This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
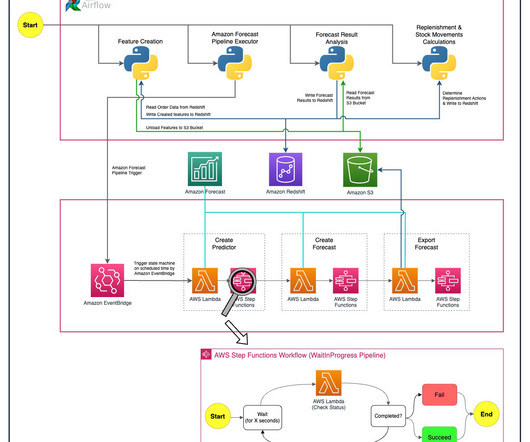
Dataplatform architecture has an interesting history. A read-optimized platform that can integrate data from multiple applications emerged. In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different dataplatform solution.
Solution overview By combining the powerful vector search capabilities of OpenSearch Service with the access control features provided by Amazon Cognito , this solution enables organizations to manage access controls based on custom user attributes and document metadata. For more information, see Getting started with the AWS CDK.
Database metadata can be expressed in various formats, including schema.org and DCAT. Unfortunately, these formats weren’t made with machine learning data in mind. Google has recently introduced Croissant, a new format for metadata in ML-ready datasets. Users can then publish their datasets.
Throughout my career, Ive been building and refining this unique combination of technical and business insights, which continues to inform my approach to innovation in the industry. Can you share the story behind the creation of the VDURA DataPlatform and the key challenges you aimed to address in the AI and HPC landscape?
Everyone would be using the same data set to make informed decisions which may range from goal setting to prioritizing investments in sustainability. Data fabric can help model, integrate and query data sources, build data pipelines, integrate data in near real-time, and run AI-driven applications.
Year after year, IBM Consulting works with the United States Tennis Association (USTA) to transform massive amounts of data into meaningful insight for tennis fans. This year, the USTA is using watsonx , IBM’s new AI and dataplatform for business.
Automated Reasoning checks help prevent factual errors from hallucinations using sound mathematical, logic-based algorithmic verification and reasoning processes to verify the information generated by a model, so outputs align with provided facts and arent based on hallucinated or inconsistent data.
Donahue: At the enterprise or company level, “good” data is clean, structured and enriched. This preprocessing pipeline should minimize information loss between the original content and the LLM-ready version. You may ask, “What does that have to do with unstructured data?”
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. While they require task-specific labeled data for fine tuning, they also offer clients the best cost performance trade-off for non-generative use cases.
Falling into the wrong hands can lead to the illicit use of this data. Hence, adopting a DataPlatform that assures complete data security and governance for an organization becomes paramount. In this blog, we are going to discuss more on What are Dataplatforms & Data Governance.
Data profiling is a crucial tool. For evaluating data quality. It entails analyzing, cleansing, transforming, and modeling data to find valuable information, improve data quality, and assist in better decision-making, What is Data Profiling?
Open is creating a foundation for storing, managing, integrating and accessing data built on open and interoperable capabilities that span hybrid cloud deployments, data storage, data formats, query engines, governance and metadata.
However, extracting meaningful information from the vast amount of Box data can be challenging without the right tools and capabilities. This enables you to quickly understand the main points and find relevant information in your documents without having to scan through individual document descriptions manually.
To ensure the highest quality measurement of your question answering application against ground truth, the evaluation metrics implementation must inform ground truth curation. By following these guidelines, data teams can implement high fidelity ground truth generation for question-answering use case evaluation with FMEval.
Content redaction: Each customer audio interaction is recorded as a stereo WAV file, but could potentially include sensitive information such as HIPAA-protected and personally identifiable information (PII). Scalability: This architecture needed to immediately scale to thousands of calls per day and millions of calls per year.
Among those algorithms, deep/neural networks are more suitable for e-commerce forecasting problems as they accept item metadata features, forward-looking features for campaign and marketing activities, and – most importantly – related time series features. We are able to forecast over 10,000 SKUs daily in all the countries we serve.
A feature store is a dataplatform that supports the creation and use of feature data throughout the lifecycle of an ML model, from creating features that can be reused across many models to model training to model inference (making predictions). It can also transform incoming data on the fly. What is a feature store?
The Architecture The D3 architecture comprises several core systems managed by Uber's DataPlatform, which play a crucial role in maintaining data quality. Databook provides valuable insights into datasets, including column information, lineage, data quality tests, metrics, SLAs, data consistency, duplicates, and more.
Data lake foundations This module helps data lake admins set up a data lake to ingest data, curate datasets, and use the AWS Lake Formation governance model for managing fine-grained data access across accounts and users using a centralized data catalog, data access policies, and tag-based access controls.
Data should have an independent team responsible for its creation, delivery, and sustainability. This team should consist of experts who know the business domain where the data comes from and should be something other than general-purpose Information and Communication Technologies (ICT) teams. The domain of the data.
Media Analytics, where we analyze all the broadcast content, as well as live content, that we’re distributing to extract additional metadata from this data and make it available to other systems to create new interactive experiences, or for further insights into how customers are using our streaming services.
Media Analytics, where we analyze all the broadcast content, as well as live content, that we’re distributing to extract additional metadata from this data and make it available to other systems to create new interactive experiences, or for further insights into how customers are using our streaming services.
Today, companies are facing a continual need to store tremendous volumes of data. The demand for information repositories enabling business intelligence and analytics is growing exponentially, giving birth to cloud solutions. The tool’s high storage capacity is perfect for keeping large information volumes.
The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation. For more information, refer to Creating roles and attaching policies (console). Creating the dataset may take some time.
Retrieval Augmented Generation (RAG) enables LLMs to extract and synthesize information like an advanced search engine. Tools range from dataplatforms to vector databases, embedding providers, fine-tuning platforms, prompt engineering, evaluation tools, orchestration frameworks, observability platforms, and LLM API gateways.
However, it was inflexible and could not handle many-to-many relationships or complex relationships between data, which limited its use in more complex applications. Hierarchical databases, such as IBM’s Information Management System (IMS), were widely used in early mainframe database management systems.
Stefan is a software engineer, data scientist, and has been doing work as an ML engineer. He also ran the dataplatform in his previous company and is also co-creator of open-source framework, Hamilton. As you’ve been running the ML dataplatform team, how do you do that? Stefan: Yeah. Thanks for having me.
There’s no component that stores metadata about this feature store? Mikiko Bazeley: In the case of the literal feature store, all it does is store features and metadata. We’re assuming that data scientists, for the most part, don’t want to write transformations elsewhere. Mikiko Bazeley: 100%. Do you need Airflow?
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. You need to build your ML platform with experimentation and general workflow reproducibility in mind.
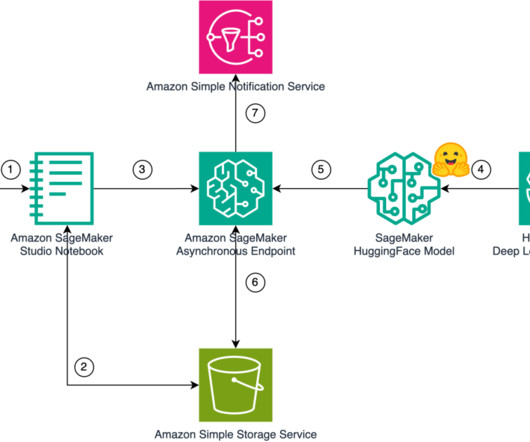
Dependent workflows can poll these topics to make informed decisions based on the inference outcomes. Asynchronous music generation As soon as the response metadata is sent to the client, the asynchronous inference begins the music generation. He specializes in building dataplatforms and architecting seamless data ecosystems.
Summary: A data warehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, data warehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. The table metadata is managed by Data Catalog. This is a SageMaker Lakehouse managed catalog backed by RMS storage.
It’s often described as a way to simply increase data access, but the transition is about far more than that. When effectively implemented, a data democracy simplifies the data stack, eliminates data gatekeepers, and makes the company’s comprehensive dataplatform easily accessible by different teams via a user-friendly dashboard.
Customers want to search through all of the data and applications across their organization, and they want to see the provenance information for all of the documents retrieved. The application needs to search through the catalog and show the metadatainformation related to all of the data assets that are relevant to the search context.
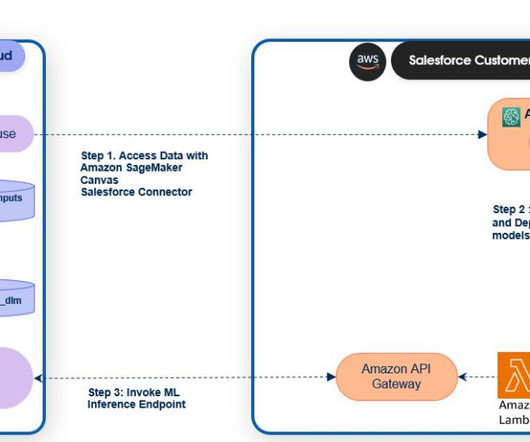
Salesforce Data Cloud and Einstein Studio Salesforce Data Cloud is a dataplatform that provides businesses with real-time updates of their customer data from any touch point. Einstein Studio is a gateway to AI tools on Salesforce Data Cloud. Salesforce adds a “__c “ to all the Data Cloud object fields.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content