This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataplatform architecture has an interesting history. A read-optimized platform that can integrate data from multiple applications emerged. In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different dataplatform solution.
Customer DataPlatforms (CDPs) play an increasingly important role in the enterprise marketing landscape. By bringing together data from a wide variety of.
Amperity was identified in Snowflake’s report as a leader in the Customer Data Activation category for data activation solutions, such as customer dataplatforms, customer engagement platforms, reverse ETL providers, and others, which are designed to make the activation process faster and easier.
Data is the differentiator as business leaders look to utilize their competitive edge as they implement generative AI (gen AI). Leaders feel the pressure to infuse their processes with artificial intelligence (AI) and are looking for ways to harness the insights in their dataplatforms to fuel this movement.
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
Extract, Transform, and Load are referred to as ETL. ETL is the process of gathering data from numerous sources, standardizing it, and then transferring it to a central database, data lake, data warehouse, or data store for additional analysis. Involved in each step of the end-to-end ETL process are: 1.
HT: When companies rely on managing data in a customer dataplatform (CDP) in tandem with AI, they can create strong, personalised campaigns that reach and inspire their customers. AN: What other emerging AI trends should people be keeping an eye on? Here are four trends in AI personalisation.
Data Engineerings SteadyGrowth 20182021: Data engineering was often mentioned but overshadowed by modeling advancements. 20222024: As AI models required larger and cleaner datasets, interest in data pipelines, ETL frameworks, and real-time data processing surged.
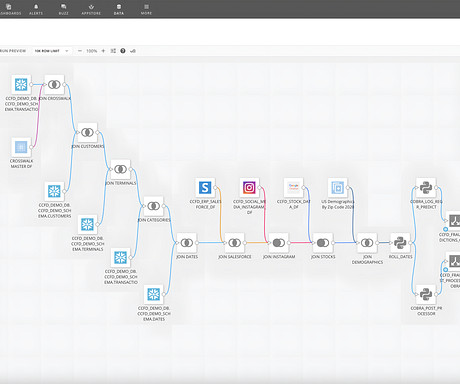
To start, get to know some key terms from the demo: Snowflake: The centralized source of truth for our initial data Magic ETL: Domo’s tool for combining and preparing data tables ERP: A supplemental data source from Salesforce Geographic: A supplemental data source (i.e., Instagram) used in the demo Why Snowflake?
Composable, packaged, unbundled, traditional, reverse ETL, zero copy – these are just a few of the terms used to describe customer dataplatforms (CDPs) today. If you find that understanding the CDP marketspace is a bit like trying to discern meaning from a word salad (defined by Merriam-Webster as “a [.]
The solution consists of the following components: Data ingestion: Data is ingested into the data account from on-premises and external sources. Data access: Refined data is registered in the data accounts AWS Glue Data Catalog and exposed to other accounts via Lake Formation.
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized data engineers understood, resulting in an under-realized positive impact on the business.
Flexible Structure: Big Data systems can manage unstructured, semi-structured, and structured data without enforcing a strict structure, in contrast to data warehouses that adhere to structured schemas. When to use each?
Your data strategy should incorporate databases designed with open and integrated components, allowing for seamless unification and access to data for advanced analytics and AI applications within a dataplatform. With an open data lakehouse, you can access a single copy of data wherever your data resides.
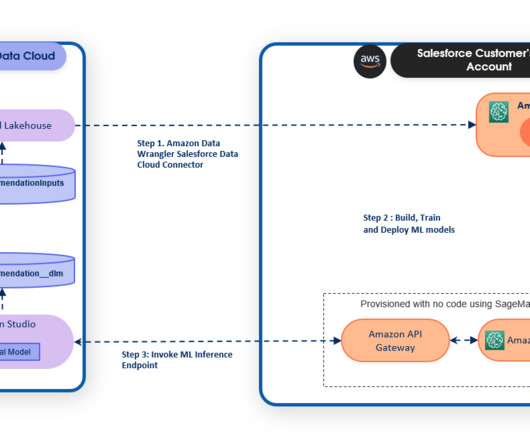
As a result, businesses can accelerate time to market while maintaining data integrity and security, and reduce the operational burden of moving data from one location to another. With Einstein Studio, a gateway to AI tools on the dataplatform, admins and data scientists can effortlessly create models with a few clicks or using code.
LLMs excel at writing code and reasoning over text, but tend to not perform as well when interacting directly with time-series data. Gabriel also has expertise in industrial dataplatforms, predictive maintenance, and combining AI/ML with industrial workloads.
Businesses that require assistance with managing or personalizing procedures related to huge data quality can use the company’s range of professional services and support offerings. Collibra Data Intelligence Platform Launched in 2008, Collibra offers corporate users data intelligence capabilities.
The next generation of Db2 Warehouse SaaS and Netezza SaaS on AWS fully support open formats such as Parquet and Iceberg table format, enabling the seamless combination and sharing of data in watsonx.data without the need for duplication or additional ETL.
Dagster Supports end-to-end data management lifecycle. Its software-defined assets (announced through Rebundling the DataPlatform ) and built-in lineage make it an appealing tool for developers. Seamless integration with many data sources and destinations. Uses secure protocols for data security.
In the realm of data management and analytics, businesses face a myriad of options to store, manage, and utilize their data effectively. Understanding their differences, advantages, and ideal use cases is crucial for making informed decisions about your data strategy. Cons: Costly: Can be expensive to implement and maintain.
About the authors Samantha Stuart is a Data Scientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements. Rahul Jani is a Data Architect with AWS Professional Service. When hes not at work, youre likely to find Philippe outdoorseither rock climbing or going for a run.
It supports real-time data processing and has built-in security protocols to ensure data integrity. Some common use cases for Apache Nifi include streaming data from IoT devices, ingesting data into big dataplatforms, and transferring data between cloud environments.
Whether you aim for comprehensive data integration or impactful visual insights, this comparison will clarify the best fit for your goals. Key Takeaways Microsoft Fabric is a full-scale dataplatform, while Power BI focuses on visualising insights. Fabric suits large enterprises; Power BI fits team-level reporting needs.
IBM merged the critical capabilities of the vendor into its more contemporary Watson Studio running on the IBM Cloud Pak for Dataplatform as it continues to innovate. The platform makes collaborative data science better for corporate users and simplifies predictive analytics for professional data scientists.
Keeping track of how exactly the incoming data (the feature pipeline’s input) has to be transformed and ensuring that each model receives the features precisely how it saw them during training is one of the hardest parts of architecting ML systems. This is where feature stores come in. What is a feature store?
Data Warehousing and ETL Processes What is a data warehouse, and why is it important? A data warehouse is a centralised repository that consolidates data from various sources for reporting and analysis. It is essential to provide a unified data view and enable business intelligence and analytics.
You may also like Building a Machine Learning Platform [Definitive Guide] Consideration for dataplatform Setting up the DataPlatform in the right way is key to the success of an ML Platform. In the following sections, we will discuss best practices while setting up a DataPlatform for Retail.
Arjuna Chala, associate vice president, HPCC Systems For those not familiar with the HPCC Systems data lake platform, can you describe your organization and the development history behind HPCC Systems? They were interested in creating a dataplatform capable of managing a sizable number of datasets.
Cloud-based data storage solutions, such as Amazon S3 (Simple Storage Service) and Google Cloud Storage, provide highly durable and scalable repositories for storing large volumes of data. It’s optimized with performance features like indexing, and customers have seen ETL workloads execute up to 48x faster. Morgan Kaufmann.
About the Authors Samantha Stuart is a Data Scientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements. Rahul Jani is a Data Architect with AWS Professional Services. Beyond work, he values quality time with family and embraces opportunities for travel.
Stefan is a software engineer, data scientist, and has been doing work as an ML engineer. He also ran the dataplatform in his previous company and is also co-creator of open-source framework, Hamilton. As you’ve been running the ML dataplatform team, how do you do that? Stefan: Yeah. Thanks for having me.
The Data Lake Admin has an AWS Identity and Access Management (IAM) admin role and is a Lake Formation administrator responsible for managing user permissions to catalog objects using Lake Formation. The Data Warehouse Admin has an IAM admin role and manages databases in Amazon Redshift.
Uber’s prowess as a transportation, logistics and analytics company hinges on their ability to leverage data effectively. The pursuit of hyperscale analytics The scale of Uber’s analytical endeavor requires careful selection of dataplatforms with high regard for limitless analytical processing.
Let’s delve into the key components that form the backbone of a data warehouse: Source Systems These are the operational databases, CRM systems, and other applications that generate the raw data feeding the data warehouse. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
Data Foundation on AWS Amazon S3: Scalable storage foundation for data lakes. AWS Lake Formation: Simplify the process of creating and managing a secure data lake. Amazon Redshift: Fast, scalable data warehouse for analytics. AWS Glue: Fully managed ETL service for easy data preparation and integration.
Data Foundation on AWS Amazon S3: Scalable storage foundation for data lakes. AWS Lake Formation: Simplify the process of creating and managing a secure data lake. Amazon Redshift: Fast, scalable data warehouse for analytics. AWS Glue: Fully managed ETL service for easy data preparation and integration.
It’s often described as a way to simply increase data access, but the transition is about far more than that. When effectively implemented, a data democracy simplifies the data stack, eliminates data gatekeepers, and makes the company’s comprehensive dataplatform easily accessible by different teams via a user-friendly dashboard.
His mission is to enable customers achieve their business goals and create value with data and AI. He helps architect solutions across AI/ML applications, enterprise dataplatforms, data governance, and unified search in enterprises.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content