This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Typically, on their own, data warehouses can be restricted by high storage costs that limit AI and ML model collaboration and deployments, while data lakes can result in low-performing datascience workloads. New insights and relationships are found in this combination. All of this supports the use of AI.
But what has been clear is that there is an urgent need to modernize these deployments and protect the investment in infrastructure, skills and data held in those systems. In a search for answers, the industry looked at existing dataplatform technologies and their strengths. Comprehensive data security and data governance (i.e.
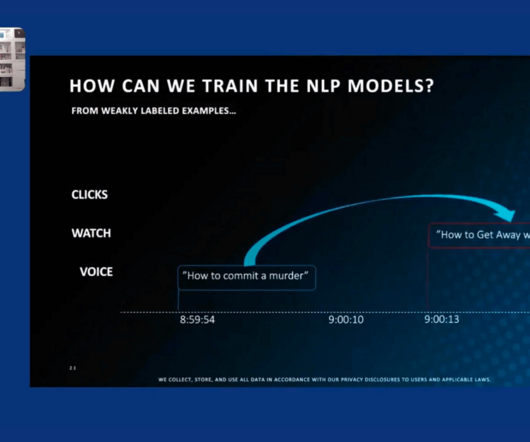
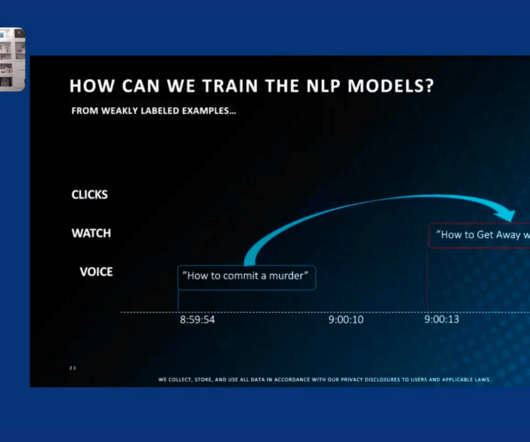
. “Most data being generated every day is unstructured and presents the biggest new opportunity.” ” We wanted to learn more about what unstructured data has in store for AI. Donahue: We’re beginning to see datascience and machine learning engineering teams work more closely with data engineering teams.
By supporting open-source frameworks and tools for code-based, automated and visual datascience capabilities — all in a secure, trusted studio environment — we’re already seeing excitement from companies ready to use both foundation models and machine learning to accomplish key tasks.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and datascience use cases. Perform data quality monitoring based on pre-configured rules.
Data lake foundations This module helps data lake admins set up a data lake to ingest data, curate datasets, and use the AWS Lake Formation governance model for managing fine-grained data access across accounts and users using a centralized data catalog, data access policies, and tag-based access controls.
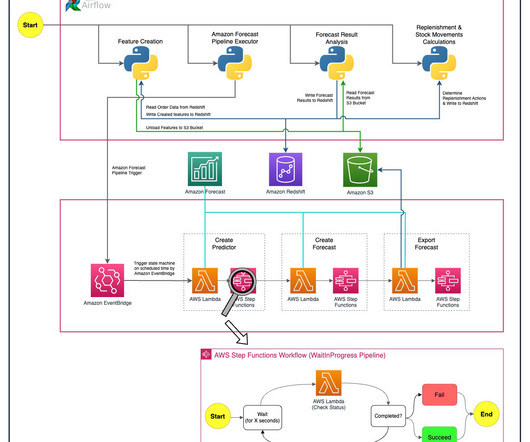
Solution overview Six people from Getir’s datascience team and infrastructure team worked together on this project. Deep/neural network algorithms also perform very well on sparse data set and in cold-start (new item introduction) scenarios. The following diagram shows the solution’s architecture.
The examples focus on questions on chunk-wise business knowledge while ignoring irrelevant metadata that might be contained in a chunk. He collaborates closely with enterprise customers building modern dataplatforms, generative AI applications, and MLOps. You can customize the prompt examples to fit your ground truth use case.
This data source may be related to the sales sector, the manufacturing industry, finance, health, and R&D… Briefly, I am talking about a field-specific data source. The domain of the data. Regardless, the data fabric must be consistent for all its components. Data fabric needs metadata management maturity.
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. You need to build your ML platform with experimentation and general workflow reproducibility in mind.
Media Analytics, where we analyze all the broadcast content, as well as live content, that we’re distributing to extract additional metadata from this data and make it available to other systems to create new interactive experiences, or for further insights into how customers are using our streaming services.
Media Analytics, where we analyze all the broadcast content, as well as live content, that we’re distributing to extract additional metadata from this data and make it available to other systems to create new interactive experiences, or for further insights into how customers are using our streaming services.
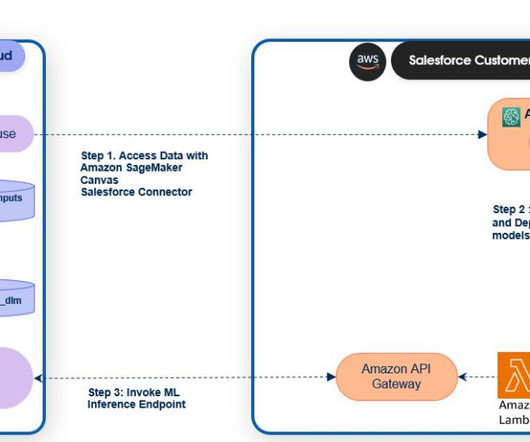
SageMaker Canvas SageMaker Canvas enables business analysts and datascience teams to build and use ML and generative AI models without having to write a single line of code. Einstein Studio is a gateway to AI tools on Salesforce Data Cloud. Salesforce adds a “__c “ to all the Data Cloud object fields.
These are subject-specific subsets of the data warehouse, catering to the specific needs of departments like marketing or sales. They offer a focused selection of data, allowing for faster analysis tailored to departmental goals. Metadata This acts like the data dictionary, providing crucial information about the data itself.
You will see an Amazon Simple Storage Service (Amazon S3) link to a metadata file. To discover the schema to be used while invoking the API from Einstein Studio, choose Information in the navigation pane of the Model Registry. Copy and paste the link into a new browser tab URL. Let’s look at the file without downloading it.
Furthermore, a shared-data approach stems from this efficient combination. The background for the Snowflake architecture is metadata management, so customers can enjoy an additional opportunity to share cloud data among users or accounts. Superior data protection.
So I was able to get from growth hacking to data analytics, then data analytics to datascience, and then datascience to MLOps. I switched from analytics to datascience, then to machine learning, then to data engineering, then to MLOps. I did the same thing with the ML platform role.
Stefan is a software engineer, data scientist, and has been doing work as an ML engineer. He also ran the dataplatform in his previous company and is also co-creator of open-source framework, Hamilton. As you’ve been running the ML dataplatform team, how do you do that? Stefan: Yeah. Thanks for having me.
Cloud-based data storage solutions, such as Amazon S3 (Simple Storage Service) and Google Cloud Storage, provide highly durable and scalable repositories for storing large volumes of data. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Morgan Kaufmann.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content