, and LLM deployment. However, transforming raw LLMs into production-ready applications presents complex challenges.
Created Using Midjourney In case you missed yesterday’s newsletter due to July the 4th holiday, we discussed the universe of in-context retrieval augmented LLMs or techniques that allow to expand the LLM knowledge without altering its core architecutre. It’s a good one. Go check it out.
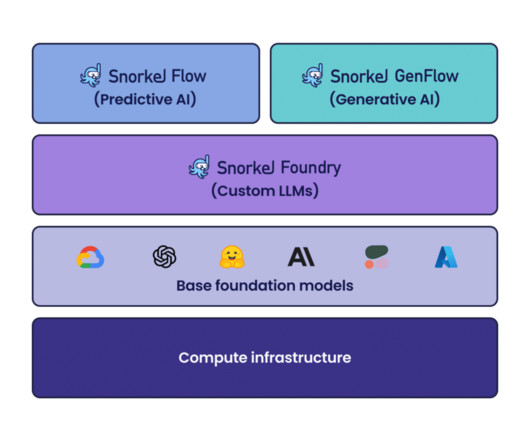
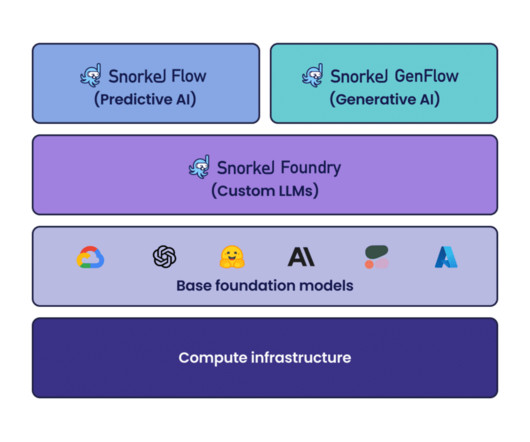
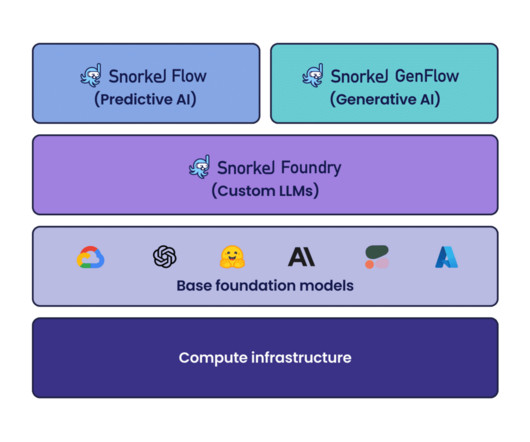
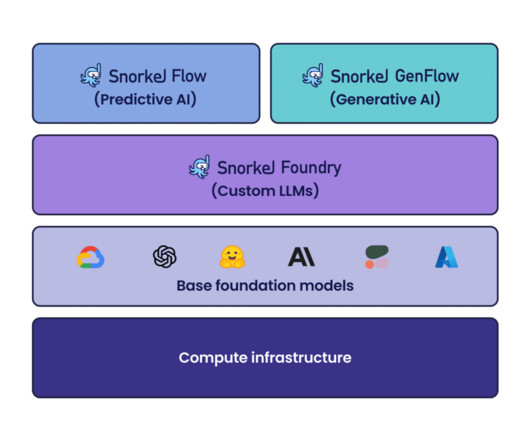
In addition to the latest release of Snorkel Flow, we recently introduced Foundation Model DataPlatform that expands programmatic data development beyond labeling for predictive AI with two core solutions: Snorkel GenFlow for building generative AI applications and Snorkel Foundry for developing custom LLMs with proprietary data.
In addition to the latest release of Snorkel Flow, we recently introduced Foundation Model DataPlatform that expands programmatic data development beyond labeling for predictive AI with two core solutions: Snorkel GenFlow for building generative AI applications and Snorkel Foundry for developing custom LLMs with proprietary data.
This is the result of a concentrated effort to deeply integrate its technology across a range of cloud and dataplatforms, making it easier for customers to adopt and leverage its technology in a private, safe, and scalable way.
Build and productionize LLM models with ease with Dagster Pedram Navid | Head of Data Engineering and Developer Relations | Elementl/Dagster Labs During this session, you’ll discuss the role of orchestration in LLM training and deployment and the importance of an asset-centric framework in data engineering.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content